AWS Application Modernization: From Monolith to Microservices & Serverless
The complete technical guide to modernizing legacy applications on AWS — when to decompose a monolith, how to go serverless, which patterns to use, and how to do it without stopping product development.


Every SaaS company, fintech, healthtech, and digital business eventually reaches the same inflection point. The application that powered growth from $0 to $5M ARR becomes the thing slowing growth from $5M to $20M.
The symptoms are consistent: engineers take three weeks to ship a feature that should take three days. A bug in the payments module affects the entire platform. Scaling for a traffic spike means scaling every part of the application simultaneously, even the parts getting no extra load. The database is a single point of failure and everyone knows it. New engineers take months to understand the codebase well enough to contribute safely.
This is the monolith ceiling — and almost every successful software company hits it. The question is not whether to modernize, but when, how fast, and in what sequence.
AWS provides the infrastructure primitives to execute every modernization pattern: containers on ECS and EKS, serverless on Lambda and Fargate, event-driven architectures on SQS, SNS and EventBridge, managed databases in Aurora and DynamoDB, and API management through API Gateway. The technology is mature. The challenge is the strategy and the execution discipline.
TL;DR
- Strangler Fig is the safest path – incrementally extract services from the monolith while shipping product. Never more than 20% of engineering capacity on migration.
- 3 modernization options: Modular monolith (small teams) → Strangler Fig (most mid-stage companies) → Full rewrite (highest risk, avoid unless necessary).
- Start with ECS Fargate for containers (no cluster management). Move to EKS only if you need Kubernetes ecosystem.
- Lambda for event-driven & bursty workloads – not for long-running (>15 min), persistent connections, or sustained high throughput.
- Enforce database-per-service absolutely – never share databases across services. Use Outbox for reliable events, Saga for distributed transactions.
- Observability is non-negotiable – distributed tracing, structured logs, correlation IDs. Without it, microservices are unmanageable.
- ROI: 3-5× faster deployments, 40-60% lower infrastructure costs within 12 months. Payback in 18-24 months.
1. Diagnosing Your Monolith: Is Modernization Actually the Answer?
Modernization is expensive, disruptive, and long. Before committing, confirm that the monolith — not something else — is genuinely the constraint. Many engineering teams blame their architecture when the real problems are insufficient testing, unclear ownership, or inadequate deployment automation.
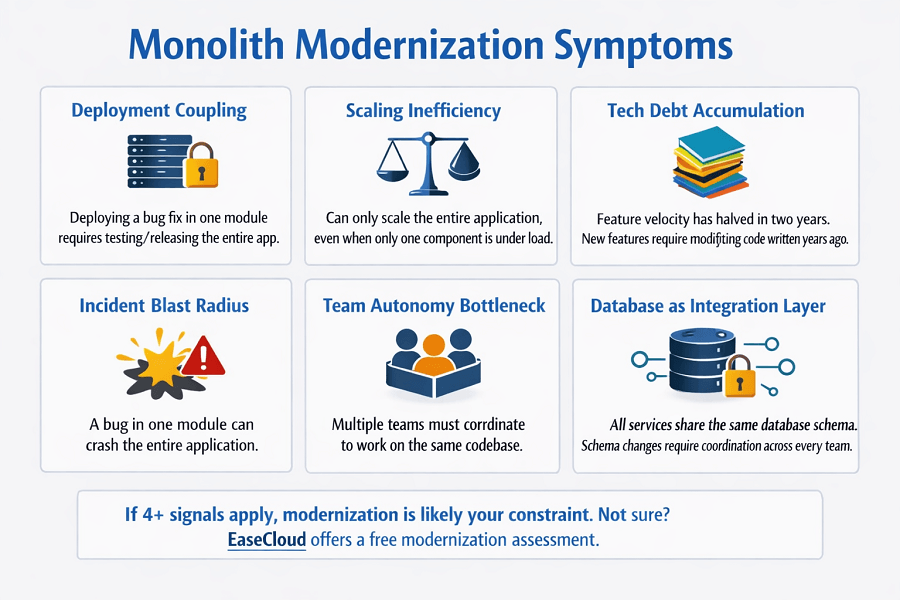
The monolith problem checklist
A monolith that should be modernized shows multiple of these signals simultaneously:
| Signal | What It Looks Like in Practice |
| Deployment coupling | Deploying a bug fix in one module requires testing and releasing the entire application. Teams queue behind each other for deployment slots. |
| Scaling inefficiency | You can only scale the entire application, even when only one component is under load. Cost at scale is disproportionate to actual demand. |
| Tech debt accumulation | Adding new features requires understanding and modifying code that was written years ago by people no longer at the company. Feature velocity has halved in two years. |
| Incident blast radius | A bug in one module can crash the entire application. Failure is not isolated. |
| Team autonomy bottleneck | Multiple teams must coordinate to work on the same codebase. Conway's Law in action: the architecture reflects the org chart of five years ago. |
| Database as integration layer | All services share the same database schema. A schema change requires coordination across every team. The database is both a technical and organizational bottleneck. |
| Language / framework lock-in | The team is constrained to a single language and framework for all new development, even when a different tool would be dramatically more appropriate. |
When NOT to modernize
Modernization is not always the answer. There are legitimate cases to maintain a monolith:
- Team size is small (under 8–10 engineers): the coordination overhead of microservices exceeds the benefit. A well-structured modular monolith is the right answer at this scale.
- Product-market fit is not yet established: modernizing while the product is still pivoting means you are decomposing a moving target. Reach stability first.
- Deployment problems are the real issue: if you deploy once a quarter because of poor CI/CD, a microservices architecture will make that problem worse, not better. Fix deployment first.
