How Third-Party Integrations Can Slow Down Your SaaS Application
Learn how third-party integrations impact SaaS performance. Discover defensive patterns, async processing, caching strategies, and vendor selection to minimize latency from external dependencies.

TL;DR
- Set timeouts (1-5s) – Never wait indefinitely for external calls.
- Use circuit breakers – Stop calling failing services; fast-fail during outages.
- Move non-critical calls to background – Analytics, email, logging don't need to block users.
- Parallelize independent calls – Don't do sequential what you can do concurrent.
- Exponential backoff + jitter for retries – Prevents retry storms (3 retries = 4x traffic).
- Cache reference data – Exchange rates, catalogs with stale-while-revalidate.
- Monitor p95/p99 latency per integration – What you don't measure, you can't fix.
Modern SaaS applications rarely operate in isolation. Payment processing, email delivery, analytics, authentication, and countless other functions depend on third-party services. These integrations extend your application's capabilities but introduce performance dependencies beyond your control. When external services slow down or fail, your application inherits their problems.
The Hidden Cost of Integration Dependencies
Hidden cost of integration dependencies shown in the table below:
| Problem | Example Impact |
|---|---|
| Latency adds up | Payment gateway at 500ms → checkout takes at least 500ms |
| Sequential calls compound | Three services at 300ms each = 900ms unavoidable delay |
| External availability becomes your availability | Auth provider downtime = users cannot log in |
| Performance variance | Average 100ms, but occasional requests take seconds |
| Geographic latency | EU servers + US integration = transatlantic latency every call |
| Gradual degradation | Services slow over time; cumulative impact becomes severe without monitoring |
The volume of third-party dependencies in typical SaaS applications surprises many teams. Analytics, error tracking, feature flags, email, SMS, payments, search, file storage, and authentication represent just common categories. Each dependency is a potential performance impact.
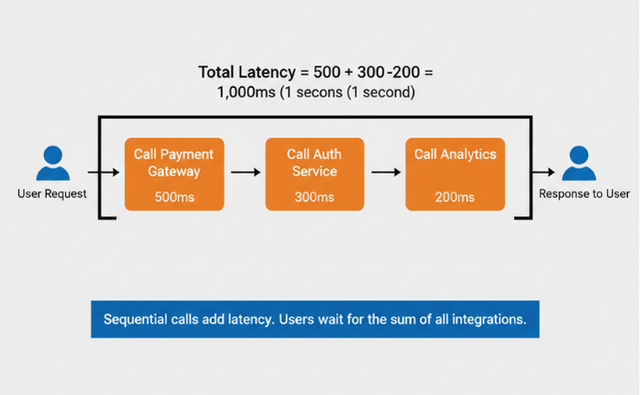
Integiation performance often degrades gradually. Services that performed well during initial integration may slow over time. Without monitoring, this degradation goes unnoticed until cumulative impact becomes severe.
Common Integration Performance Problems
Synchronous calls during request handling force users to wait. When your application calls external services before responding to users, their request latency includes external service latency. This pattern is common but often unnecessary.
Sequential service calls multiply latency. If processing a request requires calling service A, then B, then C, total latency equals the sum of all three. Often these calls could happen in parallel or not during the request at all.
Missing timeouts create unbounded waiting. Without configured timeouts, external calls can block indefinitely. A hung connection to a payment processor might make your checkout completely unresponsive rather than failing gracefully.
Retry storms compound problems. When external services become slow or unavailable, naive retry logic multiplies load. If every failed request generates three retries, and the external service is struggling, retries make recovery harder.
SSL/TLS handshake overhead adds up. Each new connection to external services requires cryptographic handshake. Without connection reuse, this overhead multiplies across many requests.
Rate limiting from providers can throttle your application. Services that limit requests per second may reject requests during traffic spikes. These rejections manifest as errors or delays for your users.
Webhook processing delays affect perceived performance. While webhooks are asynchronous, slow webhook processing can delay data synchronization. Users might see stale data if webhook queues back up.
Measuring Third-Party Impact
Best practices for measuring third-party impact includes:
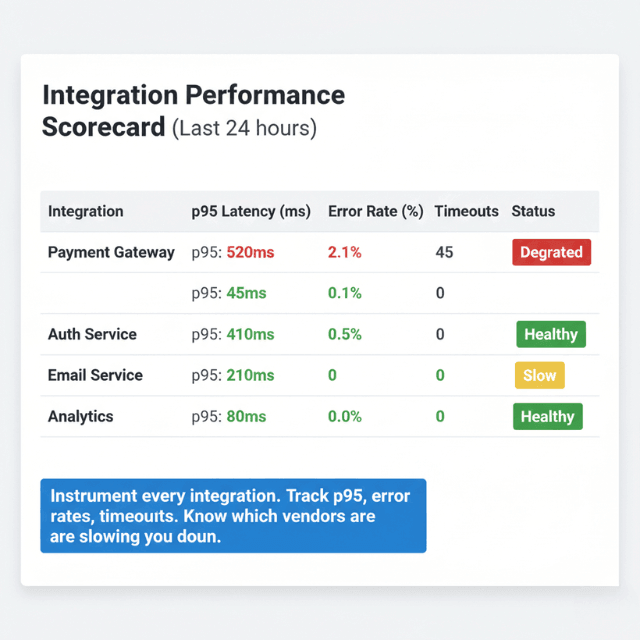
- Instrument all external service calls - Log request duration, response codes, payload sizes for every integration. This data enables identification and quantification of third-party performance impact.
- Use distributed tracing - End-to-end traces show exactly how much time each external call contributes. This visibility prioritizes optimization efforts.
- Establish baselines - Know normal performance for each external service. Deviations from baseline indicate problems worth investigating.
- Monitor error rates separately - Distinguish external errors from code errors. Distinguish between these categories to understand true service health.
- Track latency percentiles - Monitor p50, p95, p99 (averages hide outliers) to understand the full range of integration performance.
- Set up synthetic monitoring - Periodic test calls provide early warning. Detect issues before they affect production users.
- Compare performance across providers - If using multiple payment processors or regional API endpoints, compare performance between them. This data informs routing decisions and vendor negotiations.
Defensive Integration Patterns
Circuit breakers prevent cascade failures. When an external service fails repeatedly, stop calling it temporarily. Allow time for recovery rather than piling failed requests onto a struggling service.
# Example circuit breaker pattern
class CircuitBreaker:
def __init__(self, failure_threshold=5, recovery_timeout=30):
self.failures = 0
self.threshold = failure_threshold
self.timeout = recovery_timeout
self.state = "closed"
self.last_failure = None
def call(self, func, *args, **kwargs):
if self.state == "open":
if time.time() - self.last_failure > self.timeout:
self.state = "half-open"
else:
raise CircuitOpenError("Circuit breaker is open")
try:
result = func(*args, **kwargs)
self.on_success()
return result
except Exception as e:
self.on_failure()
raise
Configure appropriate timeouts for all external calls. Determine acceptable wait times for each integration. Set timeouts shorter than user patience thresholds. Fail fast rather than hang indefinitely.
Implement retry logic with exponential backoff. When retries are appropriate, space them increasingly apart. This approach gives services time to recover without overwhelming them.
Use bulkheads to isolate integration failures. Separate connection pools for different services prevent one misbehaving integration from exhausting resources needed by others.
Implement health checks for critical dependencies. Proactively test external service availability. Route around unavailable services when alternatives exist.
Circuit Breaker Pattern - States
| State | Behavior |
|---|---|
| Closed | Normal operation; calls flow through to external service |
| Open | Service failing repeatedly; stop calling temporarily; fail fast |
| Half-open | Recovery timeout elapsed; test one request; if succeeds → closed, if fails → open |
Configuration parameters:
failure_threshold = 5(failures before opening circuit)recovery_timeout = 30(seconds before attempting half-open)
Circuit Breakers, Timeouts, and Bulkheads – We Implement Them All.
These patterns sound simple. Implementing them correctly across your entire integration landscape? That's complex.
Our CI/CD consulting includes:
- Resilience patterns – Circuit breakers, retries with backoff, bulkheads
- Integration testing – Ensure fallbacks work before production incidents
- Automated rollbacks – Recover quickly when third-party services fail
- Performance monitoring – Track p95/p99 latency per integration
Async Processing Strategies
Move non-essential calls out of request handling. Users don't need to wait for analytics events to send or audit logs to write. Queue these operations for background processing.
Use message queues for integration work. Tools like RabbitMQ, Amazon SQS, or Redis queues decouple request handling from external service calls. Workers process integration tasks asynchronously.
Design for eventual consistency where appropriate. Not every integration requires immediate synchronization. Many can tolerate seconds or minutes of delay without affecting user experience.
Implement webhooks for receiving data. Instead of polling external services, receive push notifications when data changes. This approach reduces your call volume and eliminates polling latency.
Parallelize independent external calls. If a request requires data from multiple services, fetch concurrently rather than sequentially. Total latency becomes the maximum rather than sum of individual calls.
// Sequential calls (slow)
const userData = await fetchUserService(userId);
const billingData = await fetchBillingService(userId);
const analyticsData = await fetchAnalyticsService(userId);
// Parallel calls (faster)
const [userData, billingData, analyticsData] = await Promise.all([
fetchUserService(userId),
fetchBillingService(userId),
fetchAnalyticsService(userId)
]);
| Pattern | Code Example | Total Latency |
|---|---|---|
| Sequential | await serviceA(); await serviceB(); await serviceC(); |
Sum of A + B + C |
| Parallel | await Promise.all([serviceA(), serviceB(), serviceC()]) |
Max of A, B, C |
Consider event-driven architectures. Publish events when state changes rather than calling services directly. Subscribers process events asynchronously, decoupling producers from consumers.
Caching and Fallback Approaches
Cache external service responses when appropriate. Reference data that changes infrequently can be cached for hours or days. Even volatile data might tolerate caching for seconds.
Implement stale-while-revalidate patterns. Serve cached data immediately while refreshing in the background. Users get fast responses even when cache entries are expiring.
Design fallback behaviors for critical integrations. When payment processing fails, queue for retry rather than losing the order. When search is unavailable, provide basic filtering.
Store essential data locally. Don't rely on external services for data your application needs to function. Synchronize data regularly but maintain local copies for resilience.
Use multiple providers for critical functions. If one payment processor fails, route to another. If one region's API is slow, try another. Redundant integrations provide resilience.
Precompute and cache aggregate data. Instead of calling analytics APIs on every dashboard load, cache computed metrics. Update caches periodically in the background.
Vendor Selection and Management
Evaluate performance during vendor selection. Request latency SLAs and historical performance data. Test integration performance in realistic conditions before committing.
Consider geographic availability. Vendors with global points of presence offer lower latency for distributed user bases. Single-region services create unavoidable latency for distant users.
Review vendor architecture for resilience. How do they handle failures? What's their uptime history? Vendor reliability becomes your reliability.
Negotiate performance SLAs. Document acceptable latency and availability levels. Include consequences for failures to meet commitments.
Maintain vendor alternatives. Avoid complete lock-in to single providers. Architectural abstractions that allow switching between vendors provide negotiating leverage and failure resilience.
Monitor vendor performance continuously. Don't assume consistent performance. Track trends over time. Address degradation proactively before it affects users significantly.
Schedule regular vendor performance reviews. Quarterly reviews of integration performance identify gradual degradation. Compare current performance against initial baselines and SLA commitments.
Third-party integrations extend your application's capabilities but require careful management to maintain performance. Defensive patterns, async processing, and caching strategies minimize the impact of external dependencies on user experience.
Conclusion
Third-party integrations accelerate development but introduce performance dependencies you can't fully control. The solution isn't elimination it's isolation. Circuit breakers and timeouts prevent cascading failures. Async processing moves non-critical calls out of the critical path. Caching reduces call frequency. Parallelism reduces cumulative latency.
Comprehensive monitoring gives visibility into which integrations are actually slowing you down. The worst-performing third-party call is the one you don't know about. Instrument everything. Set timeouts aggressively. Design fallbacks. And remember: when you call an external service, you're handing over a piece of your user experience to someone else's infrastructure. Make sure you get it back quickly or fail gracefully if you don't.
FAQs
1. How to know if a third-party integration is slowing you down?
- Instrument every external call with timing metrics
- Use an APM tool (Datadog, New Relic) or OpenTelemetry to track p50/p95/p99 per integration
- Compare endpoints with vs. without the integration
- Use distributed tracing to see exact contribution
- Key indicator: If integration's p95 is 800ms and your endpoint's p95 is 900ms, the integration dominates
2. Synchronous vs. asynchronous – when to use which?
| Use Case | Pattern | Examples |
|---|---|---|
| Response required during request | Synchronous | Payment processing, authentication, real-time inventory |
| User doesn't need immediate result | Asynchronous (background job) | Analytics, email, audit logs, report generation, CRM sync |
Rule of thumb: If user experience doesn't degrade without the result, move it to background.
3. Single most effective defensive pattern?
Circuit breakers. Timeouts prevent hanging, but circuit breakers prevent cascading failures. Without one, every request during an outage waits for timeout (e.g., 5 seconds) before failing – exhausting threads. With a circuit breaker, after N failures, subsequent requests fail immediately (fast-fail) for a recovery window, giving the external service time to recover. Implement for every critical integration. Libraries: circuitbreaker (Python), opossum (Node.js), Resilience4j (Java).
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.