Database Selection for Cloud-Native Applications
Choose the right database for cloud-native applications. Compare PostgreSQL, MongoDB, and Redis for consistency, scalability, and query patterns. Includes production-ready Kubernetes configurations.

TL;DR
- Start with PostgreSQL as default: Strong ACID, complex queries, JSON support, mature ecosystem. Use for financial systems, e-commerce, and any workload needing consistency.
- Add MongoDB when schema flexibility or horizontal scaling matters: Document model handles hierarchical data (catalogs, profiles). Schema evolves without migrations. Sharding for scale. Use for content management and rapid iteration.
- Add Redis for sub-millisecond performance: In-memory for caching, sessions, rate limiting, leaderboards, pub/sub. Ephemeral—not a primary database.
- Decision framework:
- PostgreSQL: multi-table transactions, complex queries, full-text search, geospatial
- MongoDB: hierarchical data, schema flexibility, massive scale/sharding
- Redis: caching, sessions, rate limiting, real-time leaderboards
- Avoid polyglot unless necessary: Each DB multiplies ops overhead. Start with PostgreSQL. Add MongoDB when schema flexibility becomes critical. Add Redis for performance paths.
- Managed vs. self-hosted:
- Managed (RDS, Atlas): less ops, easier compliance, higher cost → good for production
- Self-hosted on K8s: more control, lower cost at scale, needs operator expertise → good for dev/cost-sensitive
- Hybrid: managed production, self-hosted dev/staging
Choosing the right database for cloud-native applications requires balancing consistency requirements, query patterns, scalability needs, and operational complexity. No single database excels at every workload. Understanding each database type's strengths and limitations enables informed architecture decisions.
PostgreSQL: The Reliable Workhorse
PostgreSQL excels at transactional workloads requiring strong consistency, complex queries, and relational integrity. ACID compliance ensures data correctness across concurrent operations. Advanced features including JSON support, full-text search, and geospatial queries make PostgreSQL versatile.
When to choose PostgreSQL:
- Applications requiring multi-table transactions
- Complex analytical queries with joins and aggregations
- Financial systems demanding consistency guarantees
- Applications with structured data and clear relationships
- Systems needing mature ecosystem and tooling
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: orders-postgres
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:15.5
storage:
size: 200Gi
storageClass: fast-ssd
postgresql:
parameters:
max_connections: "500"
shared_buffers: "2GB"
effective_cache_size: "6GB"
maintenance_work_mem: "512MB"
checkpoint_completion_target: "0.9"
wal_buffers: "16MB"
random_page_cost: "1.1"
effective_io_concurrency: "200"
work_mem: "10MB"
min_wal_size: "1GB"
max_wal_size: "4GB"
PostgreSQL shines for e-commerce platforms handling orders, inventory, and customer data. The database maintains referential integrity between orders and line items, customers and addresses, products and categories. Complex queries join across tables to generate reports without sacrificing consistency.
JSON support enables schema flexibility without abandoning relational benefits. Store semi-structured data in JSONB columns while maintaining strong consistency for core business entities.
CREATE TABLE products (
id UUID PRIMARY KEY,
name VARCHAR(200) NOT NULL,
category VARCHAR(100),
base_price DECIMAL(10,2) NOT NULL,
attributes JSONB,
created_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_product_attributes ON products USING GIN (attributes);
-- Query products with specific attributes
SELECT id, name, base_price
FROM products
WHERE attributes @> '{"color": "blue", "size": "large"}';
-- Update nested JSON attributes
UPDATE products
SET attributes = jsonb_set(attributes, '{specs,weight}', '"2.5kg"')
WHERE id = '123e4567-e89b-12d3-a456-426614174000';
Connection pooling becomes critical at scale. PostgreSQL creates separate backend processes for each connection, consuming memory. PgBouncer pools connections efficiently.
apiVersion: apps/v1
kind: Deployment
metadata:
name: pgbouncer
spec:
replicas: 3
template:
spec:
containers:
- name: pgbouncer
image: pgbouncer/pgbouncer:1.21.0
env:
- name: DATABASES_HOST
value: "postgres-rw.production.svc.cluster.local"
- name: DATABASES_PORT
value: "5432"
- name: DATABASES_DBNAME
value: "production"
- name: PGBOUNCER_POOL_MODE
value: "transaction"
- name: PGBOUNCER_MAX_CLIENT_CONN
value: "10000"
- name: PGBOUNCER_DEFAULT_POOL_SIZE
value: "25"
MongoDB: Document Flexibility
MongoDB stores data as flexible JSON-like documents. Schema evolution happens naturally without migrations. Horizontal scaling through sharding distributes data across multiple servers.
When to choose MongoDB:
- Rapidly evolving data models
- Hierarchical or nested data structures
- Applications requiring horizontal scalability
- Content management systems
- Real-time analytics on semi-structured data
- Geospatial applications
apiVersion: mongodbcommunity.mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: content-mongodb
spec:
members: 3
type: ReplicaSet
version: "6.0.5"
statefulSet:
spec:
volumeClaimTemplates:
- metadata:
name: data-volume
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: fast-ssd
resources:
requests:
storage: 500Gi
additionalMongodConfig:
storage.wiredTiger.engineConfig.cacheSizeGB: 8
net.maxIncomingConnections: 1000
Document model fits naturally for content platforms. A blog post document contains all related data - content, metadata, comments, tags - eliminating joins.
// Blog post document structure
{
_id: ObjectId("507f1f77bcf86cd799439011"),
title: "Cloud-Native Database Patterns",
slug: "cloud-native-database-patterns",
author: {
id: ObjectId("507f191e810c19729de860ea"),
name: "Jane Developer",
email: "jane@example.com"
},
content: "Full article content...",
tags: ["cloud-native", "databases", "kubernetes"],
publishedAt: ISODate("2025-11-25T10:30:00Z"),
status: "published",
metadata: {
views: 1523,
readTime: 8,
featured: true
},
comments: [
{
id: ObjectId("507f1f77bcf86cd799439012"),
author: "Developer Bob",
content: "Great article!",
createdAt: ISODate("2025-11-25T12:15:00Z"),
likes: 5
}
]
}
Aggregation pipeline enables complex data transformations and analytics.
// Calculate popular tags
db.posts.aggregate([
{ $match: { status: "published" } },
{ $unwind: "$tags" },
{ $group: {
_id: "$tags",
count: { $sum: 1 },
avgViews: { $avg: "$metadata.views" }
}},
{ $sort: { count: -1 } },
{ $limit: 10 }
]);
// User activity report
db.posts.aggregate([
{ $match: {
publishedAt: {
$gte: ISODate("2025-11-01"),
$lt: ISODate("2025-12-01")
}
}},
{ $group: {
_id: "$author.id",
authorName: { $first: "$author.name" },
postCount: { $sum: 1 },
totalViews: { $sum: "$metadata.views" }
}},
{ $sort: { totalViews: -1 } }
]);
Sharding distributes data across multiple servers for horizontal scaling.
// Enable sharding for database
sh.enableSharding("contentdb");
// Shard posts collection by author region
sh.shardCollection("contentdb.posts", { "author.region": 1, _id: 1 });
// Shard users collection by user ID
sh.shardCollection("contentdb.users", { _id: "hashed" });
Redis: High-Performance Caching
Redis provides in-memory data structures with sub-millisecond latency. Use cases include caching, session storage, real-time analytics, message queuing, and leaderboards.
When to choose Redis:
- Applications requiring microsecond response times
- Session management for web applications
- Real-time leaderboards and counters
- Rate limiting and throttling
- Pub/sub messaging
- Temporary data with TTL expiration
apiVersion: redis.redis.opstreelabs.in/v1beta1
kind: RedisCluster
metadata:
name: app-cache
spec:
clusterSize: 6
kubernetesConfig:
image: redis:7.0
redisConfig:
maxmemory: "4gb"
maxmemory-policy: "allkeys-lru"
save: "900 1 300 10"
storage:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
Caching strategies reduce database load and improve response times.
import redis
import json
from functools import wraps
redis_client = redis.Redis(
host='app-cache.production.svc.cluster.local',
port=6379,
decode_responses=True
)
def cache_result(ttl=300):
"""Decorator to cache function results in Redis"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
# Generate cache key from function name and arguments
cache_key = f"{func.__name__}:{str(args)}:{str(kwargs)}"
# Try to get from cache
cached = redis_client.get(cache_key)
if cached:
return json.loads(cached)
# Execute function and cache result
result = func(*args, **kwargs)
redis_client.setex(
cache_key,
ttl,
json.dumps(result)
)
return result
return wrapper
return decorator
@cache_result(ttl=600)
def get_product_details(product_id):
"""Fetch product from database with caching"""
# Database query (expensive)
product = db.query(
"SELECT * FROM products WHERE id = %s",
(product_id,)
).fetchone()
return product
Session storage maintains user state across requests.
class SessionManager:
def __init__(self, redis_client):
self.redis = redis_client
self.ttl = 3600 # 1 hour session timeout
def create_session(self, user_id, session_data):
"""Create new session"""
session_id = str(uuid.uuid4())
key = f"session:{session_id}"
self.redis.hset(key, mapping={
'user_id': user_id,
'created_at': datetime.utcnow().isoformat(),
**session_data
})
self.redis.expire(key, self.ttl)
return session_id
def get_session(self, session_id):
"""Retrieve session data"""
key = f"session:{session_id}"
session = self.redis.hgetall(key)
if session:
# Refresh TTL on access
self.redis.expire(key, self.ttl)
return session
def update_session(self, session_id, updates):
"""Update session fields"""
key = f"session:{session_id}"
self.redis.hset(key, mapping=updates)
self.redis.expire(key, self.ttl)
Rate limiting protects APIs from abuse.
class RateLimiter:
def __init__(self, redis_client):
self.redis = redis_client
def check_rate_limit(self, user_id, limit=100, window=60):
"""Check if user is within rate limit"""
key = f"ratelimit:{user_id}"
# Increment counter
current = self.redis.incr(key)
# Set expiration on first request
if current == 1:
self.redis.expire(key, window)
# Check if over limit
if current > limit:
ttl = self.redis.ttl(key)
raise RateLimitExceeded(
f"Rate limit exceeded. Try again in {ttl} seconds"
)
return {
'allowed': True,
'remaining': limit - current,
'reset_in': self.redis.ttl(key)
}
Decision Framework
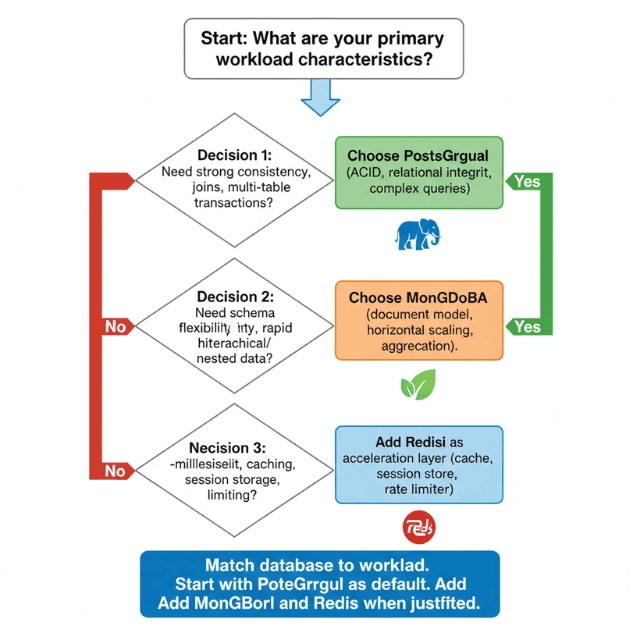
Start with PostgreSQL for most applications. Strong consistency, ACID guarantees, and mature tooling make it a safe default choice. Migrate to specialized databases only when specific requirements emerge.
Add MongoDB when schema flexibility becomes critical or when modeling hierarchical data. Content management, user profiles with variable attributes, and product catalogs with diverse specifications benefit from document flexibility.
Introduce Redis for performance-critical paths. Caching frequently accessed data, storing sessions, and implementing rate limiting reduce load on primary databases.
Avoid premature optimization. Begin with a single database type. Add complexity only when clear benefits justify operational overhead. Each additional database technology increases operational burden through monitoring, backup, security patching, and expertise requirements.
Made a Database Choice? Now Build the Rest of Your Cloud-Native Stack.
The decision framework above helps you pick the right database. But that's just one piece of cloud-native architecture.
We help startups build complete cloud-native products:
- Microservices architecture – Decompose monoliths into scalable services
- API design & implementation – REST, GraphQL, gRPC that actually work
- Container orchestration – Kubernetes deployments that don't break
- Full-stack development – From database to frontend, we handle it all
Polyglot Persistence Considerations
Running multiple database types requires careful planning.
Operational overhead multiplies with each technology. Teams need expertise in PostgreSQL, MongoDB, Redis operations, backup strategies, performance tuning, and troubleshooting.
Consistency challenges emerge when data spans databases. Implement saga patterns or event sourcing to maintain correctness across database boundaries.
Cost implications include infrastructure resources, licensing, and operational complexity. Consolidating on fewer technologies reduces total cost of ownership.
Monitoring complexity increases with diverse databases. Implement unified observability covering all database types.
# Prometheus ServiceMonitor for multiple databases
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: database-metrics
spec:
selector:
matchLabels:
monitoring: enabled
endpoints:
- port: postgres-metrics
interval: 30s
path: /metrics
- port: mongodb-metrics
interval: 30s
path: /metrics
- port: redis-metrics
interval: 30s
path: /metrics
Managed Services vs Self-Hosted
Managed database services reduce operational burden. AWS RDS, Azure Database, Google Cloud SQL handle backups, patching, and high availability. Managed services cost more but free teams to focus on application development.
Self-hosted databases on Kubernetes provide full control and potentially lower costs. Operators automate much operational complexity. Consider self-hosting when regulatory requirements mandate it, when deep customization is needed, or when cost optimization is critical.
Hybrid approaches balance control and convenience. Run development databases self-hosted on Kubernetes. Use managed services for production. Or run primary databases managed while self-hosting read replicas for analytics workloads.
Database selection fundamentally impacts application architecture, operational complexity, and system characteristics. Choose thoughtfully based on requirements, team capabilities, and long-term maintenance considerations. Start simple, measure actual needs, and evolve architecture based on real-world usage patterns.
Conclusion
- Database selection is one of the most consequential architecture decisions for cloud-native applications
- The modern approach is polyglot persistence: using the right database for each workload while managing operational complexity
- PostgreSQL remains the reliable workhorse for transactional data requiring consistency and complex queries
- MongoDB provides schema flexibility and horizontal scaling for document-oriented workloads
- Redis delivers sub-millisecond performance for caching and real-time data
- Start with PostgreSQL as your default. Add MongoDB and Redis only when specific requirements justify operational overhead
- Always run databases on Kubernetes with operators to automate backups, failover, and scaling
- The goal isn't to minimize database count; it's to match each workload to the right tool while maintaining operational discipline
FAQs
1. When should I choose PostgreSQL over a NoSQL database like MongoDB?
Choose PostgreSQL when you need strong consistency, complex joins, or multi-table transactions. If your schema is well-defined and relationships matter (e.g., orders ↔ line items ↔ customers ↔ inventory), PostgreSQL's ACID guarantees and relational model are perfect.
Also choose PostgreSQL for financial systems (account balances must never be inconsistent), reporting/analytics (complex aggregations across tables), and any workload where data integrity is non-negotiable. MongoDB's document model is great for flexibility, but PostgreSQL now has excellent JSONB support you can often get both relational rigor and document flexibility in one database.
2. Can MongoDB replace PostgreSQL for transactional applications?
Generally, no. MongoDB has added multi-document ACID transactions (as of version 4.0+), but PostgreSQL's transaction guarantees, foreign key constraints, and complex join optimization remain superior for relational workloads.
MongoDB shines for hierarchical data where you denormalize within documents (e.g., a blog post with embedded comments). Use MongoDB when schema evolution speed matters more than complex relational queries. Use PostgreSQL when data consistency across multiple entity types is critical.
3. Is Redis a primary database?
Not really. Redis is an in-memory data store. While it offers persistence (RDB snapshots, AOF logs), its primary value is speed sub-millisecond latency for caching, sessions, real-time counters, and pub/sub. Using Redis as a primary database risks data loss on failure (even with persistence, recovery takes time) and lacks query flexibility.
The proven pattern: use PostgreSQL or MongoDB as the source of truth, and Redis as an acceleration layer (cache, session store, rate limiter). They complement each other Redis makes your primary database faster by offloading high-throughput, low-latency workloads.
Summarize this post with:
