The Role of AI and Machine Learning in Performance Optimization
Leverage AI/ML for performance optimization: anomaly detection, predictive scaling, root cause analysis, and automated remediation. Reduce MTTR with AIOps.

TLDR;
- ML learns normal behavior – static thresholds miss context (80% CPU fine at peak, bad at 3 AM). Detects anomalies based on patterns, not arbitrary numbers.
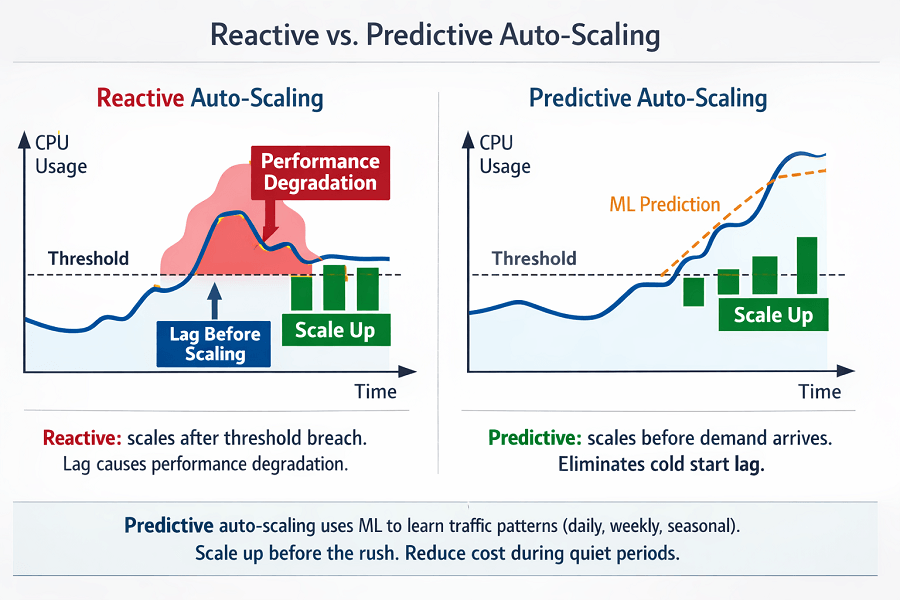
- Predictive scaling forecasts demand – scale before traffic arrives. Predict SLA violations before they happen.
- Automated root cause analysis correlates changes (deployments, configs) to incidents. Cuts investigation hours to minutes.
- Start with low-risk: anomaly detection and capacity prediction first. Validate recommendations before automation. High-risk changes (query rewrites, architecture) need human review.
Artificial intelligence and machine learning are transforming performance optimization. Traditional monitoring relies on static thresholds set by humans. ML-powered systems learn normal behavior and detect anomalies automatically. Predictive models forecast problems before they occur. AI assistants help debug issues faster. These capabilities don't replace engineering judgment—they amplify it, handling the scale and speed that humans cannot.
AI and ML for Anomaly Detection
Static thresholds miss context. 80% CPU might be normal during peak hours but alarming at midnight. ML learns these patterns.
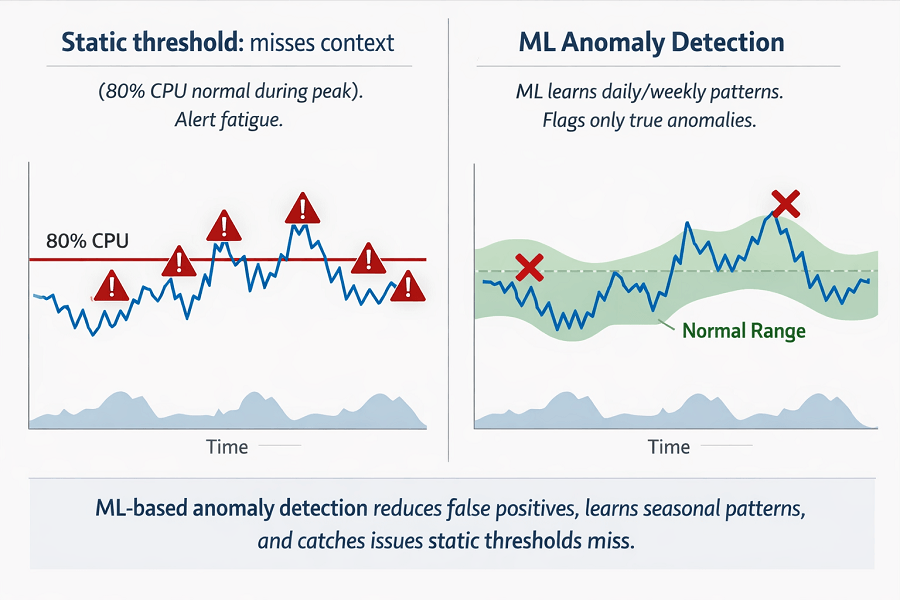
Time-series anomaly detection models normal behavior. Algorithms learn daily and weekly patterns. Deviations from learned patterns trigger alerts.
