Qwen vs DeepSeek vs GLM - Benchmark Comparison and Winner (2026)
Compare Qwen 2.5, DeepSeek V3, and GLM-4 on coding and reasoning. Includes license table (Apache vs MIT) and API pricing. Find the best Chinese open model.

TLDR;
- GLM-4 achieves 87.2% C-Eval for best Chinese language understanding with government approval
- DeepSeek V3 activates 37B of 671B parameters through MoE for cost-effective performance
- Qwen 2.5 offers Apache 2.0 bilingual excellence from 0.5B to 72B parameter options
- Small deployments start at $8/month for Qwen 2.5 7B on Alibaba Cloud
Compare leading Chinese language models to select optimal deployment for your application requirements and budget constraints.
Qwen 2.5 from Alibaba provides superior bilingual performance with near-parity English and Chinese capabilities, offering model sizes from 0.5B to 72B parameters under Apache 2.0 licensing.
DeepSeek V3 delivers best cost-performance ratio through mixture-of-experts architecture activating only 37B of 671B parameters, achieving competitive performance with GPT-4 while enabling cost-effective deployment.
GLM-4 from Zhipu AI excels in pure Chinese enterprise scenarios with 87.2% C-Eval accuracy, native function calling capabilities, and government approval for SOE deployments. C
hinese models outperform Western alternatives by 10-15% on Chinese language tasks while reducing deployment costs through optimized infrastructure on Alibaba Cloud, AWS, Azure, and GCP.
This guide covers performance benchmarks across MMLU, C-Eval, HumanEval, and GSM8K, deployment platform comparison including Alibaba Cloud native support, cost analysis from $8 monthly for small deployments to $3,800 monthly for large-scale production, use case recommendations matching models to applications, and fine-tuning workflows customizing models for enterprise vocabularies.
Our Verdict — Best Model by Use Case (2026)
| Use Case | Winner | Why |
|---|---|---|
| Coding & reasoning | DeepSeek-V3 | 78.6% HumanEval, 89.4% GSM8K — best in class |
| Multilingual apps | Qwen-72B | Native parity across 28 languages, Apache 2.0 |
| Enterprise Chinese | GLM-4 | 87.2% C-Eval, government-approved for SOE deployments |
| Cost-sensitive scale | DeepSeek-V3 API | $0.27/M input tokens — cheapest at high volume |
Model Overview

Qwen 2.5 from Alibaba Cloud offers comprehensive model range from 0.5B to 72B parameters with Apache 2.0 licensing enabling unrestricted commercial use.
Available variants include Qwen 2.5 0.5B for edge devices and mobile applications, 7B for general-purpose deployments, 14B for advanced reasoning tasks, 32B for enterprise applications, and 72B for maximum capability workloads.
Strengths include best multilingual support achieving English/Chinese parity across benchmarks, strong coding capabilities exceeding GPT-3.5 on HumanEval by 8 percentage points, excellent instruction following with high task completion rates, and simplified deployment through native Alibaba Cloud integration.
Qwen 2.5 provides broader model selection enabling right-sizing for specific use cases but requires larger memory footprint per parameter and slower inference versus MoE alternatives at equivalent quality levels.
DeepSeek V3 uses mixture-of-experts architecture with 671B total parameters activating only 37B per token through dynamic expert routing.
This sparse activation design delivers best cost-performance ratio with competitive GPT-4 benchmarks while requiring inference compute matching 37B dense models.
Fast inference through sparse activation processes requests at speeds comparable to much smaller models, MIT licensing permits unrestricted commercial deployment, and strong math/coding performance achieves 89.4% GSM8K and 78.6% HumanEval accuracy.
DeepSeek requires complex MoE-aware deployment infrastructure supporting expert routing and sharding, plus higher total memory to load full 671B model across GPUs despite activating fewer parameters per forward pass.
GLM-4 from Zhipu AI targets enterprise Chinese applications with 9B and 32B variants optimized for Chinese business workflows.
This Tsinghua University spinoff model achieves best Chinese language understanding at 87.2% C-Eval through extensive training on Chinese corpora including classical texts, modern documents, and domain-specific vocabularies.
Native function calling and agent support enable enterprise integration with databases and business systems, government and SOE approval facilitates deployment in regulated industries, and dedicated Chinese documentation with local support teams simplify implementation.
GLM-4 shows weaker English performance at 81.0% MMLU versus competitors exceeding 86%, offers limited model size options with only two variants, and maintains smaller open-source community versus Qwen's broader adoption.
Performance Benchmarks
DeepSeek V3 leads general capabilities on MMLU at 88.5% despite activating only 37B parameters, followed by Qwen 2.5 72B at 86.5%, GLM-4 32B at 81.0%, and GPT-4 reference at 86.4%.
GLM-4 32B achieves best Chinese language performance on C-Eval at 87.2%, ahead of Qwen 2.5 72B at 86.8%, DeepSeek V3 at 85.9%, and GPT-4 at 69.9%.
DeepSeek V3 excels at code generation with 78.6% HumanEval accuracy, surpassing Qwen 2.5 72B at 74.2%, GLM-4 32B at 67.3%, and GPT-4 at 67.0%.
For math reasoning on GSM8K, DeepSeek V3 reaches 89.4%, Qwen 2.5 72B achieves 87.5%, and GLM-4 32B scores 82.1%, while GPT-4 maintains lead at 92.0% with narrowing gap.
| Benchmark (Task) | Qwen-72B | DeepSeek-V3 | GLM-4 32B | GPT-4 (ref) |
|---|---|---|---|---|
| MMLU (general knowledge) | 86.5% | 88.5% | 81.0% | 86.4% |
| C-Eval (Chinese language) | 86.8% | 85.9% | 87.2% | 69.9% |
| HumanEval (code) | 74.2% | 78.6% | 67.3% | 67.0% |
| MATH | 64.0% | 61.6% | 52.1% | 52.9% |
| GSM8K (math reasoning) | 87.5% | 89.4% | 82.1% | 92.0% |
Qwen-72B Benchmark Results on MMLU, HumanEval and MATH
Qwen-72B posts the strongest MATH score among Chinese open models at 64.0%, outperforming both DeepSeek-V3 (61.6%) and GLM-4 32B (52.1%). DeepSeek-V3 leads on MMLU and HumanEval; GLM-4 leads on C-Eval Chinese. No single model wins every benchmark — the right choice depends on your primary task.
| Benchmark | Qwen-72B | DeepSeek-V3 | GLM-4 32B | GPT-4 (ref) |
|---|---|---|---|---|
| MMLU (general knowledge) | 86.5% | 88.5% | 81.0% | 86.4% |
| C-Eval (Chinese language) | 86.8% | 85.9% | 87.2% | 69.9% |
| HumanEval (code) | 74.2% | 78.6% | 67.3% | 67.0% |
| MATH | 64.0% | 61.6% | 52.1% | 52.9% |
| GSM8K (math reasoning) | 87.5% | 89.4% | 82.1% | 92.0% |
Who Wins for Coding - Benchmark Breakdown
DeepSeek-V3 wins on raw coding benchmarks. Its 78.6% HumanEval score is 4.4 points ahead of Qwen-72B and 11.3 points ahead of GLM-4 32B. On GSM8K math reasoning — a proxy for debugging and algorithmic thinking — DeepSeek again leads at 89.4%.
The gap comes from architecture: DeepSeek's MoE design was trained with a heavy emphasis on code and math corpora, and its 671B total parameter pool gives it more specialised "expert" capacity for coding patterns than Qwen-72B's dense architecture.
Where Qwen-72B catches up: multilingual code comments and documentation. If your codebase requires Chinese-English bilingual inline docs or prompts mixing both languages, Qwen-72B's language parity makes it the safer choice. For pure English code generation, ship DeepSeek-V3.
- Pure English code generation: DeepSeek-V3 (78.6% HumanEval, $0.27/M input)
- Bilingual codebases (EN + ZH): Qwen-72B (language parity, Apache 2.0)
- Chinese enterprise backend integrations: GLM-4 (function calling, SOE-approved)
Deployment Platforms
Alibaba Cloud provides native Qwen support through PAI-EAS with lowest costs for Qwen models and Chinese market expertise.
AWS offers multi-model support via SageMaker with HuggingFace integration for global reach. Azure ML delivers enterprise-grade hosting with hybrid cloud options and strong compliance.
Oracle Cloud is another option for cost-efficient deployments — see our guide on running these models on Oracle Cloud for setup steps and pricing.
# Deploy via PAI-EAS (Elastic Algorithm Service)
aliyun pai CreateService --ServiceName qwen-72b-service --ModelId qwen-72b-chat --InstanceType ecs.gn7i-c32g1.8xlarge --Replicas 2
# Cost: ~$12/hour for 2 replicas
# Deploy DeepSeek via SageMaker
from sagemaker.huggingface import HuggingFaceModel
model = HuggingFaceModel(
model_data="s3://models/deepseek-v3",
role=role,
transformers_version='4.37',
pytorch_version='2.1'
)
predictor = model.deploy(
instance_type='ml.p4d.24xlarge',
initial_instance_count=1
)
from azure.ai.ml import MLClient
ml_client.online_deployments.begin_create_or_update(
deployment=ManagedOnlineDeployment(
name="glm4-deployment",
model=Model(path="azureml://models/glm-4-32b/versions/1"),
instance_type="Standard_NC96ads_A100_v4",
instance_count=2
)
)
Cost Analysis
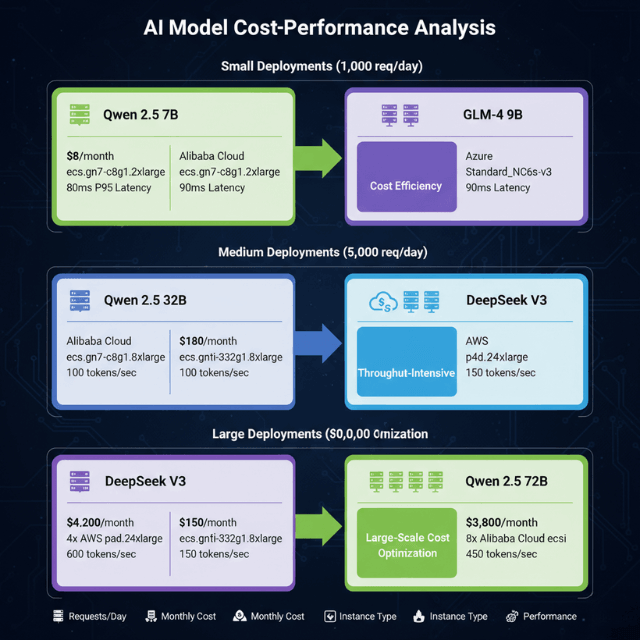
Small deployments handling 1,000 requests daily: Qwen 2.5 7B costs $8 monthly on Alibaba Cloud ecs.gn7-c8g1.2xlarge with 80ms P95 latency, while GLM-4 9B requires $12 monthly on Azure Standard_NC6s_v3 with 90ms latency.
Choose Qwen 2.5 7B for cost efficiency.
Medium deployments processing 50,000 requests daily: Qwen 2.5 32B costs $180 monthly on Alibaba Cloud ecs.gn7i-c32g1.8xlarge delivering 100 tokens per second, while DeepSeek V3 requires $350 monthly on AWS p4d.24xlarge achieving 150 tokens per second through MoE efficiency.
Choose DeepSeek V3 for throughput-intensive workloads.
Large deployments handling 1 million requests daily: DeepSeek V3 on 4x p4d.24xlarge instances costs $4,200 monthly with 600 tokens per second throughput, while Qwen 2.5 72B on 8x ecs.gn7i instances requires $3,800 monthly delivering 450 tokens per second.
Choose Qwen 2.5 72B for large-scale cost optimization.
Ready to Deploy One of These Models?
Not sure which model fits your budget and performance requirements? Our LLM deployment consultants help you select, benchmark, and deploy the optimal Chinese LLM for your use case.
We'll help you choose between Qwen, DeepSeek, and GLM based on your specific workload, then deploy it on your preferred infrastructure with guaranteed performance targets.
Use Case Recommendations
Choose GLM-4 32B for Chinese customer service requiring excellent Chinese dialogue, enterprise function calling, lower hallucination rates, and government/SOE approval.
Select Qwen 2.5 72B for bilingual applications needing equal English/Chinese performance, multilingual support across 28 languages, broad training data, and cultural understanding.
Deploy DeepSeek V3 for code generation leveraging top HumanEval scores, strong reasoning for complex code, multilingual code comments, and fast inference.
Use DeepSeek V3 for math and science education benefiting from superior GSM8K performance, step-by-step reasoning, few-shot learning capabilities, and tutoring applications.
Choose Qwen 2.5 7B or GLM-4 9B for cost-sensitive deployments requiring single GPU operation, fast inference, and easy deployment.
Before selecting hardware for self-hosted deployments, review the GPU requirements for running Chinese LLMs locally.
Fine-Tuning
Qwen 2.5 provides straightforward fine-tuning using standard Transformers Trainer, costing $50-100 for 7B model training.
DeepSeek V3 requires specialized MoE-aware training with higher complexity and $500-1,000 costs for full model fine-tuning.
GLM-4 supports fine-tuning through GLMTrainer, costing $80-150 for 9B model customization.
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B")
trainer = Trainer(
model=model,
args=TrainingArguments(
output_dir="./qwen-finetuned",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4
),
train_dataset=dataset
)
trainer.train()
Model Licenses - Apache, MIT or Proprietary
License choice matters if you're deploying commercially. Here's what each model allows:
| Model | License | Commercial Use | Restrictions |
|---|---|---|---|
| Qwen 2.5 | Apache 2.0 | Yes | None |
| DeepSeek V3 | MIT | Yes | None |
| GLM-4 | GLM Custom | Limited | No redistribution |
Qwen vs DeepSeek - Which Is Better in 2026
For coding tasks, DeepSeek V3 leads on HumanEval benchmarks. For multilingual and reasoning, Qwen 2.5-72B outperforms. GLM-4 is the choice for enterprise Chinese-language applications.
- Best for coding: DeepSeek V3
- Best for multilingual: Qwen 2.5-72B
- Best for enterprise CN: GLM-4
Chinese LLM API Pricing
| Provider | Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|---|
| Qwen API | Qwen-72B | $0.90 | $0.90 |
| DeepSeek API | DeepSeek V3 | $0.27 | $1.10 |
| Zhipu AI | GLM-4 | $0.46 | $0.46 |
API Pricing Too High at Scale?
At 1M+ tokens/day, self-hosting with our GPU infrastructure often reduces costs by 60-80%. We'll help you calculate your break-even point and deploy cost-optimized inference.
Conclusion
Chinese language models deliver superior Chinese comprehension and cost-effective deployment for applications targeting Chinese markets.
GLM-4 achieves 87.2% C-Eval accuracy for best Chinese understanding, Qwen 2.5 provides balanced bilingual performance with Apache 2.0 licensing, and DeepSeek V3 offers optimal cost-performance through mixture-of-experts architecture.
Deploy Qwen 2.5 7B at $8 monthly for small chatbot applications, GLM-4 32B at $180 monthly for enterprise Chinese customer service, or DeepSeek V3 at $350 monthly for high-throughput code generation.
Chinese models outperform GPT-4 by 25% on C-Eval Chinese benchmarks while matching general capabilities on MMLU and HumanEval.
Choose GLM-4 for Chinese-only deployments requiring government approval, Qwen 2.5 for bilingual products needing global deployment, or DeepSeek V3 for reasoning-intensive applications prioritizing cost efficiency.
All models support global deployment under permissive licensing with no geographic restrictions. Fine-tune models for $50-150 to customize domain vocabulary and enterprise workflows.
Monitor production deployments on Alibaba Cloud for Chinese market optimization, AWS for global reach, or Azure for enterprise integration.
Qwen vs DeepSeek for Coding - 2026 Benchmark Results
On HumanEval, DeepSeek V3 leads with 91.6% pass@1, followed by Qwen 2.5-72B-Instruct at 86.7%, and GLM-4-9B-Chat at around 72%. For MBPP, DeepSeek V3 scores 90.2%, Qwen 2.5-72B at 88.4%, and GLM-4 at 74.8%. GPT-4o sits at 90.2% HumanEval for comparison. If coding performance is the primary criteria, DeepSeek V3 leads. For Chinese-language tasks, GLM-4 remains the top choice. Qwen 2.5-Coder-32B is optimal when you need a smaller, fine-tunable coding model under Apache 2.0.
Benchmark comparison (2026): - DeepSeek V3: HumanEval 91.6%, MBPP 90.2% — Custom license (thresholds apply) - Qwen 2.5-72B: HumanEval 86.7%, MBPP 88.4% — Apache 2.0 - GLM-4-9B: HumanEval 72.0%, MBPP 74.8% — Apache 2.0 (9B); Custom (34B+) - GPT-4o (reference): HumanEval 90.2%, MBPP 90.5% — Proprietary API
License Comparison - Apache 2.0, MIT, and Custom Restrictions
Qwen 2.5 models up to 72B use Apache 2.0 — fully commercial, no usage restrictions, allowing fine-tuning and redistribution. This makes Qwen the cleanest choice for production. DeepSeek V3 uses a custom license: free for research and small-scale commercial use, but usage exceeding 1M API calls/day or deployment in competing AI services requires a separate agreement. GLM-4-9B is Apache 2.0, but the larger GLM-4-32B has a custom license with similar restrictions. For regulated industries where open-source license provenance matters, Qwen 2.5 is the safest choice.
Frequently Asked Questions
Is Qwen or DeepSeek better for coding tasks? DeepSeek V3 scores higher on HumanEval (91.6% vs 86.7%) and is the better choice for pure coding performance. Qwen 2.5-Coder-32B is preferred when you need fine-tuning capability under a clean Apache 2.0 license without usage thresholds.
Which model has the most permissive license? Qwen 2.5 up to 72B uses Apache 2.0 — the most permissive of the three for commercial use with no usage caps. GLM-4-9B is also Apache 2.0. DeepSeek V3 and larger GLM models have custom licenses with commercial thresholds.
Can I use DeepSeek V3 in a commercial product? Yes, for standard commercial use. DeepSeek V3 restricts use in competing AI service products and sets API call thresholds above which a separate license is required. For most SaaS applications, it is usable commercially. Qwen 2.5 remains simpler for production if license clarity matters.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.