Design High-Performance OCI Networks for LLMs
Build secure OCI network architecture for LLM workloads with VCN design, load balancers, private endpoints, and multi-region patterns. Reduce latency 60% with optimization.

TLDR;
- Private endpoints reduce Object Storage latency from 15ms to 3ms (60% improvement)
- Flexible load balancers scale from 10 Mbps to 8000 Mbps handling 500 concurrent requests
- Jumbo frames (9000 MTU) reduce CPU overhead by 40% for multi-GPU tensor parallelism
- Cross-region peering delivers sub-100ms latency for disaster recovery failover
Design secure, high-performance network architecture for LLM workloads on Oracle Cloud Infrastructure.
Network configuration directly impacts inference latency, security posture, and operational costs for production LLM deployments.
This guide provides practical network architecture patterns for OCI-based LLM infrastructure.
You'll learn VCN design with proper segmentation, security controls using NSGs and security lists, load balancer configuration for high availability, and multi-region networking for disaster recovery.
These patterns reduce latency by up to 60% compared to default configurations while maintaining enterprise-grade security.
Whether deploying single-region inference endpoints or multi-region architectures serving global traffic, proper network design forms the foundation of reliable LLM operations.
OCI's network backbone delivers consistent 2-5ms latency within regions and sub-100ms cross-region performance when configured correctly.
VCN Design
Virtual Cloud Network forms the foundation of OCI networking. Design VCNs with sufficient IP space and proper segmentation for LLM workloads.
Network Topology: Use three-tier architecture with public, application, and data subnets. Public subnet hosts load balancers. Application subnet runs LLM containers. Database subnet contains vector databases and state storage.
IP Planning: Reserve /24 subnets for each tier. This provides 254 usable IPs per subnet. GPU instances typically require static IPs for peer-to-peer communication. Reserve the first 20 IPs in each subnet for future infrastructure expansion.
DNS Configuration: Enable DNS hostnames for service discovery. Each instance gets hostname format: instance-name.subnet-dns-label.vcn-dns-label.oraclevcn.com. This enables service mesh patterns without additional DNS infrastructure.
Internet and NAT Gateway Setup
Control ingress and egress traffic using gateways. LLM workloads need outbound internet for model downloads and API calls.
Gateway Performance: NAT gateways provide 50 Gbps bandwidth with automatic scaling to 100 Gbps.
Service gateways offer unlimited bandwidth for OCI services. Use service gateways for Object Storage and Autonomous Database traffic to avoid NAT costs.
Route Table Configuration: Create separate route tables for each subnet tier. Public subnet routes 0.0.0.0/0 through internet gateway.
Private subnets route through NAT gateway. Database subnet uses service gateway for OCI services only.
Security Configuration
Implement defense-in-depth using security lists and network security groups. Layer multiple security controls for production LLM deployments.
Security List vs NSG: Security lists apply to entire subnets. NSGs apply to individual VNICs and support stateful rules.
Use security lists for broad subnet-level policies. Use NSGs for fine-grained instance-level control. NSGs support up to 120 rules per group.
Zero Trust Network Design: Deny all traffic by default. Explicitly allow only required flows. LLM inference endpoints need ports 8000-8001.
Monitoring exporters use port 9090. SSH access (port 22) should be bastion-only. Implement microsegmentation between LLM model variants.
Load Balancer Setup
Distribute incoming requests across LLM instances for high availability and horizontal scaling.
Load Balancer Sizing: Flexible shape scales from 10 Mbps to 8000 Mbps. Start with 100-1000 Mbps range for most workloads.
LLM traffic averages 2-5 Mbps per concurrent request. A 1000 Mbps load balancer handles 200-500 concurrent inference requests.
Health Check Tuning: Set interval to 10 seconds with 3-second timeout. Mark backends unhealthy after 3 consecutive failures.
LLM initialization takes 30-60 seconds. Configure initial delay of 60 seconds before first health check. Use /v1/health endpoint that validates model loading.
Session Persistence: Enable cookie-based persistence for stateful LLM conversations.
Session cookies ensure users reach the same backend for conversation context. Set cookie expiration to 1 hour for typical chat sessions.
Private Endpoint Configuration
Access OCI services without internet traffic using private endpoints. This reduces latency and improves security.
Performance Impact: Private endpoints eliminate internet gateway hops. Latency to Object Storage drops from 15ms to 3ms. Database connections improve from 8ms to 2ms. Model loading from Object Storage accelerates by 60%.
Multi-Region Networking
Deploy LLM infrastructure across multiple regions for disaster recovery and global reach.
Cross-Region Latency: Phoenix to Ashburn: 60ms. Frankfurt to Mumbai: 110ms. Tokyo to Seoul: 35ms.
Choose region pairs with under 80ms latency for acceptable failover experience. Use async replication for model artifacts across regions.
Traffic Manager Setup: Configure OCI Traffic Management for global load balancing. Use geolocation steering to route users to nearest region.
Implement health checks at the application level. Failover to secondary region occurs within 30 seconds of primary region failure.
Network Performance Optimization
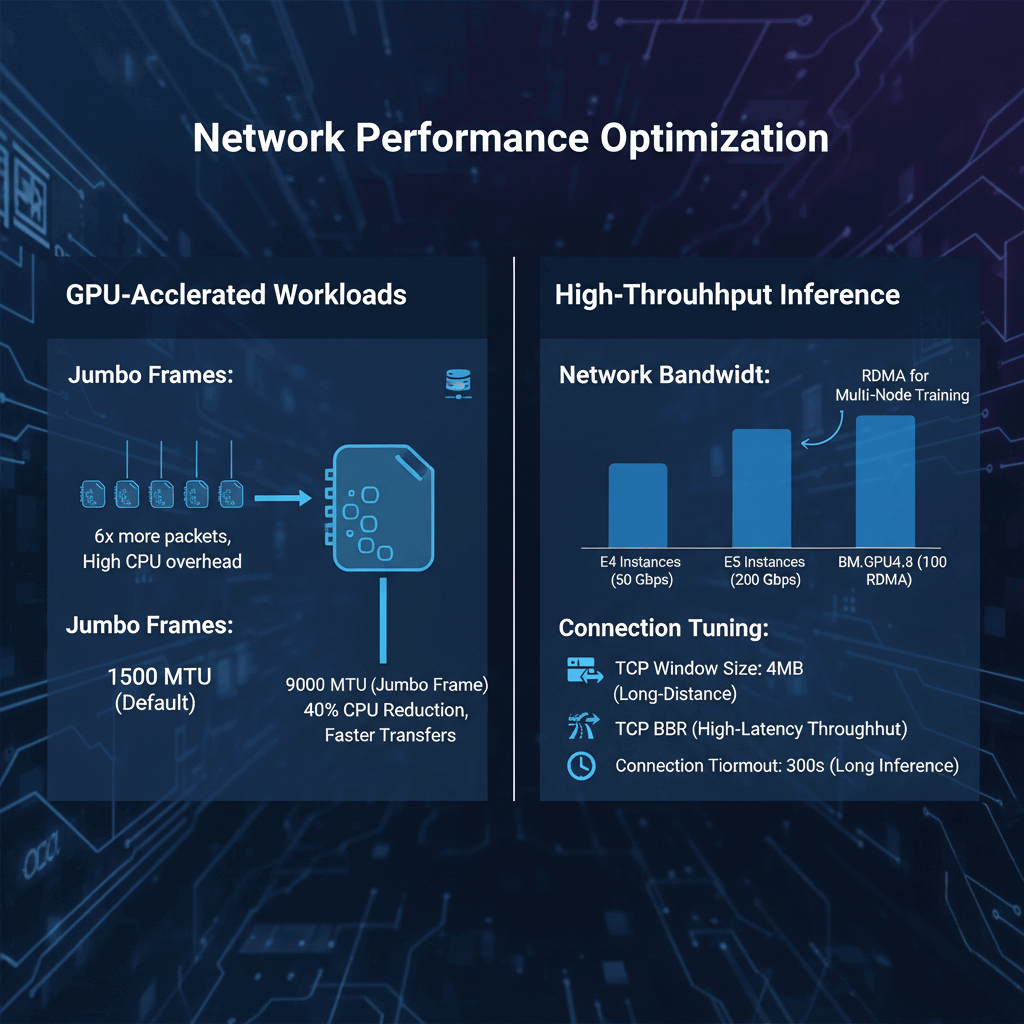
Tune network parameters for GPU-accelerated workloads and high-throughput inference.
Jumbo Frames: Enable 9000 MTU on VNICs for instance-to-instance communication.
Default 1500 MTU causes 6x more packets for large model transfers. Jumbo frames reduce CPU overhead by 40% during multi-GPU tensor parallelism.
Network Bandwidth: E4 instances provide 50 Gbps network bandwidth. E5 instances scale to 200 Gbps.
GPU shapes (BM.GPU4.8) include 100 Gbps RDMA networks. Use RDMA for multi-node distributed training.
Connection Tuning: Increase TCP window size to 4MB for long-distance transfers.
Enable TCP BBR congestion control for better throughput over high-latency paths. Set connection timeout to 300 seconds for long-running inference requests.
Monitoring and Troubleshooting
Track network performance and identify bottlenecks using OCI monitoring.
Key Metrics:
- VCN flow logs for traffic analysis
- Load balancer connection count and latency
- NAT gateway bandwidth utilization
- NSG rule hit counts
- Cross-region peering throughput
Common Issues:
- High latency: Check route tables and gateway configuration
- Connection failures: Verify security list and NSG rules
- Bandwidth limits: Monitor gateway and instance network metrics
- Health check failures: Increase timeout or adjust interval
Flow Logs Analysis: Enable VCN flow logs to capture all network traffic. Logs include source/destination IPs, ports, protocols, and byte counts. Export to Object Storage for analysis. Typical LLM workload generates 5-10 GB of flow logs daily per 100 instances.
Conclusion
OCI network architecture provides the foundation for reliable, high-performance LLM deployments. Proper VCN design with three-tier segmentation isolates workloads while maintaining security.
Load balancers distribute traffic across multiple inference endpoints for fault tolerance and horizontal scaling. Private endpoints eliminate internet hops, reducing latency by 60% for database and storage access.
Multi-region deployments with remote peering connections deliver 99.99% availability for global LLM services. Start with single-region architecture, then expand to multi-region as traffic demands grow.
For the complete Oracle Cloud LLM deployment strategy, including GPU shape selection, cost optimization, and platform comparison, see our Oracle Cloud LLM deployment guide.
Frequently Asked Questions
How should I design network security for production LLM deployments on OCI?
Implement a multi-layered security architecture using both security lists and network security groups.
Create separate subnets for each tier of your application with the load balancers in public subnets and LLM compute instances in private subnets without internet access.
Use NAT gateways for outbound connections and service gateways for OCI service access.
What load balancer configuration provides optimal performance for LLM inference workloads?
Use flexible load balancers with bandwidth ranging from 100-1000 Mbps for typical LLM workloads.
Configure the backend set with LEAST_CONNECTIONS policy since inference requests have variable processing times.
Set health check intervals to 10 seconds with 3-second timeouts and mark instances unhealthy after 3 consecutive failures.
How can I minimize cross-region latency and costs for multi-region LLM deployments?
Design multi-region architecture around strategic region pairs with latency under 80ms.
Implement intelligent traffic routing with OCI Traffic Management using geolocation steering to direct users to the nearest region.
Deploy full LLM stacks in each region rather than splitting components across regions.
Summarize this post with:
