AWS Fargate Spot for Kubernetes Cost Savings
Fargate Spot cost savings on EKS with interruption handling, PodDisruptionBudgets, and capacity providers. Cut serverless container bills up to 70% in EU regions.


TLDR;
- Fargate Spot cost savings reach up to 70% versus on-demand Fargate for fault-tolerant batch and async workloads on EKS.
- A mixed capacity strategy of 80% Spot and 20% on-demand keeps uptime high while maximizing savings.
- PodDisruptionBudgets and checkpointing let workloads survive two-minute interruption notices gracefully.
- Fargate Spot is available in eu-west-1 and eu-central-1, fitting GDPR data-residency requirements for EU SaaS teams.
Fargate Spot cost savings matter most to teams that want serverless container simplicity without the premium Fargate on-demand price tag. AWS Fargate removes EC2 management, but the per-task cost is roughly 20-30% higher than equivalent EC2 capacity.
Fargate Spot closes that gap by discounting interruptible capacity up to 70%, which transforms the unit economics of batch processing, CI runners, and event-driven workloads running on EKS.
According to AWS Fargate pricing documentation, Spot is priced dynamically against supply and demand in each region. European teams running eu-west-1 and eu-central-1 typically see consistent 60-70% discounts on Graviton-backed Fargate Spot tasks.
| Comparison | Cost Difference | Region |
|---|---|---|
| Fargate on-demand vs. EC2 | On-demand ~20-30% higher than EC2 | Global |
| Fargate Spot vs. Fargate on-demand | Up to 70% discount | eu-west-1, eu-central-1 typically see 60-70% discounts |
This article covers how to design EKS workloads that survive Fargate Spot interruptions, the Fargate profile and pod-spec settings required, and the guardrails that make Spot safe for production-adjacent workloads under GDPR constraints.
Technical Overview
Fargate Spot reuses the same Fargate runtime as on-demand, so pods behave identically except for one difference: AWS can reclaim the underlying microVM with a two-minute warning when capacity is needed elsewhere. When reclamation happens, the Fargate service sends a SIGTERM to the pod, waits up to 120 seconds, then sends SIGKILL.
The EKS control plane reschedules the pod onto available capacity, which can be another Spot microVM or on-demand depending on the Fargate profile configuration. According to the EKS Fargate documentation, a Fargate profile maps pod selectors to a pod execution role, subnets, and a capacity provider strategy.
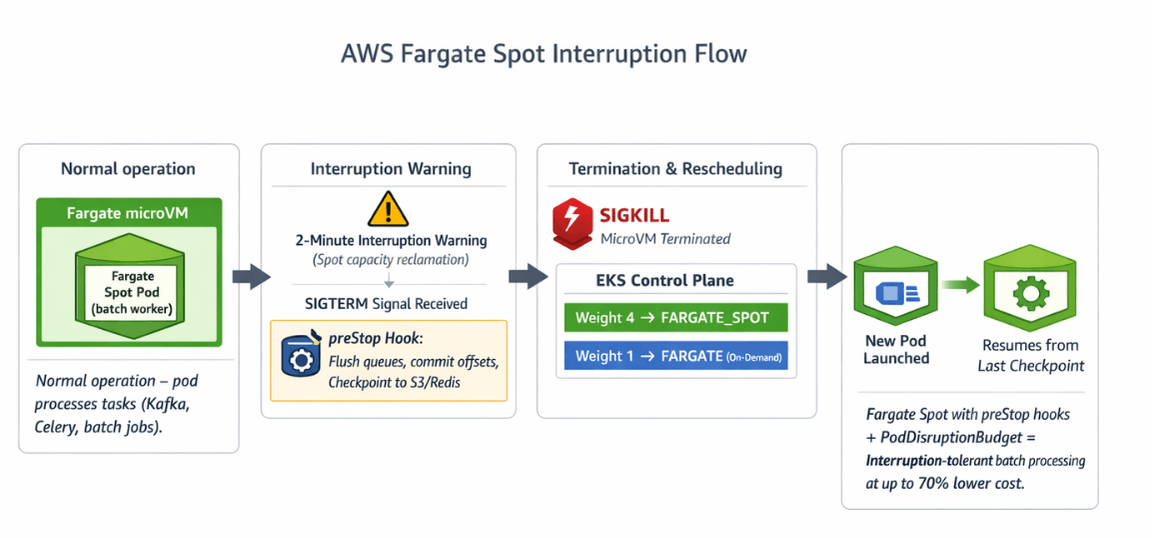
On EKS with capacity providers, you configure the weight between FARGATE and FARGATE_SPOT; the scheduler picks microVMs proportionally. This gives you a knob to dial Spot utilization up for tolerant workloads and down for sensitive ones, without redefining deployments.
Fargate Spot pairs well with async workloads:
| Good Fit | Poor Fit |
|---|---|
| Kafka consumers | Stateful databases |
| Celery or Sidekiq workers | Long-lived session stores |
| ML inference queues | Latency-critical APIs (two-minute termination window unacceptable) |
| Nightly batch jobs |
Step-by-Step Implementation
Create a Fargate profile that scopes Spot capacity to a dedicated namespace. Using eksctl:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: orders-eks
region: eu-west-1
fargateProfiles:
- name: spot-batch
selectors:
- namespace: batch
labels:
workload-class: spot-tolerant
podExecutionRoleARN: arn:aws:iam::123456789012:role/eksFargatePodExecutionRole
subnets:
- subnet-0aaa
- subnet-0bbb
- subnet-0ccc
Apply with eksctl create fargateprofile -f profile.yaml. Any pod in the batch namespace carrying workload-class: spot-tolerant lands on a Fargate microVM, and the capacity-provider strategy decides whether that microVM is Spot or on-demand.
Configure a capacity-provider strategy at the cluster level so the default is 80% Spot, 20% on-demand:
aws eks update-cluster-config \
--region eu-west-1 \
--name orders-eks \
--compute-config '{
"computeProviders": [
{"capacityProvider": "FARGATE_SPOT", "weight": 4, "base": 0},
{"capacityProvider": "FARGATE", "weight": 1, "base": 1}
]
}'
Next, harden each Spot-eligible Deployment with a PodDisruptionBudget and SIGTERM handling:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: order-worker-pdb
namespace: batch
spec:
minAvailable: 2
selector:
matchLabels:
app: order-worker
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-worker
namespace: batch
labels:
workload-class: spot-tolerant
spec:
replicas: 6
template:
metadata:
labels:
app: order-worker
workload-class: spot-tolerant
spec:
terminationGracePeriodSeconds: 110
containers:
- name: worker
image: 123456789012.dkr.ecr.eu-west-1.amazonaws.com/order-worker@sha256:abc
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "kill -TERM 1; wait"]
The terminationGracePeriodSeconds: 110 value stays inside the 120-second Fargate window. According to the Kubernetes documentation on pod lifecycle, this window gives the process time to flush queues, commit offsets, and exit cleanly.
Capture interruption signals in your code. Workers should checkpoint to S3, Redis, or Amazon MQ before exit so the replacement pod resumes from the last known state instead of reprocessing from zero.
70% Fargate discounts require correct interruption handling. We implement the full stack.
Fargate Spot savings are real – but only if your workloads survive interruptions with two-minute notice.
Our cloud cost optimization experts help you:
- Configure Fargate capacity provider strategy – 80% Spot, 20% on-demand weights
- Set up PodDisruptionBudgets –
minAvailable: 2prevents zero replicas during interruptions - Implement preStop hooks – Flush queues, commit offsets, checkpoint to S3/Redis
- Right-size terminationGracePeriodSeconds – 110 seconds within Fargate's 120-second window
Optimization Best Practices
Diversify microVM sizes across the Deployment. Request a range like 0.5-2 vCPU per pod by splitting workloads across multiple Deployments rather than one huge one; smaller Fargate Spot sizes have deeper capacity pools and shorter interruption half-lives.
Route only idempotent work to Spot. Order confirmations, payment captures, and email sends should use idempotency keys so a retried task does not double-charge a customer. According to AWS architectural guidance on Fargate Spot, idempotency is the non-negotiable prerequisite for running any production workload on Spot capacity.
Hybrid architecture recommendation:
| Component | Capacity Type | Rationale |
|---|---|---|
| Bursty workers | Fargate Spot | Operational simplicity |
| Long-running services | Karpenter-managed EC2 Spot | Raw price advantage for sustained load |
| Power user pattern | Hybrid posture | Captures both wins |
For GDPR-regulated workloads, restrict Fargate profiles to eu-west-1 or eu-central-1 subnets and enable AWS CloudTrail logging on all Fargate task API calls. This keeps both data plane and control plane audit trails inside the EU perimeter.
Monitoring and Troubleshooting
Subscribe to EventBridge events of type EC2 Spot Instance Interruption Warning and mirror them onto an Amazon SNS topic for on-call visibility. Track aws_fargate_spot_interruption_count as a Prometheus metric scraped from an EventBridge-to-Prometheus adapter. An interruption rate above 15% in a rolling hour usually signals that the workload is competing for scarce capacity; switching to an adjacent task size class often restores stability.
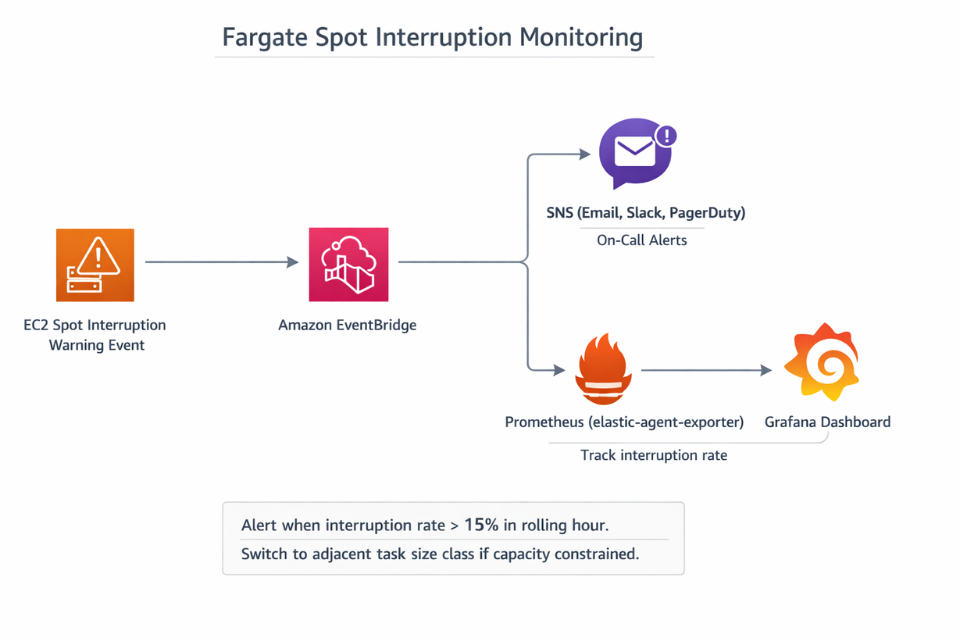
Check pod eviction reasons with kubectl get events --field-selector reason=Preempting. If pods are evicted before the 120-second grace window completes, lower terminationGracePeriodSeconds to 100 to give kubelet time to clean up properly. Capture queue depth and consumer lag as a leading indicator; a sustained backlog after interruptions hints that replicas are set too low to absorb reclamation events.
Conclusion
Fargate Spot cost savings come from designing for interruption, not from flipping a capacity-provider switch. European EKS teams that pair Fargate Spot with idempotent workers, PodDisruptionBudgets, and 110-second grace periods run production-adjacent workloads at 60-70% lower cost than on-demand Fargate, all inside GDPR-compliant EU regions.
EaseCloud helps European teams migrate batch and async workloads onto Fargate Spot with safe interruption handling and multi-AZ topologies. Book a session with EaseCloud to design a Fargate Spot rollout that fits your reliability targets and compliance posture.
Frequently Asked Questions
Can Fargate Spot run stateful workloads?
Only with external state stores. Keep durable state in RDS, DynamoDB, S3, or ElastiCache, and treat Fargate Spot pods as disposable workers that checkpoint frequently.
What regions support Fargate Spot for EKS?
Fargate Spot is available in most commercial AWS regions, including:
| Region | Location |
|---|---|
| eu-west-1 | Ireland |
| eu-central-1 | Frankfurt |
| eu-west-3 | Paris |
Verify region-specific availability on the AWS regional services page before planning a workload.
How does Fargate Spot pricing differ from EC2 Spot?
Fargate Spot vs. EC2 Spot:
| Aspect | Fargate Spot | EC2 Spot |
|---|---|---|
| Discount | Generally ~70% off on-demand | Can be cheaper at peak savings |
| Price behavior | More stable discounts | Fluctuates continuously based on capacity supply |
| Operational complexity | Easier to operate | More complex (requires node management) |
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.