Microservices vs Monoliths Performance Optimization
Compare performance characteristics of monoliths vs microservices. Learn optimization strategies, latency trade-offs, scaling approaches, and how to choose the right architecture.


TL;DR
- Monoliths have lower latency (nanoseconds for internal calls vs milliseconds for network calls). Microservices add 10-100ms per request chain.
- Microservices scale granularly – scale only services that need it. Monoliths replicate everything together.
- Use gRPC for efficient binary communication, batch operations to reduce call count, and circuit breakers to prevent cascading failures.
- Start with a modular monolith unless you need independent team deployment or dramatically different scaling per service.
Architecture choice significantly affects performance characteristics. Monolithic applications have different bottlenecks, optimization strategies, and scaling patterns than microservices. Neither approach is universally superior; each suits different contexts. Understanding performance implications helps choose and optimize the right architecture.
Performance Characteristics of Each Approach
Monolithic applications run as single processes. All components share memory space. Internal function calls are fast. No network serialization between modules. Simplicity often means fewer things can go wrong.
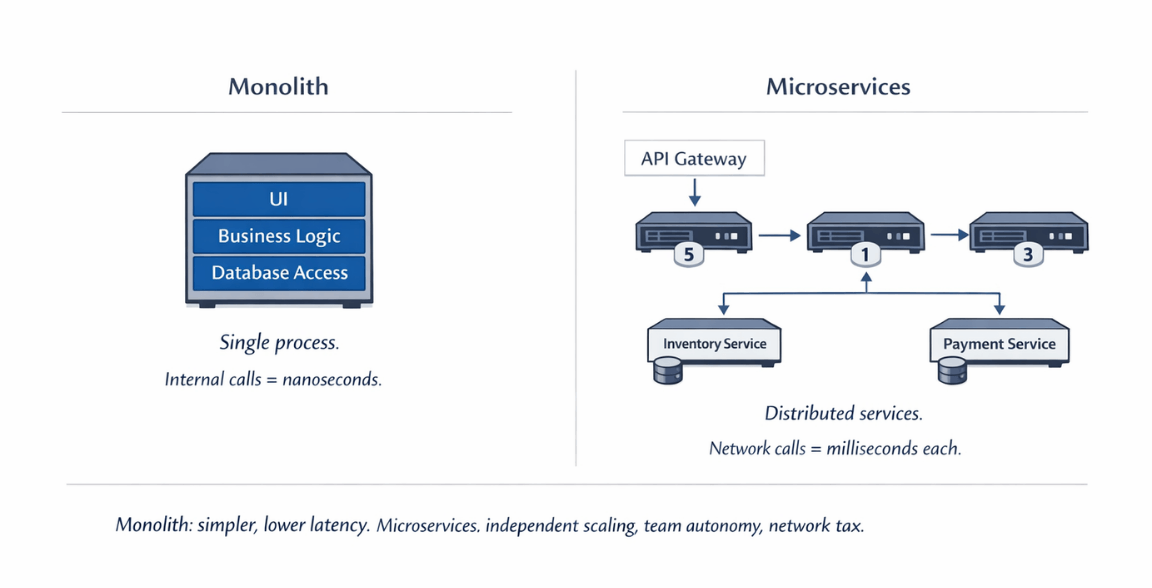
Microservices distribute components across services. Each service runs independently, often in separate containers or servers. Communication happens over networks. This distribution enables independent scaling but adds complexity.
Resource efficiency favors monoliths at smaller scales. Running one process is more efficient than running many. Memory overhead, process management, and network infrastructure all add up in microservices.
Operational complexity affects performance indirectly. Complex systems are harder to optimize. More components mean more places for performance problems to hide.
Development velocity can affect performance outcomes. If microservices enable teams to iterate faster, they may fix performance problems sooner. If they slow delivery, problems persist longer.
| Aspect | Monolith | Microservices |
|---|---|---|
| Internal call latency | Nanoseconds (function calls) | Milliseconds minimum (network calls) |
| Resource efficiency | Higher (single process) | Lower (many processes, network overhead) |
| Operational complexity | Lower | Higher |
| 5 internal call latency | Negligible | 50-500ms added |
| Scaling granularity | All components scale together | Independent per-service scaling |
| Debugging | Simpler (single logs, stack traces) | Complex (requires distributed tracing) |
Monolith Performance Optimization
Database optimization often dominates monolith performance work. Single databases serve the entire application. Query optimization, indexing, and caching provide high leverage.
Memory management affects application-wide performance. Memory leaks gradually degrade performance. Garbage collection pauses affect all functionality. Profile and optimize memory usage holistically.
Caching integrates naturally in monoliths. In-process caches share memory with the application. No network round-trips to cache servers. Simple libraries like LRU caches provide immediate benefit.
from functools import lru_cache
@lru_cache(maxsize=1000)
def get_user_permissions(user_id):
# Expensive query, cached in process memory
return database.query_permissions(user_id)
Thread pool sizing affects concurrent request handling. Too few threads cause request queuing. Too many consume excessive memory. Monitor and tune based on workload.
CPU profiling reveals hot spots. Identify functions consuming disproportionate CPU time. Optimize algorithms or data structures in high-impact areas.
Vertical scaling is often straightforward. Larger servers with more CPU, memory, and I/O capacity directly benefit monolithic applications.
Background job processing prevents blocking. Move long-running operations to background workers. Users receive immediate responses while work completes asynchronously.
Microservices Performance Optimization
Service-to-service communication dominates latency. Every network call adds latency, serialization overhead, and failure risk. Minimize inter-service calls where possible.
Design service boundaries to reduce chattiness. Services should be cohesive units that handle related operations internally. Poorly designed boundaries create excessive cross-service communication.
Implement efficient serialization. JSON is human-readable but verbose. Protocol Buffers, MessagePack, or other binary formats reduce serialization overhead.
Connection pooling prevents connection overhead. Maintain persistent connections between services. Each new connection requires handshaking overhead.
Circuit breakers prevent cascade failures. When a service fails, callers should fail fast rather than waiting and propagating delays.
from circuitbreaker import circuit
@circuit(failure_threshold=5, recovery_timeout=30)
def call_user_service(user_id):
response = requests.get(f'{USER_SERVICE}/users/{user_id}')
response.raise_for_status()
return response.json()
Async communication reduces blocking. Message queues decouple services. Producers don't wait for consumer processing. This pattern suits operations that don't require immediate responses.
API Gateway optimization affects all requests. Gateway overhead applies to every request. Optimize routing, authentication, and transformation at the gateway level.
Per-service optimization enables targeted improvements. Each service can scale and optimize independently. Performance improvements in one service don't require changes elsewhere.
Network and Latency Considerations
Network latency is the fundamental microservices tax. Every call crosses the network. Latency accumulates through call chains. Design to minimize call depth.
Service mesh adds latency but provides features. Proxies intercept traffic for observability, security, and traffic management. This overhead typically adds 1-3ms per hop.
Caching reduces repeated network calls. Cache responses at calling services. Consider cache-aside patterns with Redis or Memcached.
Batch operations reduce call count. Instead of fetching items one at a time, fetch many in single requests. This amortizes network overhead across multiple items.
# Inefficient: N calls for N items
for item_id in item_ids:
item = item_service.get(item_id)
# Efficient: 1 call for N items
items = item_service.get_many(item_ids)
Consider data locality. Keep frequently accessed data close to services that need it. Sometimes duplicating data across services reduces cross-service calls.
gRPC provides efficient binary communication. Compared to REST/JSON, gRPC offers smaller payloads, efficient serialization, and HTTP/2 multiplexing.
Service placement affects latency. Co-locate tightly coupled services. Use the same availability zone when possible to minimize network latency.
Scaling Strategies
Monoliths scale by replicating the entire application. Horizontal scaling adds more identical instances behind load balancers. All components scale together regardless of individual load.
Microservices scale independently. High-traffic services get more instances. Low-traffic services stay small. This granular scaling optimizes resource usage.
Database scaling challenges both approaches. Shared databases limit horizontal scaling. Microservices with separate databases scale better but add data management complexity.
| Aspect | Monolith | Microservices |
|---|---|---|
| Scaling method | Replicate entire application | Independent service scaling |
| Resource usage | All components scale together | Only high-traffic services scale |
| Database scaling | Shared database limits | Separate databases per service (better scaling, more complexity) |
| Operational simplicity | Fewer deployment units | Requires sophisticated orchestration |
Stateless design enables scaling in both architectures. Session state in external storage allows any instance to handle any request.
Auto-scaling responds to demand dynamically. Both monoliths and microservices benefit from auto-scaling, though microservices enable more granular scaling policies.