from prophet import Prophet
import pandas as pd
# Train anomaly detection model
df = pd.DataFrame({
'ds': timestamps,
'y': latency_values
})
model = Prophet(
interval_width=0.95,
changepoint_prior_scale=0.05
)
model.fit(df)
# Predict and find anomalies
future = model.make_future_dataframe(periods=24, freq='H')
forecast = model.predict(future)
# Points outside confidence interval are anomalies
anomalies = df[
(df['y'] > forecast['yhat_upper']) |
(df['y'] < forecast['yhat_lower'])
]
Multivariate analysis detects complex issues. Single metrics might look normal. Combinations reveal problems.
Unsupervised learning finds unknown patterns. No need to define what's abnormal. Algorithms identify unusual behavior automatically.
Clustering groups similar behaviors. Requests with similar patterns cluster together. Outlier requests stand out.
Seasonal decomposition separates signal from noise. Daily patterns, weekly patterns, and trends separate. True anomalies become visible.
Predictive Performance Analytics
Capacity prediction forecasts resource needs. ML models project traffic growth. Plan capacity before hitting limits.
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
# Features: day of week, hour, recent traffic, etc.
X = prepare_features(historical_data)
y = historical_data['cpu_utilization']
model = RandomForestRegressor(n_estimators=100)
model.fit(X, y)
# Predict next week's utilization
future_X = prepare_features(future_dates)
predicted_utilization = model.predict(future_X)
# Alert if predicted to exceed threshold
if max(predicted_utilization) > 0.85:
alert("Capacity threshold expected in coming week")
Degradation prediction catches problems early. Performance gradually worsens before failure. Trend analysis predicts when thresholds will breach.
SLA risk prediction enables proactive response. Predict probability of SLA violation. Take action before violations occur.
User impact prediction estimates blast radius. How many users affected by this degradation? Prioritize by predicted impact.
Lead time optimization balances cost and risk. Predict how far in advance to scale. Minimize cost while avoiding capacity problems.
Automated Root Cause Analysis
Correlation analysis finds related events. When latency spikes, what else changed? Automated correlation reduces investigation time.
Dependency mapping shows cascade paths. Which upstream service caused this failure? Trace dependencies automatically.
def analyze_root_cause(incident_time, affected_service):
# Find metrics that changed around incident time
window_start = incident_time - timedelta(minutes=30)
window_end = incident_time + timedelta(minutes=30)
all_metrics = get_all_metrics(window_start, window_end)
# Score each metric by correlation with incident
correlations = []
for metric in all_metrics:
score = calculate_correlation(metric, incident_time)
if score > 0.7:
correlations.append({
'metric': metric.name,
'service': metric.service,
'score': score
})
return sorted(correlations, key=lambda x: x['score'], reverse=True)
Change correlation identifies deployment impacts. Performance degraded after deployment. Which change caused it?
Log pattern analysis identifies error causes. ML clusters similar error messages. Identifies new error patterns.
Topology-aware analysis considers architecture. Failures propagate through systems. Understanding topology improves root cause identification.
Natural language summaries explain findings. AI generates human-readable explanations. Reduces time to understand problems.
Intelligent Auto-Scaling
Predictive auto-scaling scales before demand. ML predicts traffic patterns. Scale up before the rush.
# Kubernetes predictive auto-scaling
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
updatePolicy:
updateMode: Auto
resourcePolicy:
containerPolicies:
- containerName: api
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 4
memory: 4Gi
Traffic pattern learning improves over time. Daily and weekly patterns become more accurate. Seasonal events learned from history.
Cost optimization balances performance and spending. ML finds optimal instance types. Right-size based on actual usage patterns.
Workload classification routes to appropriate resources. Different workload types need different resources. ML classifies requests for optimal routing.
Multi-resource optimization considers trade-offs. CPU, memory, and network together. Optimize the whole system, not individual metrics.
Query and Code Optimization
SQL query optimization suggests improvements. ML analyzes query patterns and performance. Recommends indexes and rewrites.
-- AI-suggested index based on query patterns
-- Analysis shows frequent queries filtering on customer_id with date range
CREATE INDEX idx_orders_customer_date
ON orders (customer_id, order_date DESC)
WHERE status = 'active';
Automatic index management adapts to workloads. Create indexes for common queries. Remove unused indexes automatically.
Code hotspot identification finds slow code. ML analyzes profiles across requests. Identifies functions that consistently slow performance.
LLM-assisted debugging helps investigate issues. Describe the problem in natural language. Get relevant troubleshooting suggestions.
