EKS Right-Sizing for Cost Optimization
EKS right-sizing cost optimization with Graviton3, mixed instance types, and pod resource tuning. Cut EKS worker node bills 30-50% on EU regions.


TLDR;
- EKS right-sizing cost optimization trims worker-node spend by 30-50% when request tuning and instance selection run in parallel.
- Graviton3 instances deliver up to 40% better price-performance than comparable x86 types for most stateless workloads.
- Mixed instance types across m6i, m7g, and c7g families improve Spot availability and bin-packing density.
- Lock worker nodes to eu-central-1 Graviton pools to cut both euros and carbon footprint.
EKS right-sizing cost optimization is the discipline of matching worker-node capacity to the actual resource profile of your pods, instead of buying the instance type that "feels safe."
| Metric | Value |
|---|---|
| Typical EKS cluster average CPU utilization | 20-35% |
| Wasted capacity (idle cores) | 65-80% of bill |
According to AWS internal telemetry and third-party studies
According to AWS best practices for EKS, right-sizing produces the single largest cost reduction for most containerized workloads, ahead of Spot adoption and reserved capacity. For European teams running eu-west-1 and eu-central-1, right-sizing also has a sustainability payoff: Graviton-based instances consume less power per request, and eu-central-1 draws heavily on renewable energy, so the carbon impact of each workload drops alongside the euro cost. This article walks through the practical steps that take an EKS cluster from guesswork sizing to data-driven capacity planning.
Technical Overview
Right-sizing happens at two layers.
| Layer | Focus | Key Action |
|---|---|---|
| Pod-level | resources.requests and resources.limits |
Adjust to match observed CPU/memory usage + 20-30% buffer for bursts |
| Node-level | EC2 instance types, architectures, purchase options | Select types that bin-pack pods efficiently |
According to the Kubernetes documentation on resource management, the scheduler places pods based on requests, not limits. A deployment that requests 2 vCPU but uses 500 millicores blocks 1.5 vCPU of schedulable capacity on every node, forcing the cluster to launch additional nodes for phantom workload.
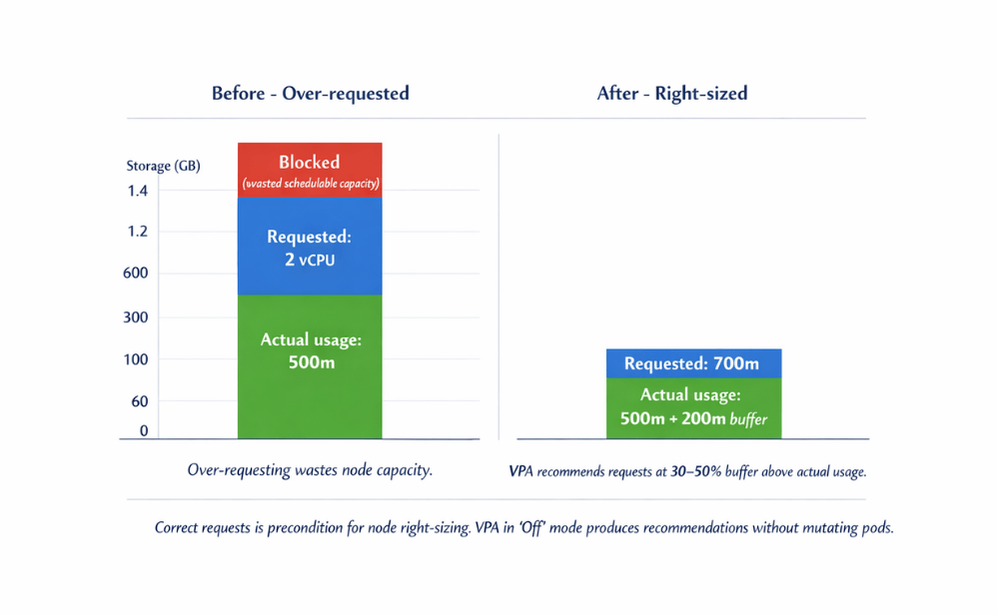
Correcting requests is therefore a precondition for node right-sizing; otherwise Karpenter or the Cluster Autoscaler will simply select a cheaper instance that is still three-quarters empty.
| Instance Family | Use Case | Cost/Performance Improvement |
|---|---|---|
m7g, c7g |
General-purpose EKS workloads | 25-40% lower per-request cost |
r7g |
Memory-heavy workloads | Same price-performance uplift |
Source: AWS Graviton documentation
Mixed instance types through a Karpenter NodePool let the scheduler pick whichever family has the lowest cost at scheduling time while respecting pod architecture constraints.
Step-by-Step Implementation
Phase one is gathering evidence. Deploy the Vertical Pod Autoscaler in Off mode so it produces recommendations without mutating pods, and let it run for at least two weeks to capture weekly traffic cycles. A minimal VPA manifest looks like:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: api-recommender
namespace: storefront
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: api
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: api
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 4
memory: 8Gi
Read recommendations with kubectl describe vpa api-recommender and apply the target values to the Deployment spec. Most teams find that 40-60% of their pods are requesting two to four times the CPU they consume.
Phase two is node selection. Define a Karpenter NodePool that prefers Graviton and mixed instance sizes within a single family series:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: graviton-general
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["arm64"]
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["m7g", "c7g", "r7g"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano", "micro", "small"]
- key: topology.kubernetes.io/zone
operator: In
values: ["eu-central-1a", "eu-central-1b", "eu-central-1c"]
nodeClassRef:
name: default
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 60s
The instance-size NotIn rule prevents Karpenter from launching tiny nodes that waste overhead on kubelet, CNI, and DaemonSets. According to AWS Graviton documentation, most scripted benchmarks show Graviton3 delivering 25-40% lower per-request cost for typical web and API workloads.
Phase three is rebuilding container images as multi-architecture. Use docker buildx build --platform linux/amd64,linux/arm64 in CI and push manifests that satisfy both arches. The scheduler then routes arm64-compatible pods onto Graviton nodes without changes to deployment manifests.
Optimization Best Practices
Right-size DaemonSets as aggressively as application pods. Logging agents, CNI components, and node-exporter each reserve CPU and memory on every node, so an overstated DaemonSet request multiplies across the fleet.
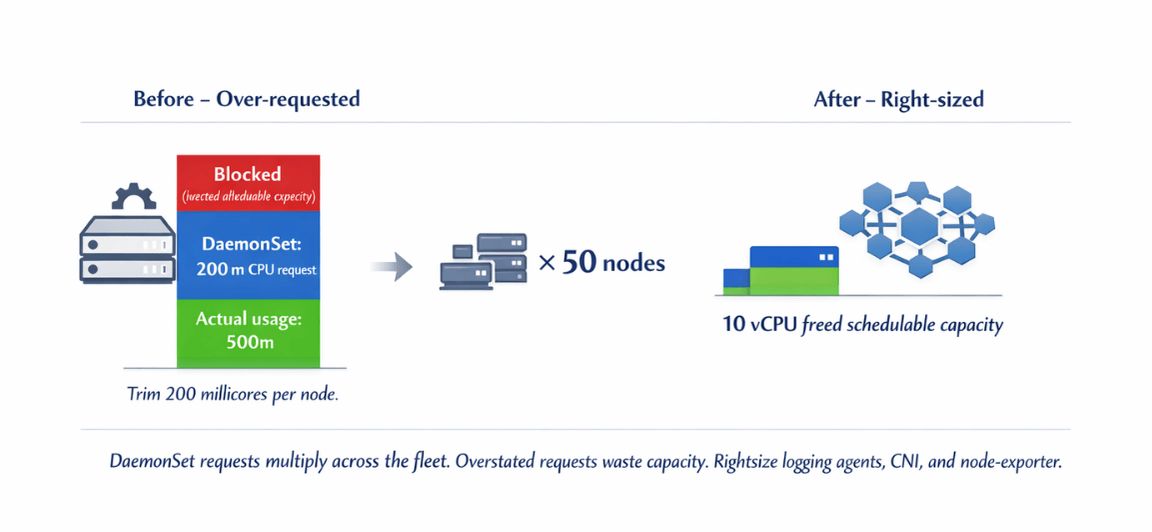
| Action | Single Node Impact | 50-Node Cluster Impact |
|---|---|---|
| Trim 200 millicores from DaemonSet | 0.2 vCPU | 10 vCPU freed schedulable capacity |
Source: CNCF benchmarking reports
- Separate stateless and stateful workloads into distinct NodePools
- Stateless: aggressive consolidation with short
consolidateAfter - Stateful: longer windows + PodDisruptionBudgets
- Stateless: aggressive consolidation with short
- Reserve on-demand capacity through Savings Plans for steady-state baseline
- Let Karpenter provision Spot on top of baseline
- Compute Savings Plan - according to AWS Savings Plans documentation covers EKS worker nodes across instance families and regions (pairs naturally with Karpenter's dynamic instance selection)
- Tag NodePools with cost-center and workload-class labels for OpenCost and AWS Cost Explorer
GDPR-sensitive workloads pinned to eu-central-1 can carry a data-residency: eu label to simplify audit reviews. A quarterly review that joins these labels with VPA recommendations often surfaces another 5-10% of waste that would otherwise slip through the initial rightsizing pass.
Monitoring and Troubleshooting
Watch three signals weekly:
| Signal | Target Value | Alert Condition |
|---|---|---|
| Average node CPU utilization | 55-70% | Below 40% |
| Average node memory utilization | 55-70% | Below 40% |
| Pending-pod duration | < 60 seconds | > 2 minutes |
If utilization drops below 40%, raise pod requests to their VPA targets and lower NodePool limits.cpu to force consolidation. If pending times stretch past two minutes, check whether Karpenter is constrained by the instance-family list; adding a fallback family such as m6i unblocks capacity during regional Spot contention. Track the Karpenter karpenter_nodes_created and karpenter_nodes_terminated counters to spot thrashing, which signals a consolidation window set too aggressively.
Node CPU <40% or pending pods >2 minutes? We fix both.
The signals above tell you when something's wrong. But configuring the right thresholds and alerts requires expertise.
We help you:
- Create EKS cost dashboards – Node utilization, pending pod duration
- Set up anomaly alerts – Drift detection before waste accumulates
- Monitor Karpenter thrashing – Consolidation window too aggressive?
- Join labels to Cost Explorer – GDPR, workload-class, cost-center tags
Conclusion
EKS right-sizing cost optimization ties pod resource accuracy to node-type selection and continuous consolidation. European teams that combine VPA recommendations, Graviton3 NodePools, and Savings Plans coverage routinely cut worker-node bills by 30-50% while improving scheduling reliability and lowering the carbon footprint of workloads in eu-central-1.
EaseCloud runs right-sizing engagements for European EKS operators, from VPA rollout to Graviton migration and multi-arch CI pipelines. Book a consultation with EaseCloud to baseline your cluster and design a data-driven rightsizing plan.
Frequently Asked Questions
How long should VPA run before applying recommendations?
VPA Run Duration Guidance
- Minimum: 14 days to capture weekday and weekend patterns
- Seasonal businesses: 30 days before trusting the targets
Is Graviton compatible with all container images?
- Multi-architecture images cover most mainstream runtimes (Node.js, Go, Python, Java)
- Check third-party dependencies for arm64 builds before migrating
- A few legacy libraries remain x86-only
When should I prefer Fargate over right-sized EC2 nodes?
| Workload Type | Recommendation | Rationale |
|---|---|---|
| Spiky, low-volume workloads | Fargate | Node overhead outweighs per-vCPU premium |
| Steady, high-utilization services | Right-sized EC2 + Savings Plans | 40-60% cheaper than Fargate |
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.