Monolith scaling is simpler operationally. Fewer deployment units mean simpler infrastructure. Microservices scaling requires more sophisticated orchestration.
Traffic routing enables gradual rollouts. Both architectures support canary deployments, though microservices enable service-level granularity.
Stateless design + auto-scaling = scalable architecture. We build both.
Horizontal scaling works for monoliths. Granular scaling works for microservices. Both require stateless design and proper auto-scaling configuration.
We help you:
- Design truly stateless applications – External session storage, no server affinity
- Configure auto-scaling policies – Target metrics, cooldown periods
- Implement database scaling strategies – Read replicas, connection pooling
- Right-size instances – No over-provisioning, no idle capacity
Monitoring and Debugging
Monolith debugging is often simpler. Single processes mean single logs. Stack traces show complete execution paths. Traditional debugging tools work naturally.
Microservices require distributed tracing. Understanding request flow across services requires correlation IDs and tracing infrastructure. Tools like Jaeger or Zipkin become essential.
# Adding trace context to service calls
import opentelemetry.trace as trace
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("get_order_details"):
order = order_service.get(order_id)
customer = customer_service.get(order.customer_id)
products = product_service.get_many(order.product_ids)
Centralized logging aggregates distributed logs. ELK Stack, Splunk, or cloud logging services collect logs from all services.
Service-level metrics enable granular monitoring. Each service reports its performance independently. Dashboards show system-wide health and individual service status.
Error tracking requires understanding service dependencies. An error in one service may originate from a dependency. Distributed tracing reveals root causes.
Performance baselines help identify degradation. Establish normal behavior for each service. Alert when metrics deviate from baselines.
Making the Right Choice
Start with a modular monolith if uncertain. Well-structured monoliths can evolve into microservices if needed. Premature microservices add unnecessary complexity.

Microservices suit large teams and complex domains. Independent deployment enables team autonomy. Domain complexity may naturally suggest service boundaries.
Consider your operational maturity. Microservices require more sophisticated DevOps practices. Container orchestration, service mesh, and distributed debugging are table stakes.
Performance requirements may favor one approach. Ultra-low latency requirements may favor monoliths. Extreme scale requirements may favor microservices.
| Factor | Monolith | Microservices |
|---|---|---|
| Latency per request | Lower | Higher |
| Granular scaling | Limited | Excellent |
| Operational complexity | Lower | Higher |
| Team independence | Limited | High |
| Debugging simplicity | Higher | Lower |
Neither approach prevents performance optimization. Both require profiling, measurement, and targeted improvement. The techniques differ, but the discipline is the same.
Conclusion
Neither monoliths nor microservices are inherently faster or slower it's about fit to context. Monoliths offer lower latency and simpler debugging for smaller applications and teams. Microservices enable granular scaling and independent deployment but impose network costs and operational complexity.
The best choice depends on team size, domain complexity, latency requirements, and operational maturity. Start with a well-structured modular monolith. Extract services only when clear boundaries and independent scaling needs emerge.
Regardless of choice, apply disciplined optimization: profile, measure, cache aggressively, and minimize cross-service communication. Performance is not automatic in either architecture it's earned through deliberate practice.
FAQs
1. Can a monolith scale as well as microservices?
- Yes, for many applications – horizontal scaling (multiple monolith instances behind load balancers) handles significant traffic
- Database scaling is the limiting factor, not the application architecture
- Many successful SaaS companies run on monolithic applications serving billions of requests
- Microservices provide finer-grained scaling (scale only the expensive service) and team independence, not necessarily higher raw throughput
2. When should I choose microservices over a monolith for performance reasons
- When different parts of your system have dramatically different scaling requirements or resource profiles
- Example: Social media app where feed rendering is CPU-intensive and chat needs low latency
- Monolith: both scale together → over-provision feed capacity to get chat performance
- Microservices: each scales independently
- When team size requires independent deployment (coordination overhead in monoliths indirectly hurts performance by slowing optimization delivery)
3. How much latency does a service mesh actually add?
| Component | Latency Added per Hop |
|---|---|
| Service mesh proxies (Istio, Linkerd, Consul) | 1-3ms |
| Call chain of 3-5 services | 3-15ms total |
| Human perception threshold | ~100ms |
Acceptable for most SaaS applications; problematic for real-time or financial systems requiring single-digit millisecond latency. For ultra-low-latency workloads, consider sidecar-less service meshes or skipping the mesh entirely for critical paths.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.