- The monolith is simply old, not painful: a monolith that ships features quickly, scales adequately, and has low incident rates is not broken. Do not fix what is not broken.
| ℹ | EaseCloud always starts modernization engagements with a thorough assessment of whether decomposition is actually the constraint. In roughly 20% of cases, the recommendation is to improve CI/CD, testing, and module boundaries within the monolith rather than decompose it. This saves significant engineering investment and delivers results faster. |
2. The Modernization Spectrum: Five Options Between 'Do Nothing' and 'Full Rewrite'
Application modernization is not binary. There is a full spectrum of approaches between keeping the monolith exactly as it is and doing a complete rewrite. Choosing the right point on the spectrum for your situation is the most consequential decision in a modernization initiative.
| Modernization Option | Risk / Effort Profile | When to Use It |
| Option 1: Modular Monolith | Lowest risk / effort | Refactor internal structure without changing deployment model. Clear module boundaries, enforced internal APIs, reduced coupling. Stay deployed as a single unit. Best for: teams under 10 engineers, early-stage products, monoliths that are 'messy' but not painful to operate. |
| Option 2: Strangler Fig Decomposition | Low-medium risk | Incrementally extract services from the monolith over 12–24 months. New functionality built as standalone services. Old functionality migrated piece by piece. Monolith shrinks as services take over. Best for: most mid-stage companies. Safest path to microservices. |
| Option 3: Domain-Driven Decomposition | Medium risk / effort | Identify bounded contexts using Domain-Driven Design, then extract each context as a service with its own data store. More structured than Strangler Fig. Requires significant upfront domain analysis. Best for: complex domains with clear business boundaries. |
| Option 4: Selective Serverless Migration | Medium risk | Migrate specific, well-defined workloads to Lambda (event processing, async jobs, scheduled tasks) while keeping core application intact. Targeted; does not require full decomposition. Best for: teams that want serverless benefits in specific areas without broader modernization risk. |
| Option 5: Full Rewrite | Highest risk / effort | Design from scratch on modern architecture. Only justified when: the monolith's technical debt is so severe that incremental improvement is not possible, the business model has fundamentally changed, or the team has the runway and engineering capacity for 12–18 months of parallel development. |
| ⚠ | The full rewrite is the highest-risk option in software engineering. Companies that have chosen this path include Netscape (product died), HealthCare.gov (launch disaster), and countless startups that ran out of runway before the rewrite shipped. Choose it only when the alternatives are genuinely not viable. |
3. The Strangler Fig Pattern: The Safest Path to Microservices
The Strangler Fig pattern — named after a vine that gradually grows around and replaces its host tree — is the most widely proven approach to incrementally decomposing a monolith without stopping product delivery.
Martin Fowler coined the term. AWS officially endorses it as the recommended migration pattern. EaseCloud uses it on every monolith decomposition engagement. The reason it works is simple: at no point does the old system need to be switched off before the new one is ready.
How the Strangler Fig works
- A routing layer (API Gateway, Application Load Balancer, or a Facade service) sits in front of the monolith and intercepts all incoming requests
- New functionality is built as standalone microservices behind the routing layer — never added to the monolith
- Existing functionality is migrated out of the monolith one bounded context at a time — each migration is tested, validated, and deployed independently
- The routing layer routes requests to the new microservice once it is production-validated, bypassing the monolith for that functionality
- The monolith code for the migrated functionality is deleted — the monolith gradually shrinks
- Repeat until the monolith is empty — at which point it is decommissioned
Strangler Fig on AWS: the technical implementation
| Component | AWS Implementation |
| Routing Layer | Amazon API Gateway (for HTTP/REST) or Application Load Balancer with path-based routing rules. Routes requests to either the legacy monolith or new microservices based on path, header, or feature flag. |
| Service Hosting | New microservices deployed on ECS Fargate (simplest operational model) or EKS (if Kubernetes expertise exists). Each service has its own ECR repository, ECS service, and deployment pipeline. |
| Data Decoupling | Each extracted service gets its own database — Aurora PostgreSQL, Aurora MySQL, or DynamoDB depending on data model. Eliminates shared database coupling progressively. |
| Event-Driven Integration | SQS and SNS decouple the monolith from new services during transition. The monolith publishes events to SNS; new services subscribe. This allows asynchronous integration without tight coupling. |
| Feature Flag Control | AWS AppConfig or LaunchDarkly manages which users/percentage receive new service vs. monolith. Enables gradual rollout, A/B testing, and instant rollback without deployment. |
| Service Discovery | AWS Cloud Map or ECS Service Discovery for inter-service communication. Services find each other by DNS name without hardcoded endpoints. |
What to extract first: prioritization framework
Not all bounded contexts are equal candidates for early extraction. Use these four criteria to sequence your Strangler Fig migration:
| Bounded Context Characteristic | Extraction Priority & Rationale |
| High business value, low coupling | Extract first. These are the services that will deliver the most team velocity improvement with the least migration risk. Often: user authentication, notification services, reporting. |
| High coupling, complex data model | Extract last. These are the hardest migrations. Shared database tables, circular dependencies, and complex data migrations. Leave until you have experience with simpler extractions. |
| New functionality | Never build in the monolith again. Every new feature goes into a new service from this point forward. This starts demonstrating value immediately without any migration risk. |
| Scaling bottleneck | Extract on business-driven timeline. If payments processing is your scaling constraint, it warrants early extraction even if technically complex — the operational risk of leaving it in the monolith exceeds the migration risk. |
| ★ | EaseCloud's rule: never migrate more than one bounded context per sprint. The migration itself is a background workstream. Product velocity must not drop during modernization. If the team is spending more than 20% of capacity on migration work, the pace is too aggressive. |
4. Designing Microservices on AWS: Architecture Patterns That Work
Microservices architecture is frequently oversimplified as 'split your monolith into small services.' The reality is more nuanced. A poorly designed microservices architecture is significantly harder to operate than the monolith it replaced — more failure modes, more network complexity, more observability challenges, and more operational overhead.
The design patterns in this section are the ones that make microservices architecture manageable at startup and SMB scale.
4.1 Service boundaries: Domain-Driven Design on AWS
The most important decision in microservices design is where to draw service boundaries. Boundaries drawn at the wrong level produce either nano-services (too many, too granular, chatty) or macro-services (too few, still coupled, defeating the purpose).
Domain-Driven Design (DDD) provides the framework. Identify Bounded Contexts — areas of the domain that have distinct meaning, data models, and business rules. Each Bounded Context becomes a candidate for a microservice.
| Bounded Context | Extraction Notes |
| User Identity & Auth | Authentication, authorization, user profiles, sessions. Self-contained domain; well-understood boundaries. Extract early. |
| Product / Catalog | Product data, pricing, inventory. Usually low-coupling to other domains. Good early extraction candidate. |
| Order Management | Order creation, status, fulfillment. High business value. Moderate coupling to Payments and Inventory. |
| Payments & Billing | Payment processing, subscription management, invoicing. High sensitivity — extract carefully with extensive testing. |
| Notifications | Email, SMS, push notifications. Naturally event-driven. Extract with SQS/SNS decoupling. Very clean boundaries. |
| Analytics & Reporting | Data aggregation, reporting, dashboards. Often read-heavy. Good candidate for CQRS pattern with separate read model. |
| Search | Full-text search, recommendations. Extract to dedicated service (OpenSearch/Elasticsearch). Separate scaling profile justifies extraction. |
4.2 Inter-service communication patterns
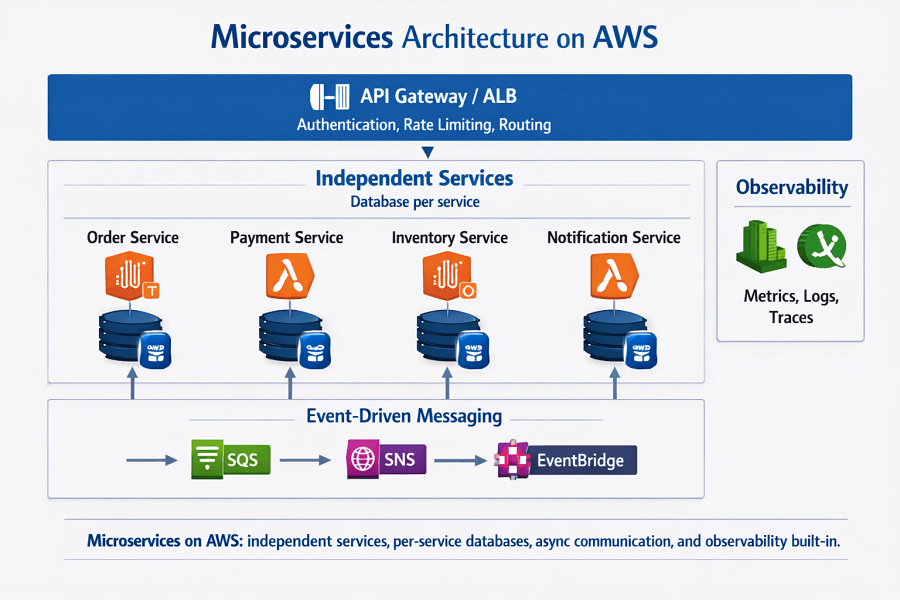
How microservices communicate with each other is as important as how they are structured. Two primary patterns — synchronous and asynchronous — with specific AWS implementations:
| Communication Pattern | Use Case & Guidance | |
| REST / HTTP (Synchronous) | When to use | Real-time queries where the caller needs an immediate response. User-facing API calls, data reads, simple request/response workflows. |
| gRPC (Synchronous) | When to use | High-throughput, low-latency inter-service calls. Better than REST for internal service communication where you control both sides. Requires Protocol Buffer schema definitions. |
| Amazon SQS (Async, Queue) | When to use | Work distribution that needs guaranteed delivery and processing. Order processing, email sending, data transformation. Messages persist until consumed. |
| Amazon SNS (Async, Fan-Out) | When to use | One event that multiple services need to know about. 'Order placed' published to SNS; inventory, fulfillment, and notification services all subscribe and react independently. |
| Amazon EventBridge (Async, Event Bus) | When to use | Complex event routing with filtering, transformation, and archive/replay. Decouples event producers from consumers. Supports third-party SaaS integrations as event sources. |
| AWS Step Functions (Orchestration) | When to use | Long-running workflows with multiple steps, conditional logic, error handling, and retry. Payment flow, onboarding workflows, multi-step data processing. |
4.3 The API Gateway pattern on AWS
In a microservices architecture, clients should not call individual services directly. An API Gateway provides a single entry point that handles cross-cutting concerns:
- Authentication and authorization — verify JWT tokens before requests reach services
- Rate limiting and throttling — protect services from traffic spikes and abuse
- Request routing — route to the correct service based on path, method, and headers
- Response aggregation — for mobile clients, combine multiple service calls into a single response
- SSL termination — centralized TLS management rather than per-service certificate management
- API versioning — route v1 and v2 clients to different service versions simultaneously
AWS implementation: Amazon API Gateway (HTTP API for low-latency, REST API for advanced features) combined with AWS Lambda authorizers or Amazon Cognito for authentication. Application Load Balancer is an alternative for simpler routing without the API management features.
4.4 Data management in microservices
The hardest part of microservices is not the services themselves — it is the data. Moving from a shared monolithic database to per-service databases requires new patterns for data consistency and cross-service queries.
| Data Pattern | What It Solves & AWS Implementation |
| Database per service | Each microservice owns its own database. No service reads another service's database directly. The foundational rule that enables independent deployment and scaling. Implement with RDS, Aurora, or DynamoDB per service. |
| Event sourcing | Store state changes as a sequence of events rather than current state. Events are immutable and can be replayed. Provides audit trail, temporal queries, and decoupled integration. Implement with DynamoDB Streams or EventBridge Pipes. |
| CQRS | Command Query Responsibility Segregation: separate write model (normalized, transactional) from read model (denormalized, optimized for queries). Resolves the tension between transactional integrity and query performance. Implement with DynamoDB for writes, OpenSearch or Redshift for reads. |
| Saga pattern | Manages distributed transactions across services. Instead of a distributed ACID transaction (which doesn't work across services), a saga is a sequence of local transactions each publishing events to trigger the next step, with compensating transactions for rollback. Implement with Step Functions or Choreography via EventBridge. |
| API composition | For cross-service queries, an API Gateway or dedicated Query service fetches data from multiple services and composes the response. Avoids direct database access between services while enabling rich response objects. |
| ⚠ | The most common microservices mistake: allowing services to call each other's databases directly 'just this once.' This recreates the coupling of the monolith at the data layer while adding network overhead. Enforce the database-per-service boundary absolutely from day one. |
5. Containerization on AWS: Docker, ECS, EKS, and Fargate
Containerization on AWS are the standard deployment unit for microservices. They provide consistent environments across development, staging, and production, fast startup times, and efficient resource utilization.
The key decision on AWS is not whether to containerize — that answer is almost always yes — but which orchestration platform to use.
ECS vs EKS: the real decision criteria
| Factor | ECS | EKS | Recommendation |
| Factor | ECS (Elastic Container Service) | EKS (Elastic Kubernetes Service) | Recommendation |
| Operational complexity | Low — AWS-native, fewer moving parts | High — Kubernetes expertise required | ECS for most startups and SMBs |
| Ecosystem & portability | AWS-specific, not portable | Kubernetes standard, portable to any cloud | EKS if multi-cloud portability matters |
| Learning curve | Days to get productive | Weeks to months for the full stack | ECS for teams new to containers |
| Cost | No control plane cost with Fargate | $0.10/hr per EKS cluster control plane | ECS slightly cheaper at small scale |
| Kubernetes ecosystem | Not applicable | Helm, Operators, Istio, KEDA available | EKS if you need this ecosystem |
| Service mesh | AWS App Mesh (simpler) | Istio, Linkerd, AWS App Mesh | ECS App Mesh vs EKS Istio based on need |
| Auto-scaling | ECS Service Auto Scaling, KEDA | HPA, KEDA, Cluster Autoscaler | Both support robust auto-scaling |
Fargate: serverless containers
AWS Fargate eliminates EC2 node management for both ECS and EKS. With Fargate, you define the container, specify CPU and memory, and AWS handles the underlying compute — no node groups to manage, patch, or right-size.
- Pay for exactly the vCPU and memory your container uses — no node idle capacity
- No OS patching, node scaling, or cluster node management
- Stronger security isolation than shared EC2 nodes — each Fargate task runs on its own kernel
- Slower cold start than EC2-backed tasks (~10–30 seconds vs ~5 seconds) — not suitable for latency-sensitive scaling events
- Higher per-unit cost than EC2 at sustained high utilization — break-even is typically around 40–50% average utilization
| ✓ | EaseCloud recommendation for most startups and SMBs: start with ECS Fargate. It eliminates cluster management overhead entirely, scales to zero, and is sufficient for the vast majority of microservices workloads up to significant scale. Adopt EKS when Kubernetes ecosystem dependencies (Helm operators, custom controllers, Istio) become necessary — not before. |
Container image best practices
- Use multi-stage Docker builds: build in a full SDK image, copy only artifacts to a minimal runtime image. Reduces image size by 60–80%.
- Base images: use official AWS base images (public.ecr.aws/lambda, public.ecr.aws/amazonlinux) or distroless images for minimal attack surface
- Never store secrets in Docker images. Use AWS Secrets Manager with ECS task role permissions to inject secrets at runtime
- Scan images with Amazon ECR image scanning (powered by Snyk) in CI/CD — block deployments with critical CVEs
- Tag images with Git commit SHA, not 'latest' — enables precise rollback to any previous deployment
6. Serverless on AWS: When Lambda Makes Sense — and When It Doesn't
Serverless is the most misunderstood term in cloud computing. It does not mean 'no servers' — it means you do not manage servers. AWS Lambda, the primary serverless compute service, executes your code in response to events and scales to zero when not in use.
Lambda is genuinely transformative for the right workloads. It is also genuinely unsuitable for others. The key is understanding which is which before making architectural commitments.
When Lambda is the right choice
| ✓ Lambda excels | Event-Driven Processing * S3 triggers: process uploaded files (image resizing, PDF parsing, data ingestion) automatically as they land * DynamoDB Streams: react to database changes without polling. Fan out changes to downstream systems * SQS / SNS triggered functions: process queued messages with automatic concurrency scaling * EventBridge rules: respond to scheduled events or cross-service events with zero idle cost * Kinesis Data Streams: real-time stream processing with configurable batch size and parallelism factor |
| ✓ Lambda excels | API Backends with Variable Traffic * Traffic that varies significantly by time of day, day of week, or seasonally — Lambda scales to zero in quiet periods * REST and GraphQL APIs via API Gateway + Lambda: pay per request, not per hour * Internal microservice endpoints with bursty, unpredictable invocation patterns * Webhook receivers: receive third-party webhooks (Stripe, Twilio, GitHub) without always-on infrastructure |
| ✓ Lambda excels | Scheduled and Background Tasks * Cron-style scheduled jobs: database cleanup, report generation, cache warming — via EventBridge Scheduler * Async email and notification sending triggered by application events * Data transformation pipelines: ETL between data stores with Lambda as the transformation layer * Periodic third-party API polling and data sync where polling frequency is low enough to be Lambda-efficient |
When Lambda is the wrong choice
| ✗ Lambda struggles | Long-Running Processes * Lambda maximum execution time is 15 minutes. Processes exceeding this are not suitable. * Long-running ML inference, video encoding, large file processing: use ECS Fargate or EC2 instead * Database migration scripts, large data exports, bulk processing jobs with unpredictable duration |
| ✗ Lambda struggles | WebSocket and Persistent Connection Workloads * Lambda is fundamentally stateless and ephemeral. Persistent connections are not natural to the model. * Real-time chat, collaborative editing, live dashboards: use ECS-hosted WebSocket servers or API Gateway WebSocket APIs (which add complexity) * Stateful session management: Lambda can do this with external state stores but it adds latency and complexity |
| ✗ Lambda struggles | High-Frequency, Low-Latency Sustained Traffic * At very high sustained request rates (thousands of RPS continuously), Lambda cost exceeds ECS cost * Cold start latency (50ms–1s depending on runtime and package size) is unacceptable for latency-sensitive hot paths * Lambda SnapStart (Java) and Graviton arm64 reduce cold starts but don't eliminate them |
Lambda cold start optimization
Cold starts occur when Lambda needs to initialize a new execution environment — provisioning the container, loading the runtime, and running initialization code. They add latency on top of function execution time. Mitigation strategies:
| Technique | How It Works & When to Use It |
| Provisioned Concurrency | Pre-warm a defined number of Lambda execution environments. Eliminates cold starts for those environments. Cost: you pay for the provisioned concurrency even when not invoked. Best for latency-critical functions. |
| Lambda SnapStart (Java) | Lambda saves a snapshot of initialized environment for Java functions. Restores from snapshot on cold start instead of reinitializing. Reduces Java cold starts from 1–4s to 100–200ms. |
| arm64 / Graviton | ARM-based Lambda functions initialize 10–20% faster than x86 due to architectural efficiency. Also 20% cheaper per GB-second. |
| Minimize package size | Lambda cold start time scales with package size. Use Lambda Layers for shared dependencies. Tree-shake production builds. Target under 5MB for sub-100ms cold starts. |
| Choose faster runtimes | Runtime cold start order (fastest to slowest): Go/Rust > Node.js > Python > Java/JVM. Choose the fastest runtime compatible with your stack. |
| Keep functions warm | EventBridge Scheduler pings low-traffic functions every 5 minutes to maintain warm execution environments. Not appropriate for all use cases but effective for critical low-traffic endpoints. |
Lambda cost at scale
Lambda pricing has two components: duration (GB-second) and requests ($0.20 per million). Understanding when Lambda becomes more expensive than ECS is essential for cost-aware architecture.
| Traffic Volume | Cost Guidance | Notes |
| < 1M requests/month | Lambda is almost certainly cheaper | Pay per request model favors low-volume workloads. Cost is negligible at low volume. |
| 1–50M requests/month | Lambda competitive; depends on duration | Model the actual cost. Short-duration functions (< 200ms) remain very cost-effective. Longer-duration functions start competing with ECS. |
| 50–200M requests/month | Lambda vs ECS cost comparison required | Run a cost model. Provisioned concurrency costs may make ECS Fargate comparable or cheaper, especially with Savings Plans. |
| > 200M requests/month | ECS often more cost-effective for sustained traffic | At high sustained RPS, always-on ECS containers with Savings Plans frequently beat Lambda on cost. Do the math before assuming Lambda scales cheaper. |
| ℹ | Cost at scale is not an argument against Lambda — it is an argument for modeling cost before committing. Lambda's operational simplicity (no cluster management, zero idle cost, automatic scaling) has real value that offsets some cost premium. Factor the engineering time saved, not just the infrastructure cost. |
Lambda for event-driven, bursty, async workloads. ECS for long-running, sustained traffic. We help you choose.
Lambda excels: event-driven processing (S3, DynamoDB Streams, SQS), API backends with variable traffic, scheduled tasks. Lambda struggles: long-running processes (>15 min), WebSocket/persistent connections, high-frequency sustained traffic (>200M requests/month).
We help you:
- Identify Lambda candidates – Event-driven, async, scheduled, or bursty workloads
- Optimize cold starts – Provisioned Concurrency, SnapStart (Java), Graviton (arm64), minimize package size
- Model Lambda vs ECS cost – Break-even analysis for your specific traffic patterns
- Build hybrid architectures – ECS for core microservices, Lambda for async processing
7. Event-Driven Architecture on AWS: SQS, SNS, and EventBridge
Event-driven architecture is the connective tissue of modern microservices. Instead of services calling each other synchronously (creating tight coupling), services emit events that other services react to asynchronously. This decouples producers from consumers and makes the system more resilient, scalable, and extensible.
The AWS event-driven toolkit
| Service | Pattern | When to Use It & Key Characteristics |
| Amazon SQS (Simple Queue Service) | Point-to-point queuing | One producer, one consumer group. Guaranteed delivery, at-least-once processing, configurable retention (up to 14 days). Two types: Standard (best-effort ordering, higher throughput) and FIFO (strict ordering, exactly-once, 3,000 msg/sec). Use for: work distribution, task queues, decoupled processing pipelines. |
| Amazon SNS (Simple Notification Service) | Fan-out pub/sub | One publisher, many subscribers. Publish a message once; SNS delivers to all subscribed endpoints (SQS, Lambda, HTTP, email, SMS). Use for: broadcasting events to multiple consumers, fan-out from monolith to microservices during migration, mobile push notifications. |
| Amazon EventBridge | Event bus with routing & schema | Enterprise event bus with content-based routing, event transformation, schema registry, and archive/replay. Supports SaaS integrations as event sources. Use for: complex event routing, cross-account event buses, audit-grade event archive, third-party SaaS event ingestion. |
| Amazon Kinesis Data Streams | Real-time streaming | High-throughput ordered streaming at scale. Multiple consumers can read independently with different positions. Data retention up to 365 days. Use for: clickstream analytics, log aggregation, real-time metrics, IoT data ingestion where ordering and replayability matter. |
| Amazon MQ (ActiveMQ/RabbitMQ) | Managed message broker | Fully managed ActiveMQ and RabbitMQ. Use when migrating from an existing on-premises message broker and need protocol compatibility (AMQP, MQTT, STOMP, OpenWire). |
Event-driven patterns for monolith decomposition
Event-driven architecture is particularly powerful during Strangler Fig decomposition, because it allows the monolith and new microservices to integrate without direct coupling.
| → Reliable event publishing from monolith | Outbox Pattern * Problem: the monolith cannot reliably publish events AND commit database transactions atomically * Solution: write events to an 'outbox' table in the same database transaction as the business data change * A separate process (DynamoDB Streams or polling) reads the outbox and publishes to SNS/EventBridge * Guarantees exactly-once event publishing even if the application crashes mid-transaction * AWS implementation: Aurora with DynamoDB Streams or Debezium on RDS with SNS delivery |
| → Source of truth as immutable events | Event Sourcing * Store all state changes as an immutable sequence of events rather than current state * Reconstruct current state by replaying events from the beginning (or from a snapshot) * Enables: complete audit trail, temporal queries, event replay for debugging, projections for different read models * AWS implementation: DynamoDB as event store (immutable, versioned items), DynamoDB Streams for real-time projections, S3 for long-term event archive * Best for: financial systems (payment ledgers), inventory management, anything requiring full audit history |
8. Serverless Architecture Patterns on AWS
Serverless is not just Lambda. A complete serverless architecture on AWS combines multiple services into patterns that provide scalability, cost efficiency, and operational simplicity without managing any servers.
The serverless web application pattern
The canonical serverless architecture for web applications: CloudFront → S3 (static frontend) + API Gateway → Lambda → DynamoDB/Aurora Serverless.
| Service | Role in Serverless Architecture |
| CloudFront | Global CDN for static assets (HTML, JS, CSS). Sub-10ms latency globally. Free SSL. Origin shield reduces origin load. |
| S3 (Static Host) | Host the React/Vue/Angular frontend. Versioned deployments. Instant global distribution via CloudFront. |
| API Gateway | HTTP API for serverless REST or GraphQL endpoints. Authentication via Cognito or Lambda authorizer. Rate limiting and throttling. |
| AWS Lambda | Business logic execution. Scales from 0 to 10,000+ concurrent executions automatically. Stateless; state in DynamoDB or Aurora. |
| DynamoDB | NoSQL database for high-scale, low-latency data. On-Demand capacity for unpredictable workloads. Single-digit millisecond reads. |
| Aurora Serverless | SQL database that scales to zero. Ideal when relational data model is required but traffic is variable or unpredictable. |
| AWS Cognito | Managed user authentication, social federation, and JWT token issuance. Integrates natively with API Gateway for auth. |
| SQS / EventBridge | Async processing of background tasks triggered by API calls. Decouples synchronous response from async work. |
The serverless data processing pattern
For ETL, analytics, and data transformation workloads:
- S3 event notification → Lambda: triggered on file upload, Lambda processes and transforms
- Kinesis Data Streams → Lambda: real-time stream processing with automatic scaling
- EventBridge Scheduler → Lambda → Aurora / DynamoDB: periodic batch jobs with no always-on infrastructure
- AWS Glue (serverless Spark): large-scale data transformation without managing Spark clusters
- Step Functions: multi-step data workflows with branching, error handling, and retry built in
9. Observability in Microservices and Serverless: The Pillar You Cannot Skip
A monolith is easy to observe — a single process, a single log stream, a single set of metrics. Microservices and serverless architectures distribute that observability across dozens of services, hundreds of Lambda functions, and millions of individual invocations.
Without proper observability, debugging a production issue in a microservices architecture is dramatically harder than debugging the same issue in a monolith. Observability is not optional — it is what makes distributed systems operable.
The three pillars of observability on AWS
| Pillar | Answers | AWS Implementation |
| Metrics | What happened | Amazon CloudWatch Metrics for AWS service metrics (Lambda invocations, ECS CPU, API Gateway latency). Custom metrics via CloudWatch PutMetricData or embedded metric format. CloudWatch Dashboards for visualization. AWS X-Ray for distributed tracing metrics aggregated by service. |
| Logs | Why it happened | Amazon CloudWatch Logs for centralized log aggregation. Structured JSON logging (not plain text) enables CloudWatch Logs Insights queries. AWS Lambda Powertools for Python/Node/Java: standardized structured logging, tracing, and metrics in one library. Log retention policies to control cost. |
| Traces | Where it happened | AWS X-Ray for distributed tracing across Lambda, ECS, API Gateway, DynamoDB, and SQS. Trace a request from API Gateway through all downstream services to identify latency bottlenecks. X-Ray Service Map visualizes the entire distributed call graph. |
Critical observability patterns for microservices
- Correlation IDs: inject a unique request ID at the edge (API Gateway) and propagate it through every service call and log message. Enables end-to-end request tracing across all services for a single user action.
- Structured logging: every log entry is a JSON object with defined fields (requestId, service, level, timestamp, userId, duration). Enables querying and alerting on specific fields rather than text parsing.
- Service-level objectives (SLOs): define availability and latency targets per service (e.g. 99.9% of API requests under 200ms). Alert when SLOs are at risk, not just when they are breached.
- Dead letter queues (DLQs): configure DLQs on all SQS queues and Lambda async invocations. Failed messages land in DLQ rather than silently disappearing. Alert on DLQ depth.
- Circuit breakers: prevent cascading failures when a downstream service is degraded. AWS App Mesh or client-side circuit breaker libraries (resilience4j, pybreaker) protect upstream services from slow downstream services.
| ℹ | EaseCloud implements the full observability stack — structured logging, distributed tracing, SLO dashboards, DLQ alerting, and on-call runbooks — as part of every modernization engagement. Observability is built in from service day one, not retrofitted after incidents. |
10. The Modernization Decision Framework: Choosing Your Path
With all the options, patterns, and services covered, this section synthesizes the decision criteria into a practical framework for choosing your modernization path.
Step 1: Assess your current situation
| Dimension | What It Implies for Modernization Strategy |
| Team size | < 8 engineers → Modular monolith first. 8–25 engineers → Strangler Fig decomposition. 25+ engineers → Bounded context decomposition may be actively blocking you. |
| Deployment frequency | < 1/week → Fix CI/CD and testing before modernizing. The architecture is not the bottleneck. 1–5/week → Modernization will unlock further velocity. 5+/day → You likely already have good practices; modernization can address specific scaling bottlenecks. |
| Scaling pain points | Identify which specific components are scaling bottlenecks. Not all components need to scale independently — extract only those that do. |
| Engineering runway | < 6 months runway → Do not start modernization. It will not complete and will consume resources needed for product. > 12 months runway → Modernization is viable alongside product development. |
| Compliance requirements | If SOC 2 or HIPAA is required, plan security architecture before decomposition — not after. Distributed architectures have more security surface area. |
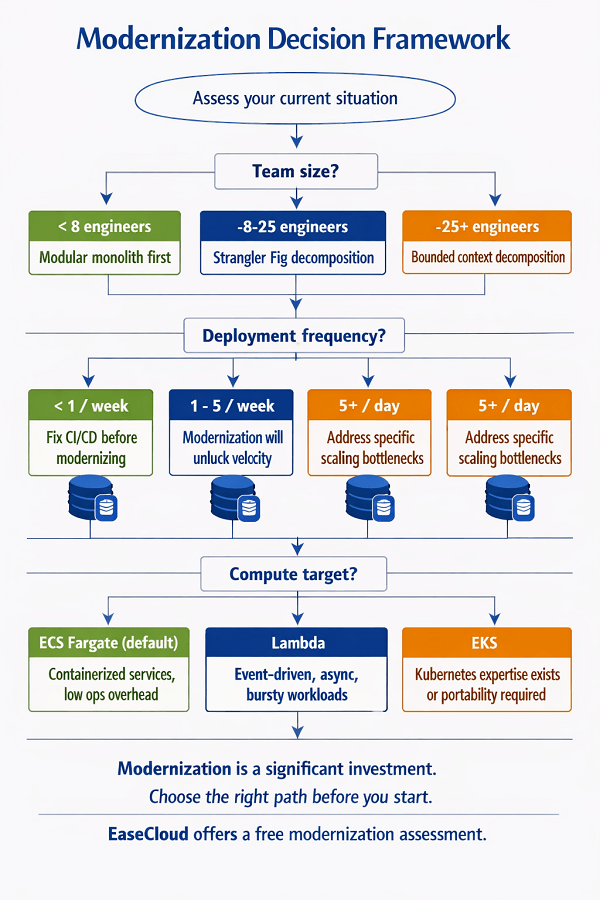
Step 2: Choose your pattern
| Modular Monolith Small team (< 10), PMF not confirmed, or deployment velocity is the main issue. Stay monolith, improve internal structure and CI/CD. | Strangler Fig Team 10–30, monolith is painful but running. Incrementally extract services over 12–18 months while shipping product. | Selective Serverless Specific event-driven or async workloads are bottlenecks. Extract those to Lambda without broader decomposition. |
Step 3: Choose your compute target
| ECS Fargate Default choice for most. Containerized services, low ops overhead, scales to zero with scheduled scaling. Start here. | AWS Lambda Event-driven, async, bursty, or scheduled workloads. Not for long-running or latency-critical sustained traffic. | EKS Kubernetes expertise exists in the team, or portability and Kubernetes ecosystem (Helm, Istio, KEDA) is a hard requirement. |
11. Microservices and Serverless Anti-Patterns to Avoid
For every successful microservices migration, there are failed ones that created distributed monoliths — all the operational complexity of microservices with none of the autonomy benefits. These are the most common architectural mistakes.
- The Distributed Monolith. Services decomposed by technical layer (API service, business logic service, data access service) rather than business domain. Services are tightly coupled and must be deployed together. This is a monolith with network overhead added. Always decompose by business domain, not technical layer.
- Shared Database Anti-Pattern. Multiple microservices reading and writing the same database schema. Recreates all the coupling of the monolith at the data layer while adding network overhead. Schema changes still require coordination across all teams. Enforce database-per-service absolutely.
- Nanoservices / Too Fine-Grained Decomposition. Services decomposed so granularly that a single business operation requires 10–20 sequential synchronous service calls. Latency accumulates, failure probability multiplies, and debugging becomes intractable. Service boundaries should reflect business capabilities, not individual functions.
- Synchronous Everything. Using HTTP REST for all inter-service communication including long-running processes and fan-out notifications. Produces tight temporal coupling (caller blocks until callee responds), amplified failure propagation, and cascade failures. Use async messaging (SQS, SNS, EventBridge) for everything that doesn't need an immediate synchronous response.
- Lambda for Everything. Defaulting to Lambda for all compute without considering workload characteristics. A 10-minute data processing job forced into Lambda chained functions is harder to operate, more expensive, and less reliable than an ECS Fargate task. Match the compute model to the workload.
