Why Manual AWS Operations Don't Scale (A Common DevOps Problem)
Learn why manual AWS operations fail at scale and how to transition to automation. Practical guidance on IaC, CI/CD, and building repeatable infrastructure workflows.

TLDR;
- Manual operations become liabilities at scale — human error stays constant while complexity grows
- Problems: Config drift, slow recovery, no audit trails, security misconfigs
- Transition: Infrastructure as Code, automated CI/CD, repeatable workflows
- Start with automation fundamentals before advanced practices
Your deployment process works. Someone SSHs into the server, pulls the latest code, restarts services, and confirms the application responds. It takes fifteen minutes and requires careful attention, but it works. Until it does not.
Manual AWS operations that function at small scale become liabilities as teams and traffic grow. This article explains when and why manual processes break down, what scalable alternatives look like, and how to transition from click-ops to sustainable automation.
What Manual AWS Operations Look Like in Growing Teams
Click-based infrastructure changes through the AWS Console feel productive. Creating an EC2 instance, modifying security groups, or adjusting RDS parameters provides immediate feedback. But these changes exist only in the current state of your infrastructure with no record of why they happened.
Manual deployments and rollbacks depend on individual knowledge. The engineer who performed the last deployment knows the sequence of commands, the configuration files that need updates, and the services that require restarts. That knowledge lives in their head rather than in code.
Ad-hoc fixes in production solve immediate problems while creating long-term debt. Emergency patches, quick configuration changes, and temporary workarounds accumulate into infrastructure that nobody fully understands and everyone fears touching.
Why Manual Operations Feel Fine at the Beginning
A small infrastructure footprint stays manageable. Two EC2 instances, one RDS database, and a handful of S3 buckets fit comfortably in any engineer's mental model. The AWS Console provides adequate visibility, and mistakes affect limited blast radius.
Low traffic and limited risk reduce consequences of errors. When downtime affects a few hundred users rather than tens of thousands, the pressure to prevent mistakes is lower. Recovery from problems requires minutes rather than triggering incident response procedures.
Fast early-stage execution favors speed over process. Startups rightly prioritize shipping features over building perfect infrastructure. According to Y Combinator guidance, early-stage teams should do things that do not scale while finding product-market fit. The problem arises when temporary practices become permanent habits.
Core Reasons Manual AWS Operations Don't Scale
Human Error Becomes a Major Risk
Inconsistent changes accumulate across environments. When different engineers make manual modifications, production slowly drifts from staging, and staging drifts from development. Bugs appear that cannot be reproduced because nobody knows the exact configuration of each environment.
No repeatable processes means no reliable recovery. After a production incident, can you rebuild your infrastructure exactly as it was? Manual operations rarely leave sufficient documentation, and the AWS Shared Responsibility Model makes clear that customers are responsible for their own configuration management.
Slower Deployments and Increased Downtime
Manual steps cause delays that compound with frequency. A thirty-minute deployment performed once weekly costs four hours monthly. The same deployment performed daily costs ten hours monthly. As release frequency increases, manual overhead becomes unsustainable.
Hard-to-debug failures extend incidents. When deployments involve multiple manual steps, determining which step failed requires investigation. Automated pipelines produce clear logs showing exactly where failures occurred.
No Infrastructure Consistency Across Environments
Development, staging, and production drift apart over time. Features work in development but fail in staging because someone manually added a dependency that does not exist elsewhere. Staging tests pass but production deploys fail because security groups differ.
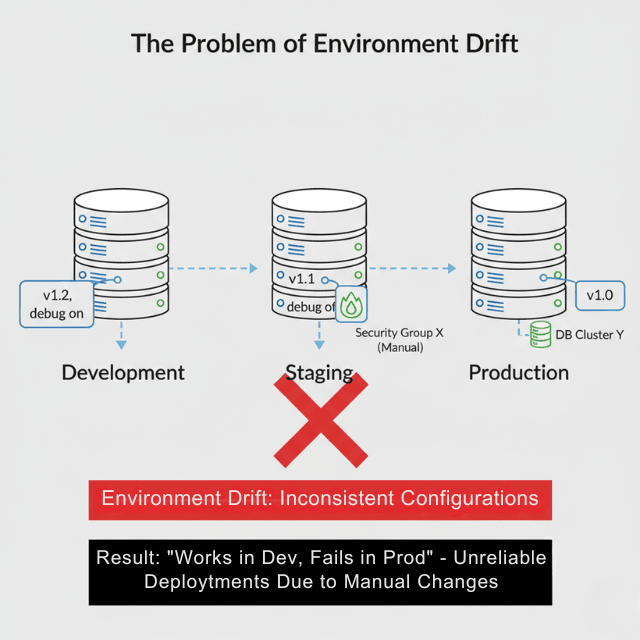
Configuration mismatches create ghost bugs. The DORA research program consistently finds that elite DevOps teams maintain environment parity through automation. Manual processes cannot maintain this consistency at scale.
Lack of Visibility and Auditability
No change history means no learning from incidents. When problems occur, teams cannot determine what changed and when. Post-mortem analysis becomes speculation rather than investigation.
Difficult incident reviews impede improvement. European enterprises increasingly require change audit trails for compliance purposes, particularly under GDPR Article 32 security requirements. Manual changes cannot provide the documentation that auditors expect.
How Manual AWS Operations Block Team Velocity
Slowed feature releases result from deployment friction. When releasing code requires coordination, careful timing, and dedicated engineer attention, teams naturally batch changes into larger, riskier releases. Smaller, more frequent deployments become impractical.
Increased operational load consumes engineering capacity. The 2024 Accelerate State of DevOps Report found that high-performing teams spend 30% less time on unplanned work than low performers. Manual operations generate more unplanned work through incidents and firefighting.
Distracted engineers from product work affects competitive position. Every hour spent on manual operations is an hour not spent building features that differentiate your product. Competitors with better automation ship faster.
Cost and Security Risks of Manual AWS Operations
Over-provisioned resources waste money when nobody tracks actual utilization. Manual provisioning defaults to "bigger is safer," creating instances and databases sized for imagined peaks rather than actual usage.
Missed cost optimization opportunities accumulate. Reserved Instances, Savings Plans, and right-sizing recommendations from AWS Compute Optimizer require systematic review that manual operations rarely include.
Security misconfigurations expose vulnerabilities. Manual security group changes, IAM policy modifications, and encryption settings create inconsistencies that attackers exploit. The Verizon Data Breach Investigations Report consistently identifies misconfiguration among top causes of cloud security incidents.
When Manual AWS Operations Start Breaking Down
Increased deployment frequency reveals process bottlenecks. Moving from weekly to daily releases, or from daily to continuous deployment, exposes manual steps that cannot scale. What worked occasionally becomes impossible at higher frequency.
Multiple environments and regions multiply complexity exponentially. Managing production in eu-west-1 manually is possible. Adding staging, development, and disaster recovery in eu-central-1 quadruples the operational burden.
A growing user base raises stakes for every change. When ten thousand users depend on your service, the consequences of deployment mistakes justify investment in preventing them.
What Scalable AWS DevOps Looks Like Instead
Infrastructure as Code (IaC) captures your entire environment in version-controlled definitions. Terraform, AWS CloudFormation, and AWS CDK provide different approaches to the same goal: infrastructure that you can review, test, and reproduce exactly.
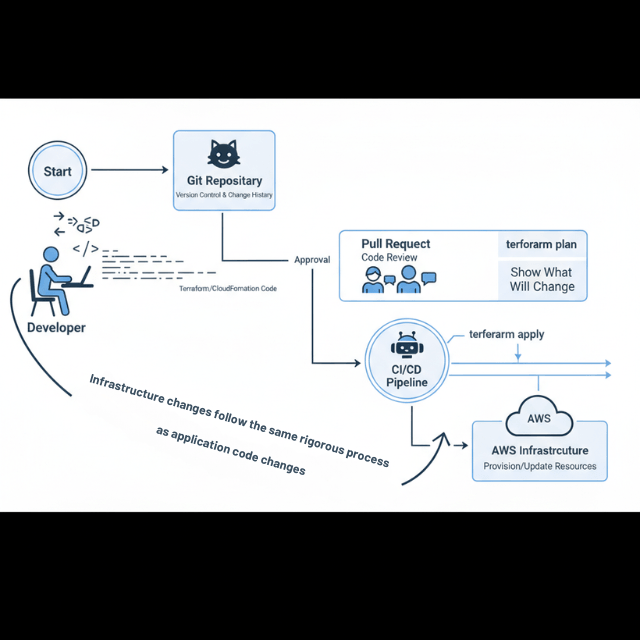
Automated CI/CD pipelines remove human intervention from standard deployments. Code changes trigger builds, tests run automatically, and successful builds deploy to appropriate environments without manual steps.
Consistent, repeatable workflows ensure that every deployment follows the same path. No forgotten steps, no environment-specific variations, no reliance on individual knowledge.
How to Transition Away from Manual AWS Operations
Identify repeatable tasks as automation candidates. Deployments, environment provisioning, database backups, and log rotation all follow patterns that automation handles better than humans.
Start with automation fundamentals before pursuing advanced practices. Basic CI/CD that runs tests and deploys on merge provides enormous value. GitOps, progressive delivery, and chaos engineering can wait until foundations are solid.
A gradual migration approach reduces risk. Automate one workflow, verify it works, then move to the next. Attempting complete transformation simultaneously invites failure.
How EaseCloud Helps Eliminate Manual AWS DevOps Problems
AWS DevOps automation replaces manual processes with reliable pipelines. EaseCloud implements CI/CD workflows tailored to your application architecture and team capabilities, not one-size-fits-all templates.
Infrastructure as Code implementation captures your environment in maintainable definitions. Terraform modules, CloudFormation templates, or CDK constructs provide the reproducibility that manual operations lack.
Ongoing operational support ensures automation remains effective as your needs evolve. European startups access AWS-certified engineers who understand both technical requirements and regional compliance considerations.
Final Thoughts
Automation is a requirement, not a luxury, for growing teams. Manual AWS operations that served you well at small scale become obstacles as traffic, team size, and deployment frequency increase. The question is not whether to automate, but when and how.
Starting early costs less than retrofitting later. Every manual process you automate today saves compound time tomorrow. Every automated deployment reduces risk and frees engineering capacity for product work.
Ready to eliminate manual operations? Contact EaseCloud for a free infrastructure assessment and learn how European startups are building scalable DevOps practices on AWS.
Frequently Asked Questions
Why don't manual AWS operations scale?
Human error rates stay constant while complexity grows. What works with simple infrastructure becomes unreliable with multiple environments, frequent deployments, and growing teams.
At what stage should teams automate AWS operations?
Before manual processes become painful. Ideally, basic CI/CD should exist before your first production launch. The longer you wait, the more difficult and risky the transition becomes.
Can small teams use Infrastructure as Code?
Yes. Tools like Terraform and AWS CDK have learning curves, but even simple IaC provides value through reproducibility and documentation. Start with critical resources and expand coverage over time.
Does automation reduce AWS costs?
Often yes. Automated environments can scale down during low-traffic periods, test environments can shut down overnight, and consistent configurations prevent over-provisioning. The indirect savings from reduced engineering time frequently exceed direct infrastructure savings.
Should startups get DevOps help early?
For most startups, external expertise accelerates early DevOps implementation. The cost of fractional support typically delivers better ROI than either DIY learning curves or premature full-time hires.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.