Configuration tuning optimizes settings. ML finds optimal JVM settings, connection pool sizes, and buffer configurations.
Regression detection catches performance changes. Automated comparison of builds. Alert on performance regressions before release.
AIOps Platforms
AIOps combines AI with IT operations. Unified platform for monitoring, analysis, and automation.
Event correlation reduces noise. Thousands of events become a few incidents. Related alerts grouped automatically.
Incident prioritization based on impact. ML predicts business impact of incidents. Prioritize response accordingly.
Automated remediation handles common issues. Known problems trigger automated fixes. Reduces human intervention for routine issues.
# Automated remediation example
def handle_incident(incident):
# ML classifies incident type
incident_type = classifier.predict(incident.features)
if incident_type == 'memory_exhaustion':
# Known remediation
restart_service(incident.service)
scale_up(incident.service)
notify_team(incident, "Automated remediation applied")
else:
# Unknown type, escalate to humans
page_oncall(incident)
Knowledge base integration provides context. Connect to documentation and past incidents. AI suggests relevant information.
Continuous learning improves over time. Models retrain on new data. Accuracy improves with experience.
AIOps: event correlation, automated remediation, incident prioritization. We implement the platform.
Thousands of events become a few incidents. Known problems trigger automated fixes. ML predicts business impact for prioritization. Models retrain continuously on new data.
We help you:
- Deploy AIOps platforms – Unified monitoring, analysis, and automation
- Correlate related alerts – Reduce noise, group by root cause
- Implement automated remediation – Fix known issues without human intervention
- Integrate knowledge bases – Connect to documentation and past incidents
Practical Implementation
Start with anomaly detection. Relatively low risk. Augments existing alerting. Provides immediate value.
Build on existing monitoring data. ML needs data to learn. Use existing metrics and logs.
Validate ML recommendations. Automated suggestions require review. Build trust before automation.
# Staged rollout of ML recommendations
def apply_optimization(recommendation):
if recommendation.confidence < 0.8:
log.info(f"Low confidence recommendation: {recommendation}")
return
if recommendation.type == 'index_creation':
# Low risk, can apply automatically
apply_index(recommendation)
elif recommendation.type == 'query_rewrite':
# Medium risk, A/B test first
ab_test(recommendation)
elif recommendation.type == 'architecture_change':
# High risk, create ticket for review
create_ticket(recommendation)
Monitor ML system performance. Models can degrade. Track accuracy and retrain when needed.
Combine AI with human judgment. AI handles scale and speed. Humans provide context and make decisions.
Plan for edge cases. ML works on patterns. Novel situations may need human intervention.
| Use Case | Maturity | Risk | Starting Point |
|---|---|---|---|
| Anomaly detection | High | Low | Augment alerting |
| Capacity prediction | High | Low | Forecast reports |
| Root cause analysis | Medium | Low | Investigation assist |
| Auto-scaling | Medium | Medium | Review predictions |
| Automated remediation | Medium | High | Start with low-risk |
| Query optimization | Medium | Medium | Recommendation only |
Conclusion
AI and ML are not replacing performance engineers, they are amplifying them. Static thresholds and manual analysis cannot keep pace with modern distributed systems. ML learns normal behavior, detects anomalies before they become outages, predicts capacity needs, and correlates root causes across thousands of signals.
The key is pragmatic implementation: start with low-risk applications like anomaly detection and capacity forecasting. Validate ML recommendations before automation. Use AIOps to reduce noise and automate routine remediation. The future of performance optimization is not human OR machine, it's human AND machine working together. AI handles scale and speed. Humans provide context and judgment.
FAQs
1. Can AI completely replace manual performance tuning?
No. AI excels at pattern recognition, anomaly detection, and prediction. But AI lacks business context, understands edge cases poorly, and can't make strategic trade-offs (e.g., cost vs performance vs time-to-market). The winning pattern: AI handles scale (analyzing millions of data points) and automation (routine optimizations); humans handle validation, strategy, and novel situations.
2. How much historical data does ML need for accurate anomaly detection?
Typically 2-4 weeks of data to capture weekly patterns. Less data (a few days) works for simple threshold replacement. Seasonal patterns (holidays, month-end) require multiple cycles. Start with 30 days of high-resolution metrics (1-5 min granularity). Retrain models monthly or quarterly. Without sufficient data, use static thresholds as fallback.
3. What's the risk of automated AI remediation?
Automated remediation can make mistakes: misdiagnose root cause, apply wrong fix, or create cascading failures. Mitigations: start with "recommendation only" mode for high-risk actions (architecture changes, query rewrites). Use confidence thresholds (e.g., only auto-remediate when confidence >90%). Deploy automated rollback. For production, human approval for any change that could impact availability. AIOps should augment, not bypass, incident response processes.
Summarize this post with:
