Microservices Cloud-Native Architecture
Learn microservices cloud-native architecture with resilience patterns, service mesh (Istio), distributed tracing (OpenTelemetry), and deployment strategies. Production-ready code examples included.

TL;DR
- Microservices deliver 55% faster feature delivery and 47% better reliability (2024 State of DevOps), but require disciplined patterns for resilience, communication, and observability.
- Synchronous calls need protection: Implement circuit breakers (fail fast after 5 consecutive failures), timeouts (1-5 seconds), retries with exponential backoff, and fallbacks (cached data). These prevent cascading failures when dependencies degrade.
- gRPC for high-performance internal communication: Protocol Buffers + HTTP/2 reduce network overhead by 30-50% compared to JSON REST. Ideal for service-to-service calls with high throughput requirements.
- Asynchronous communication decouples services: Use message queues (RabbitMQ, SQS) for background tasks and pub/sub for events that multiple services consume. Enables temporal decoupling and better fault tolerance.
- Service mesh (Istio) provides traffic management, security, and observability without code changes: Implement canary deployments with automatic traffic shifting, retry/timeout policies, circuit breaking, and mutual TLS between services. Manage 10+ services? Service mesh becomes essential.
- Observability is non-negotiable: Implement distributed tracing (OpenTelemetry + Jaeger) to track requests across service boundaries. Use structured logging (JSON) with consistent fields (trace_id, service, timestamp). Monitor golden signals: latency, traffic, errors, saturation.
- Database per service, independent deployment: Each service owns its schema; no direct cross-service database access. Deploy independently with backward-compatible API changes. Progressive delivery (canary, blue-green) enables safe rollouts with automated rollback.
Microservices architecture decomposes applications into independently deployable services that communicate over network protocols. Organizations using microservices report 55% faster feature delivery and 47% better system reliability according to the 2024 State of DevOps Report.
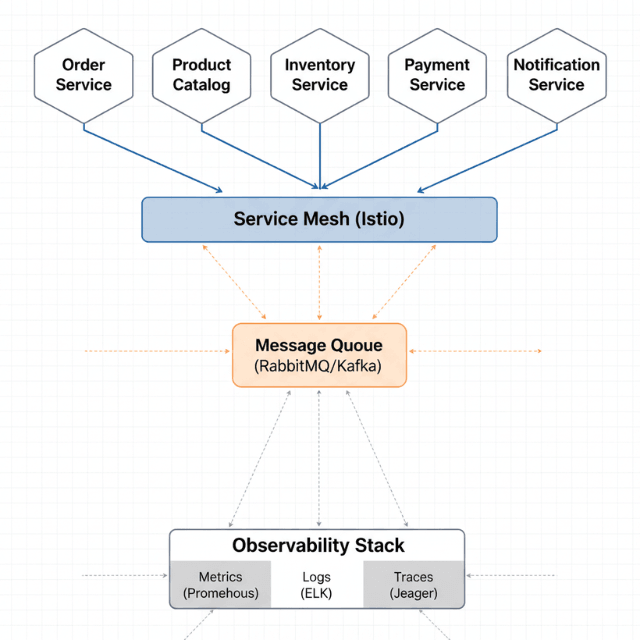
This guide provides production-ready patterns for building microservices in cloud-native environments.
You will implement resilience patterns to handle service failures gracefully, design asynchronous communication to decouple services, integrate service mesh for traffic management and security, and establish observability practices for distributed system monitoring. Each pattern includes tested code examples and configuration for Kubernetes deployments.
Prerequisites: Understanding of REST APIs, basic Kubernetes concepts, and familiarity with Python or Node.js. Experience deploying containerized applications and knowledge of distributed system challenges.
Expected outcomes: After implementing these patterns, you will build resilient microservices that handle failures automatically, implement efficient inter-service communication with proper timeouts and retries, deploy service mesh for advanced traffic routing, and monitor distributed systems with centralized logging and tracing.
Synchronous Communication Patterns
Microservices communicate through synchronous HTTP/REST calls or high-performance gRPC. Synchronous communication requires resilience patterns to prevent cascading failures.
import requests
from circuitbreaker import circuit
import logging
from typing import Optional, Dict
logger = logging.getLogger(__name__)
class ProductCatalogClient:
"""
Client for Product Catalog service with resilience patterns.
Implements circuit breaker, timeouts, and fallback mechanisms.
"""
def __init__(self, base_url: str, timeout: int = 5):
self.base_url = base_url
self.timeout = timeout
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'order-service/2.1.0'
})
@circuit(failure_threshold=5, recovery_timeout=60)
def get_product(self, product_id: str) -> Dict:
"""
Get product details with circuit breaker protection.
Circuit opens after 5 consecutive failures and stays open for 60 seconds.
Falls back to cached data when service is unavailable.
"""
try:
response = self.session.get(
f"{self.base_url}/products/{product_id}",
timeout=self.timeout,
headers={'X-Request-ID': self._generate_request_id()}
)
response.raise_for_status()
return response.json()
except requests.exceptions.Timeout:
logger.error(f"Timeout fetching product {product_id}")
return self._get_cached_product(product_id)
except requests.exceptions.HTTPError as e:
logger.error(f"HTTP error fetching product {product_id}: {e}")
if e.response.status_code == 404:
raise ProductNotFoundError(product_id)
return self._get_cached_product(product_id)
def _get_cached_product(self, product_id: str) -> Optional[Dict]:
"""Fallback to cached data on service failure"""
# Implementation would fetch from Redis or local cache
import redis
cache = redis.Redis(host='redis', port=6379)
cached_data = cache.get(f"product:{product_id}")
if cached_data:
return json.loads(cached_data)
return None
def _generate_request_id(self) -> str:
import uuid
return str(uuid.uuid4())
gRPC for High-Performance Communication
gRPC uses HTTP/2 and Protocol Buffers for efficient binary communication. Ideal for internal service-to-service calls with high throughput requirements. Companies report 30-50% reduction in network overhead compared to JSON REST APIs.
syntax = "proto3";
package inventory;
service InventoryService {
rpc CheckAvailability(AvailabilityRequest) returns (AvailabilityResponse);
rpc ReserveStock(ReservationRequest) returns (ReservationResponse);
rpc ReleaseStock(ReleaseRequest) returns (ReleaseResponse);
}
message AvailabilityRequest {
string product_id = 1;
int32 quantity = 2;
string warehouse_id = 3;
}
message AvailabilityResponse {
bool available = 1;
int32 available_quantity = 2;
string warehouse_id = 3;
int64 estimated_restock_time = 4;
}
message ReservationRequest {
string product_id = 1;
int32 quantity = 2;
string order_id = 3;
int64 expiration_seconds = 4;
}
message ReservationResponse {
bool success = 1;
string reservation_id = 2;
string error_message = 3;
}
Resilience Patterns for Synchronous Calls
Timeouts: Set aggressive timeouts to fail fast (typically 1-5 seconds). Prevents resource exhaustion from hanging requests.
Circuit breakers: Stop calling failing services to prevent cascading failures. Opens after threshold failures, provides fast-fail behavior.
Retries with exponential backoff: Retry transient failures with increasing delays. Start at 100ms, double each retry, maximum 3 attempts.
Bulkheads: Isolate thread pools for different dependencies. Prevents one failing service from consuming all threads.
Fallbacks: Return cached data or degraded functionality on failures. Maintains user experience during service outages.
Asynchronous Communication
Asynchronous messaging decouples services temporally. Producers and consumers do not need to be available simultaneously. RabbitMQ, AWS SQS, and Azure Service Bus provide durable queues with at-least-once delivery.
import json
import pika
from typing import Dict, Callable
import logging
logger = logging.getLogger(__name__)
class OrderEventPublisher:
"""
Publishes order events to RabbitMQ exchange.
Uses topic exchange for flexible routing to multiple consumers.
"""
def __init__(self, rabbitmq_url: str):
self.connection = pika.BlockingConnection(
pika.URLParameters(rabbitmq_url)
)
self.channel = self.connection.channel()
# Declare exchange for order events
self.channel.exchange_declare(
exchange='order-events',
exchange_type='topic',
durable=True
)
def publish_order_created(self, order: Dict) -> None:
"""Publish order created event"""
event = {
'event_type': 'order.created',
'event_id': order['id'],
'timestamp': order['created_at'],
'data': {
'order_id': order['id'],
'customer_id': order['customer_id'],
'items': order['items'],
'total_amount': order['total_amount']
}
}
self.channel.basic_publish(
exchange='order-events',
routing_key='order.created',
body=json.dumps(event),
properties=pika.BasicProperties(
delivery_mode=2, # Make message persistent
content_type='application/json',
correlation_id=order['id']
)
)
logger.info(f"Published order.created event for order {order['id']}")
def close(self):
self.connection.close()
class OrderEventConsumer:
"""
Consumes order events from RabbitMQ queue.
Implements proper acknowledgment and error handling.
"""
def __init__(self, rabbitmq_url: str, queue_name: str):
self.connection = pika.BlockingConnection(
pika.URLParameters(rabbitmq_url)
)
self.channel = self.connection.channel()
# Declare queue and bind to exchange
self.channel.queue_declare(queue=queue_name, durable=True)
self.channel.queue_bind(
exchange='order-events',
queue=queue_name,
routing_key='order.created'
)
# Set prefetch to process one message at a time
self.channel.basic_qos(prefetch_count=1)
def start_consuming(self, callback: Callable) -> None:
"""Start consuming messages from queue"""
def on_message(channel, method, properties, body):
try:
event = json.loads(body)
callback(event)
channel.basic_ack(delivery_tag=method.delivery_tag)
logger.info(f"Processed event {event['event_id']}")
except Exception as e:
logger.error(f"Error processing message: {e}")
# Reject message and send to dead letter queue
channel.basic_nack(
delivery_tag=method.delivery_tag,
requeue=False
)
self.channel.basic_consume(
queue=self.queue_name,
on_message_callback=on_message
)
logger.info('Started consuming messages...')
self.channel.start_consuming()
Communication Pattern Selection
Request-response: User-facing operations requiring immediate feedback. Use REST or gRPC with timeouts under 5 seconds.
Fire-and-forget: Background tasks, notifications, logging. Use message queues with async processing.
Pub/sub: Events that multiple services need to process. Use Kafka or cloud-native event buses for fan-out.
Request-async-response: Long-running operations with callback. Use correlation IDs to match requests with responses.
Service Mesh Integration
Service mesh provides traffic management, security, and observability without changing application code. Istio dominates with 64% market share according to CNCF's 2024 Service Mesh Survey.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: order-service
namespace: production
spec:
hosts:
- order-service
http:
- match:
- headers:
user-tier:
exact: premium
route:
- destination:
host: order-service
subset: v2
weight: 100
timeout: 10s
retries:
attempts: 3
perTryTimeout: 3s
- route:
- destination:
host: order-service
subset: v2
weight: 90
- destination:
host: order-service
subset: v1
weight: 10
timeout: 5s
retries:
attempts: 3
perTryTimeout: 2s
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: order-service
namespace: production
spec:
host: order-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 50
maxRequestsPerConnection: 2
outlierDetection:
consecutiveErrors: 5
interval: 30s
baseEjectionTime: 30s
subsets:
- name: v1
labels:
version: v1.0.0
- name: v2
labels:
version: v2.1.0
Distributed Tracing with OpenTelemetry
OpenTelemetry provides vendor-neutral instrumentation for tracing requests across services. Essential for debugging performance issues in distributed systems.
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from flask import Flask, jsonify
app = Flask(__name__)
# Initialize tracer
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
# Configure OTLP exporter to Jaeger
otlp_exporter = OTLPSpanExporter(endpoint="http://jaeger:4317")
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
# Auto-instrument Flask and requests library
FlaskInstrumentor().instrument_app(app)
RequestsInstrumentor().instrument()
@app.route('/orders/<order_id>')
def get_order(order_id):
with tracer.start_as_current_span("process_order_request") as span:
span.set_attribute("order.id", order_id)
span.set_attribute("http.method", "GET")
# Fetch order from database
order = fetch_order_from_db(order_id)
# Call other services with trace context automatically propagated
customer = get_customer_details(order['customer_id'])
inventory = check_inventory_status(order['items'])
span.set_attribute("order.total", order['total_amount'])
span.set_attribute("customer.tier", customer['tier'])
return jsonify(order)
def fetch_order_from_db(order_id):
with tracer.start_as_current_span("database_query") as span:
span.set_attribute("db.operation", "select")
span.set_attribute("db.table", "orders")
# Database query logic here
return {"id": order_id, "customer_id": "123", "total_amount": 99.99}
Centralized Logging
Structured logging enables efficient search and correlation across services. Use JSON format with consistent fields for service name, trace IDs, and timestamps.
import logging
import json
from datetime import datetime
class JSONFormatter(logging.Formatter):
def format(self, record):
log_object = {
'timestamp': datetime.utcnow().isoformat(),
'level': record.levelname,
'service': 'order-service',
'message': record.getMessage(),
'logger': record.name
}
# Add trace context if available
if hasattr(record, 'trace_id'):
log_object['trace_id'] = record.trace_id
log_object['span_id'] = record.span_id
# Add custom fields
if hasattr(record, 'order_id'):
log_object['order_id'] = record.order_id
if hasattr(record, 'customer_id'):
log_object['customer_id'] = record.customer_id
return json.dumps(log_object)
# Configure logger
handler = logging.StreamHandler()
handler.setFormatter(JSONFormatter())
logger = logging.getLogger('order-service')
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# Usage example
logger.info("Order created", extra={'order_id': '12345', 'customer_id': '67890'})
Deployment Strategies
Progressive delivery techniques enable safe rollouts with automated rollback on failures.
Canary deployment with Flagger automates gradual traffic shifting based on metrics:
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: order-service
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: order-service
service:
port: 80
targetPort: 8080
analysis:
interval: 1m
threshold: 5
maxWeight: 50
stepWeight: 10
metrics:
- name: request-success-rate
thresholdRange:
min: 99
interval: 1m
- name: request-duration
thresholdRange:
max: 500
interval: 1m
webhooks:
- name: load-testing
url: http://loadtester.test/
timeout: 5s
metadata:
cmd: "hey -z 1m -q 10 -c 2 http://order-service.production/"
Flagger automatically increases traffic to canary version by 10% every minute if success rate stays above 99% and latency below 500ms. Rollback occurs automatically if metrics degrade.
Operational Best Practices
Service ownership: Each team owns services end-to-end including development, deployment, monitoring, and on-call support.
API contracts: Use OpenAPI specifications for REST APIs and Protocol Buffers for gRPC. Version APIs explicitly.
Database per service: Each service owns its database schema. No direct database access across services.
Independent deployment: Services deploy independently without coordination. Use backward-compatible API changes.
Automated testing: Implement unit tests, integration tests, contract tests, and end-to-end tests in CI/CD pipeline.
Observability: Instrument all services with metrics, logs, and traces from day one. Monitor golden signals: latency, traffic, errors, saturation.
Conclusion
Microservices architecture enables independent scaling and deployment of services, accelerating feature delivery and improving system resilience. Success requires disciplined implementation of resilience patterns, proper service communication strategies, and robust observability practices.
Start with synchronous REST APIs protected by circuit breakers and timeouts. Add asynchronous messaging for background processing and event broadcasting. Implement distributed tracing before deploying to production. Deploy service mesh when managing more than 10 services or requiring advanced traffic routing.
The operational complexity of microservices is significant. Invest in platform engineering to provide self-service deployment, monitoring, and troubleshooting capabilities. Build incrementally, validating each pattern with production traffic before expanding.
Frequently Asked Questions
When should I use gRPC vs. REST for service-to-service communication?
Use gRPC when you need high throughput, low latency, and strongly typed contracts between internal services. gRPC reduces network overhead by 30-50% compared to JSON REST, supports bidirectional streaming, and enforces schema evolution.
Use REST when you need broad client compatibility, human-readable APIs, or are exposing services to external consumers. Many teams use both: gRPC for internal communication, REST for public APIs.
How do I choose between message queues and service mesh for communication?
Message queues (RabbitMQ, SQS) are for asynchronous, decoupled communication where services don't need immediate responses—background processing, event broadcasting, load leveling.
Service mesh (Istio) manages synchronous communication—handles retries, timeouts, circuit breaking, and mTLS for HTTP/gRPC traffic. They complement each other: mesh for request/response, queues for fire-and-forget and pub/sub.
What's the minimum observability I need before deploying microservices to production?
Three non-negotiable components:
- Distributed tracing (OpenTelemetry + Jaeger/Zipkin) to trace requests across services.
- Structured logging with trace IDs to correlate logs with traces.
- Metrics (Prometheus) for golden signals: request rate, error rate, latency percentiles (p95, p99), and resource utilization.
Without these, debugging a failing request across 5+ services becomes nearly impossible. Instrument from day one, not after production incidents.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.