- No Observability Until Production Problems. Building distributed services without distributed tracing, structured logging, and correlation IDs, then adding observability after the first production incident. Observability in distributed systems must be designed and implemented from the start — retrofitting it is much harder than getting it right initially.
- Big-Bang Microservices Migration. Stopping all feature development to rewrite the entire application as microservices. The business does not pause. The competition does not pause. The monolith must continue to evolve while it is being decomposed. Any migration strategy that requires freezing the product is not viable.
12. The Real Cost of Modernization — and the ROI
Modernization is a significant investment. Setting accurate expectations about cost and timeline is essential for securing organizational commitment and sustaining the effort through the difficult middle phase.
| Phase | Timeline | Investment & What It Covers |
| Assessment & Architecture Design | 4–8 weeks | $20,000–$50,000. Domain analysis, bounded context mapping, target architecture design, IaC templates for new service infrastructure, observability design. |
| First Service Extraction | 6–10 weeks | $30,000–$60,000. Strangler Fig routing layer setup, first bounded context extraction, CI/CD pipeline for new service, full observability implementation. |
| Ongoing Extraction Cadence | Per service | $15,000–$35,000 per bounded context extracted. Includes data migration, integration testing, canary rollout, and monolith code deletion. |
| Serverless Migration (selective) | 4–8 weeks | $15,000–$40,000. Identify Lambda candidates, implement with observability, performance test, cost model, and deploy. |
| Full Modernization Program | 12–24 months | $200,000–$600,000+ for a medium-complexity monolith. Includes all extractions, platform engineering, and observability. |
The ROI case for modernization
| ROI Dimension | Typical Improvement |
| Deployment frequency | 3–5 deployments/quarter → 3–5 deployments/day. Each deployment de-risked by independent service scope. |
| Feature delivery speed | 3–5× faster time-to-market as teams work independently on separate services without deployment coordination. |
| Infrastructure cost | 40–60% reduction from independent scaling — only scale what's under load, not the entire application. |
| Incident impact | Failures isolated to single services. Blast radius reduced from 'everything down' to 'this feature degraded.' |
| Engineering retention | Modern architectures attract and retain senior engineers. Technical debt accumulation is a leading cause of engineer attrition. |
| Enterprise sales | SOC 2 compliance and modern architecture are prerequisites for enterprise contracts at most companies above $5M ARR. |
| ★ | EaseCloud clients typically see 3–5× deployment frequency improvement and 40–60% infrastructure cost reduction within 12 months of beginning a modernization program. The investment pays back within 18–24 months in most cases — faster when modernization unblocks specific revenue opportunities like enterprise sales. |
Conclusion
Application modernization is not about technology – it's about strategy. The monolith ceiling is real, but the solution is not a big-bang rewrite (which has killed companies). The proven path is incremental: Strangler Fig extraction, one bounded context at a time, maintaining product velocity throughout.
AWS provides the primitives – ECS Fargate for containers, Lambda for event-driven workloads, API Gateway for routing, SQS/SNS/EventBridge for decoupling. The key decisions are not technical but strategic: which services to extract first (low coupling, high value), which compute model fits each workload (containers vs serverless), and how to manage data (database-per-service, Outbox, Saga).
The ROI is measurable: 3-5× faster deployments, 40-60% lower infrastructure costs. Start with a free assessment. Know your monolith's bottlenecks. Modernize with discipline, not dogma.
Application Modernization FAQ
How do we modernize without stopping product development?
The Strangler Fig pattern is specifically designed for this. New functionality is built in new services; existing functionality is extracted incrementally in parallel with product development. The rule of thumb: no more than 20% of engineering capacity goes to modernization at any time. Product velocity is maintained; modernization is a sustained background programme, not a sprint.
How do we know which services to create first?
Start with the services that have the clearest boundaries and the lowest coupling to the rest of the monolith. Common first extractions: user authentication, email/notification services, reporting. Avoid starting with the payment or order management domain — these are almost always the most tightly coupled and highest-risk migrations.
Should we use microservices or serverless — or both?
Both. They are complementary, not competing. Long-running, always-on, containerized workloads live in ECS/EKS as microservices. Event-driven, async, and bursty workloads run as Lambda functions. Most mature AWS applications use a hybrid model: a core of ECS-hosted microservices with Lambda handling async processing, scheduled jobs, and event-driven workflows.
How do we handle the shared database during Strangler Fig migration?
Incrementally. The monolith database is not migrated in one step. As each service is extracted, the data it owns is moved to a new per-service database. A transition period exists where both the monolith and the new service access overlapping data — this is managed through a shared library or direct database access with a defined end-date. The goal is progressive ownership transfer, not a single cutover.
What team structure works best for microservices?
Conway's Law dictates that your architecture will mirror your team structure. For microservices to deliver autonomous deployment, you need autonomous teams — each owning end-to-end responsibility for one or two services (product, deployment, on-call). The standard model is two-pizza teams (6–10 engineers) owning a bounded context. Platform engineering teams own shared infrastructure (CI/CD, observability, service mesh).
How do we manage secrets across many microservices?
AWS Secrets Manager with IAM role-based access per service. Each microservice has an IAM role that grants read access only to the secrets it needs. Secrets are injected at runtime — never baked into container images or environment variables in source code. Automatic secret rotation is available for database credentials. AWS Parameter Store is a cost-effective alternative for non-sensitive configuration.
Ready to Modernize Your Application on AWS?
EaseCloud's application modernization team has taken startups and SMBs from legacy monoliths to modern microservices and serverless architectures — always alongside active product development, never instead of it.
We start with an honest assessment: is modernization actually your bottleneck? If it is, we design and execute the migration. If it is not, we tell you what is — and fix that instead.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.