Monitor Kubernetes Costs with Prometheus and Grafana
Track and optimize Kubernetes costs using Prometheus metrics, Grafana dashboards, and custom queries for namespace-level cost attribution and resource optimization.

TL;DR
- Prometheus + Grafana for per-namespace, per-service cost visibility (cloud bills only show cluster totals).
- Calculate pod cost by actual usage, not requests –
(Pod CPU Usage / Node CPU Capacity) × Node Hourly Cost. - Key metrics: CPU/memory usage + pod/node metadata + cloud pricing APIs.
- Open source tools: Kubecost (standard), OpenCost (CNCF), or custom stack.
- Labels are critical –
team,service,environment→ without them you can't allocate costs. - Alert on anomalies: cost spikes >50% above average, idle nodes, pods using <10% of requested resources.
Kubernetes cost monitoring with Prometheus and Grafana represents a critical cost optimization opportunity for cloud-native organizations. Strategic implementation of best practices can reduce expenses by 40-70% while maintaining performance and reliability. This guide explores proven strategies including resource optimization, automation, monitoring approaches, and architectural patterns that deliver measurable cost savings.
Cloud cost optimization requires systematic attention to resource provisioning, utilization monitoring, and continuous improvement processes. Organizations often discover significant waste through over-provisioned resources, idle capacity, and inefficient architectures. Modern cloud platforms provide powerful optimization tools, but successful implementation demands methodical analysis and incremental changes validated through metrics.
Understanding Cost Drivers
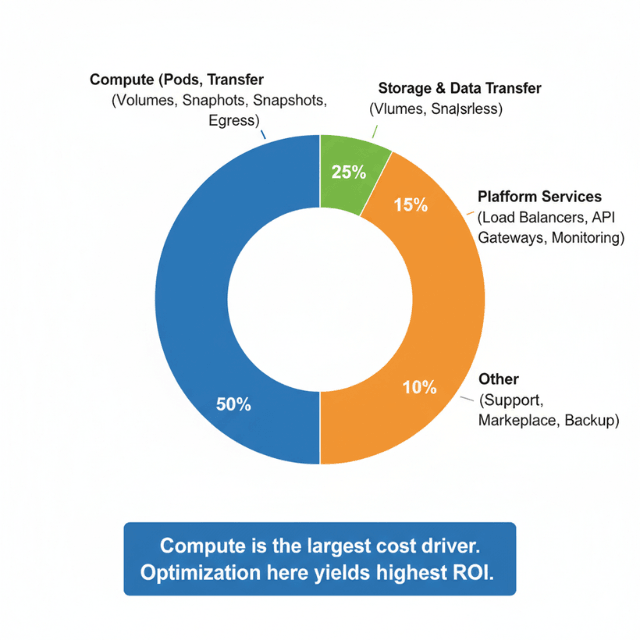
Primary cloud cost drivers includes:
| Cost Category | Percentage of Cloud Budget | Examples |
|---|---|---|
| Compute resources | 40-60% | EC2 instances, containers, serverless functions |
| Storage and data transfer | 20-30% | Block storage, object storage, egress fees |
| Platform services | Remainder | Load balancers, monitoring, API gateways, managed databases |
Identifying specific cost sources enables targeted optimization efforts with maximum impact.
Resource over-provisioning stems from conservative capacity planning where teams allocate excess capacity without validation. Development environments often mirror production sizing despite lower requirements. Legacy migration patterns frequently perpetuate on-premises sizing without cloud-native optimization.
Hidden costs accumulate through:
- Data transfer fees
- API requests
- Monitoring overhead
- Backup storage
These seemingly minor expenses compound at scale, potentially representing 15-25% of total cloud spending for large deployments.
You Can't Optimize What You Can't See.
Over-provisioning wastes 40-60% of cloud budgets. But without proper monitoring, you won't know where.
We provide the observability stack to find and fix waste:
- Prometheus for resource metrics (CPU, memory, network per pod)
- Grafana dashboards for utilization visualization
- Cost allocation through Kubernetes labels and tags
- Anomaly detection for unexpected spending spikes
Free 30-min assessment: We'll review your current monitoring setup and identify visibility gaps.
Optimization Strategies
Right-sizing resources prevents wasteful over-provisioning by matching instance types and sizes to actual workload requirements. Analyze utilization metrics over representative periods identifying instances running below 40% average utilization. These represent downsizing opportunities where smaller configurations maintain adequate performance.
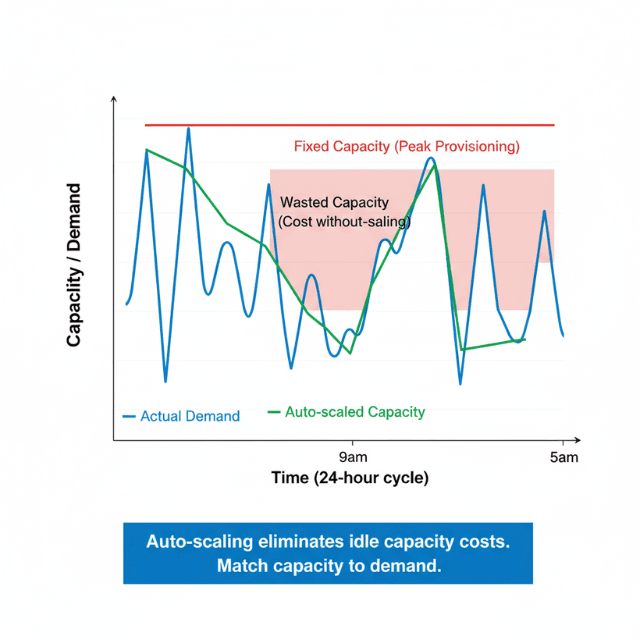
Automated scaling adjusts capacity dynamically based on demand, eliminating idle resources during low-traffic periods while maintaining performance during peaks. Configure auto-scaling policies with:
- Configure with appropriate thresholds
- Set proper cooldown periods
- Define scaling increments that prevent both resource waste and performance degradation
Pricing Model Comparison
| Pricing Model | Discount Range | Best For |
|---|---|---|
| Reserved capacity / Savings plans | 40-70% | Predictable baseline workloads |
| On-demand | 0% discount (full price) | Variable load, unpredictable traffic |
| Spot instances | Varies (can be 60-90% off) | Fault-tolerant, interruptible workloads |
Strategy: Combine reserved capacity for baseline + on-demand or spot for variable load maximizing savings while maintaining flexibility.
Implementation Best Practices
Review cycles for continuous optimization.
| Review Type | Frequency | Focus |
|---|---|---|
| Quarterly assessments | Every 3 months | Cost trends, utilization patterns, optimization recommendations |
| Monthly spot-checks | Every month | Highest-cost resources to catch obvious inefficiencies early |
| Continuous monitoring | Real-time | Anomaly detection between formal review cycles |
Tagging strategies:
- Enable accurate cost allocation by project, team, environment, or customer
- Implement consistent tagging policies enforced through automation
- Tag-based cost reports provide visibility into spending patterns
- Supports optimization prioritization and accountability
Monitoring and alerting catch cost anomalies before significant budget impact. Configure budget thresholds with automated alerts at 80%, 90%, and 100% of planned spending. Anomaly detection identifies unusual patterns indicating configuration errors or unexpected usage growth.
Monitoring and Metrics
Track key performance indicators including:
| Metric | Purpose |
|---|---|
| Total monthly cloud spending | Overall cost baseline |
| Cost per transaction or user | Unit economics normalization |
| Resource utilization percentages | Identify optimization candidates |
| Waste identified through optimization reviews | Measure improvement progress |
Cost per unit metrics normalize spending against business outcomes. Calculate:
- Cost per customer
- Cost per transaction
- Cost per API call
- Cost per other relevant unit economics
This reveals whether cost growth aligns with business value or represents inefficiency requiring optimization.
Utilization dashboards visualize resource consumption across compute, storage, and platform services. Highlight under-utilized resources as optimization candidates. Track utilization trends ensuring optimizations don't overcorrect causing performance issues.
Conclusion
Effective cost optimization balances expense reduction against performance, reliability, and agility requirements. Systematic approaches achieve 40-70% savings through right-sizing, automated scaling, commitment-based discounts, and architectural improvements. Implement regular review cycles, comprehensive monitoring, and gradual changes validated through metrics.
Success requires ongoing discipline rather than one-time optimization projects, with continuous monitoring catching new inefficiencies as workloads evolve. Establish cost awareness as part of engineering culture where optimization considerations inform architectural decisions alongside functionality and performance requirements.
Frequently Asked Questions
How much cost reduction is realistic through optimization?
Most organizations achieve 40-60% reduction through systematic optimization. Exact savings depend on current efficiency levels, with poorly optimized environments offering greater improvement potential. Even well-managed clouds typically find 20-30% savings through continuous optimization practices.
How often should I review and optimize cloud costs?
Conduct detailed quarterly reviews analyzing trends, utilization patterns, and optimization recommendations. Implement monthly spot-checks of highest-cost resources. Establish automated monitoring and alerting for continuous anomaly detection between formal review cycles.
What metrics should I track to measure optimization success?
Track total monthly cloud spending, cost per business unit (transaction, user, customer), resource utilization percentages, and savings realized from optimization initiatives. Monitor trends over time validating that optimization efforts deliver sustained cost reduction without performance degradation.
Summarize this post with:
