Data Persistence Patterns
Master cloud-native data persistence patterns including Database Per Service, Saga, Outbox, Event Sourcing, and CQRS. Learn to manage distributed data with production-ready code examples.

TL;DR
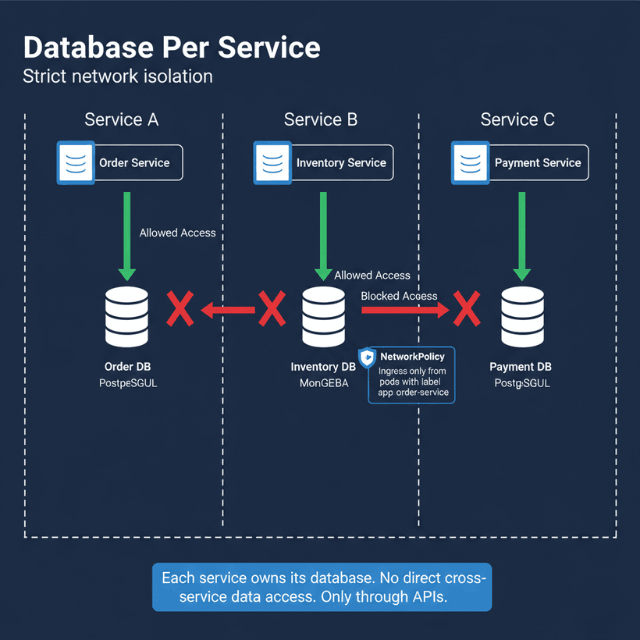
- Database Per Service – Each microservice owns its database. Access only via API, never direct. Enforce with Kubernetes NetworkPolicies.
- Saga Pattern – Coordinates distributed transactions using local transactions + compensating rollbacks. Two types: choreography (decentralized) or orchestration (central coordinator).
- Transactional Outbox – Write business data + events in same local transaction. Relay publishes events to broker. No distributed transactions needed. CDC is an alternative.
- Event Sourcing – Store state changes as immutable events, replay to reconstruct state. Benefits: audit trail, temporal queries, snapshots for performance.
- CQRS – Separate writes (consistent, normalized) from reads (denormalized, fast). Event-driven projectors update read models. Trade-off: eventual consistency.
- Progressive complexity: Most apps need Database Per Service + Outbox. Some need Sagas. Few need full Event Sourcing + CQRS.
Cloud-native architectures decompose monolithic applications into distributed microservices. This distribution creates data management challenges that traditional single-database approaches cannot solve effectively. Services need data isolation for independent deployment while maintaining consistency across business transactions spanning multiple services.
Database Per Service Pattern
Each microservice owns its database exclusively. No other service accesses this database directly, not even for reads. All data access happens through the service's API.
Benefits of isolation include independent schema evolution, technology choice freedom, and fault containment. The order service can migrate from PostgreSQL to MongoDB without affecting the inventory service. A database crash in the payment service doesn't impact the catalog service.
Challenges emerge immediately. How do you query data across services? How do you maintain consistency when a business transaction spans multiple databases? How do you avoid data duplication?
apiVersion: v1
kind: Service
metadata:
name: order-service-db
spec:
type: ClusterIP
ports:
- port: 5432
selector:
app: order-postgres
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: order-postgres
spec:
serviceName: order-service-db
replicas: 1
selector:
matchLabels:
app: order-postgres
template:
metadata:
labels:
app: order-postgres
spec:
containers:
- name: postgres
image: postgres:15
env:
- name: POSTGRES_DB
value: orders
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: order-db-secret
key: password
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
Network policies enforce database isolation at the infrastructure level. Only pods labeled with the correct service identifier can connect.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: order-db-policy
spec:
podSelector:
matchLabels:
app: order-postgres
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: order-service
ports:
- protocol: TCP
port: 5432
Saga Pattern for Distributed Transactions
Traditional ACID transactions don't work across multiple databases. The saga pattern coordinates distributed transactions through sequences of local transactions, each with compensating actions for rollback scenarios.
Choreography-based sagas use events for coordination. Each service listens for events, performs its local transaction, and publishes new events for the next step.
import redis
import json
from datetime import datetime
class OrderSagaHandler:
def __init__(self, redis_client, db_connection):
self.redis = redis_client
self.db = db_connection
def handle_order_created(self, event):
"""Step 1: Reserve inventory"""
order_id = event['order_id']
items = event['items']
# Local transaction in inventory service
with self.db.begin():
for item in items:
result = self.db.execute(
"UPDATE inventory SET reserved = reserved + %s "
"WHERE product_id = %s AND (quantity - reserved) >= %s",
(item['quantity'], item['product_id'], item['quantity'])
)
if result.rowcount == 0:
# Insufficient inventory - publish failure event
self.publish_event({
'event_type': 'inventory.reservation.failed',
'order_id': order_id,
'product_id': item['product_id'],
'timestamp': datetime.utcnow().isoformat()
})
return
# Success - publish next step
self.publish_event({
'event_type': 'inventory.reserved',
'order_id': order_id,
'timestamp': datetime.utcnow().isoformat()
})
def handle_payment_failed(self, event):
"""Compensating transaction: Release reserved inventory"""
order_id = event['order_id']
# Get order items
items = self.db.execute(
"SELECT product_id, quantity FROM order_items WHERE order_id = %s",
(order_id,)
).fetchall()
# Release reservations
with self.db.begin():
for item in items:
self.db.execute(
"UPDATE inventory SET reserved = reserved - %s "
"WHERE product_id = %s",
(item['quantity'], item['product_id'])
)
self.publish_event({
'event_type': 'inventory.released',
'order_id': order_id,
'reason': 'payment_failed',
'timestamp': datetime.utcnow().isoformat()
})
def publish_event(self, event):
"""Publish event to Redis Streams"""
self.redis.xadd('saga-events', event)
Orchestration-based sagas use a central coordinator that directs the saga execution. The orchestrator tells each service what to do and handles failure scenarios.
class SagaOrchestrator:
def __init__(self):
self.order_service = OrderServiceClient()
self.inventory_service = InventoryServiceClient()
self.payment_service = PaymentServiceClient()
self.notification_service = NotificationServiceClient()
async def execute_order_saga(self, order_data):
"""Execute order placement saga with rollback on failure"""
saga_state = {
'order_id': None,
'inventory_reserved': False,
'payment_processed': False
}
try:
# Step 1: Create order
order = await self.order_service.create_order(order_data)
saga_state['order_id'] = order['id']
# Step 2: Reserve inventory
await self.inventory_service.reserve(
order['id'],
order['items']
)
saga_state['inventory_reserved'] = True
# Step 3: Process payment
await self.payment_service.charge(
order['customer_id'],
order['total_amount'],
order['id']
)
saga_state['payment_processed'] = True
# Step 4: Confirm order
await self.order_service.confirm_order(order['id'])
# Step 5: Send notification
await self.notification_service.send_confirmation(
order['customer_id'],
order['id']
)
return {'success': True, 'order_id': order['id']}
except Exception as e:
# Rollback in reverse order
await self.compensate(saga_state, str(e))
return {'success': False, 'error': str(e)}
async def compensate(self, saga_state, error):
"""Execute compensating transactions"""
if saga_state['payment_processed']:
await self.payment_service.refund(saga_state['order_id'])
if saga_state['inventory_reserved']:
await self.inventory_service.release(saga_state['order_id'])
if saga_state['order_id']:
await self.order_service.cancel_order(
saga_state['order_id'],
reason=error
)
Transactional Outbox Pattern
The outbox pattern ensures reliable event publishing without distributed transactions. Services write business data and events in the same local transaction.
-- Order service database schema
CREATE TABLE orders (
id UUID PRIMARY KEY,
customer_id UUID NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
status VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE order_items (
id UUID PRIMARY KEY,
order_id UUID REFERENCES orders(id),
product_id UUID NOT NULL,
quantity INTEGER NOT NULL,
price DECIMAL(10,2) NOT NULL
);
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
event_type VARCHAR(100) NOT NULL,
aggregate_id UUID NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
published_at TIMESTAMP
);
CREATE INDEX idx_outbox_unpublished ON outbox(created_at)
WHERE published_at IS NULL;
Application code writes to both tables in a single transaction.
from datetime import datetime
import json
import uuid
def create_order(customer_id, items, db_connection):
"""Create order and outbox event in single transaction"""
order_id = uuid.uuid4()
with db_connection.begin():
# Insert order
db_connection.execute(
"INSERT INTO orders (id, customer_id, total_amount, status) "
"VALUES (%s, %s, %s, %s)",
(order_id, customer_id, calculate_total(items), 'PENDING')
)
# Insert order items
for item in items:
db_connection.execute(
"INSERT INTO order_items (id, order_id, product_id, quantity, price) "
"VALUES (%s, %s, %s, %s, %s)",
(uuid.uuid4(), order_id, item['product_id'],
item['quantity'], item['price'])
)
# Insert outbox event
event_payload = {
'order_id': str(order_id),
'customer_id': str(customer_id),
'items': items,
'total_amount': str(calculate_total(items)),
'timestamp': datetime.utcnow().isoformat()
}
db_connection.execute(
"INSERT INTO outbox (event_type, aggregate_id, payload) "
"VALUES (%s, %s, %s)",
('OrderCreated', order_id, json.dumps(event_payload))
)
return order_id
A separate message relay process reads the outbox and publishes events.
import time
import kafka
class OutboxRelay:
def __init__(self, db_connection, kafka_producer):
self.db = db_connection
self.producer = kafka_producer
def run(self):
"""Poll outbox and publish unpublished events"""
while True:
# Fetch unpublished events
events = self.db.execute(
"SELECT id, event_type, aggregate_id, payload "
"FROM outbox "
"WHERE published_at IS NULL "
"ORDER BY created_at "
"LIMIT 100"
).fetchall()
for event in events:
try:
# Publish to Kafka
self.producer.send(
topic='order-events',
key=str(event['aggregate_id']),
value=event['payload'],
headers=[
('event_type', event['event_type'].encode()),
('event_id', str(event['id']).encode())
]
)
# Mark as published
self.db.execute(
"UPDATE outbox SET published_at = NOW() WHERE id = %s",
(event['id'],)
)
self.db.commit()
except Exception as e:
print(f"Failed to publish event {event['id']}: {e}")
self.db.rollback()
time.sleep(0.1) # Poll interval
Change Data Capture (CDC) provides an alternative implementation. Tools like Debezium read database transaction logs (PostgreSQL WAL, MySQL binlog) and emit events for every change. CDC is more sophisticated but requires database-specific configuration and adds operational complexity.
Benefits of the outbox pattern include guaranteed event publishing (events are published if and only if transactions commit), exactly-once semantics (with proper implementation), and no distributed transactions needed. Drawbacks include slight latency (events publish asynchronously, typically within milliseconds to seconds), operational complexity (need to run and monitor message relay), and storage overhead (outbox table grows if publishing lags).
Event Sourcing
Event sourcing stores all state changes as immutable events. Instead of storing current state, store the sequence of events that led to that state. Current state is derived by replaying events.
# Event store schema
CREATE TABLE events (
id BIGSERIAL PRIMARY KEY,
aggregate_id UUID NOT NULL,
aggregate_type VARCHAR(50) NOT NULL,
event_type VARCHAR(100) NOT NULL,
event_data JSONB NOT NULL,
version INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
UNIQUE(aggregate_id, version)
);
CREATE INDEX idx_events_aggregate ON events(aggregate_id, version);
class OrderAggregate:
def __init__(self, order_id):
self.order_id = order_id
self.version = 0
self.events = []
self.state = {
'status': 'NEW',
'items': [],
'total': 0
}
def apply_event(self, event):
"""Apply event to update aggregate state"""
if event['event_type'] == 'OrderCreated':
self.state['status'] = 'PENDING'
self.state['items'] = event['items']
self.state['total'] = event['total']
elif event['event_type'] == 'OrderConfirmed':
self.state['status'] = 'CONFIRMED'
elif event['event_type'] == 'OrderShipped':
self.state['status'] = 'SHIPPED'
self.state['tracking_number'] = event['tracking_number']
self.version += 1
def load_from_events(self, events):
"""Rebuild state from event stream"""
for event in events:
self.apply_event(event)
def create_order(self, customer_id, items):
"""Command: Create order"""
event = {
'event_type': 'OrderCreated',
'customer_id': customer_id,
'items': items,
'total': sum(item['price'] * item['quantity'] for item in items)
}
self.apply_event(event)
self.events.append(event)
def save(self, db):
"""Persist new events"""
for event in self.events:
db.execute(
"INSERT INTO events (aggregate_id, aggregate_type, "
"event_type, event_data, version) "
"VALUES (%s, %s, %s, %s, %s)",
(self.order_id, 'Order', event['event_type'],
json.dumps(event), self.version)
)
db.commit()
self.events = []
Snapshots optimize performance. Replaying thousands of events for every read becomes expensive. Store periodic snapshots of aggregate state.
def load_aggregate(order_id, db):
"""Load aggregate with snapshot optimization"""
aggregate = OrderAggregate(order_id)
# Load latest snapshot
snapshot = db.execute(
"SELECT state, version FROM snapshots "
"WHERE aggregate_id = %s "
"ORDER BY version DESC LIMIT 1",
(order_id,)
).fetchone()
if snapshot:
aggregate.state = json.loads(snapshot['state'])
aggregate.version = snapshot['version']
start_version = snapshot['version'] + 1
else:
start_version = 1
# Load events after snapshot
events = db.execute(
"SELECT event_data FROM events "
"WHERE aggregate_id = %s AND version >= %s "
"ORDER BY version",
(order_id, start_version)
).fetchall()
aggregate.load_from_events([e['event_data'] for e in events])
return aggregate
CQRS: Command Query Responsibility Segregation
CQRS separates write operations (commands) from read operations (queries). Write side optimizes for consistency and business logic. Read side optimizes for query performance.
# Command side: Normalized write model
CREATE TABLE orders (
id UUID PRIMARY KEY,
customer_id UUID NOT NULL,
status VARCHAR(20) NOT NULL
);
CREATE TABLE order_items (
id UUID PRIMARY KEY,
order_id UUID REFERENCES orders(id),
product_id UUID NOT NULL,
quantity INTEGER NOT NULL
);
# Query side: Denormalized read model
CREATE TABLE order_summary (
order_id UUID PRIMARY KEY,
customer_name VARCHAR(200),
customer_email VARCHAR(200),
total_items INTEGER,
total_amount DECIMAL(10,2),
status VARCHAR(20),
created_at TIMESTAMP,
updated_at TIMESTAMP
);
CREATE INDEX idx_order_summary_customer ON order_summary(customer_email);
CREATE INDEX idx_order_summary_status ON order_summary(status);
Projectors listen for events and update read models.
class OrderSummaryProjector:
def __init__(self, read_db):
self.db = read_db
def handle_order_created(self, event):
"""Update read model when order is created"""
customer = self.get_customer_info(event['customer_id'])
self.db.execute(
"INSERT INTO order_summary "
"(order_id, customer_name, customer_email, total_items, "
"total_amount, status, created_at) "
"VALUES (%s, %s, %s, %s, %s, %s, %s)",
(event['order_id'], customer['name'], customer['email'],
len(event['items']), event['total_amount'], 'PENDING',
event['timestamp'])
)
self.db.commit()
def handle_order_status_changed(self, event):
"""Update read model when status changes"""
self.db.execute(
"UPDATE order_summary "
"SET status = %s, updated_at = NOW() "
"WHERE order_id = %s",
(event['new_status'], event['order_id'])
)
self.db.commit()
Benefits include independent scaling of reads and writes, optimized query models for specific use cases, and simplified business logic on write side. Challenges include eventual consistency between write and read models, operational complexity of maintaining multiple data stores, and ensuring projectors stay up to date.
These patterns enable building distributed systems that maintain data consistency while allowing independent service deployment and scaling. Choose patterns based on consistency requirements, query complexity, and operational capabilities.
Conclusion
Data persistence in distributed systems requires abandoning the simplicity of single-database ACID transactions. The patterns presented Database Per Service, Saga, Outbox, Event Sourcing, and CQRS form a progressive toolkit.
Database Per Service provides the isolation necessary for independent deployment. The Outbox pattern enables reliable event publishing without distributed transactions. Sagas coordinate business processes across services with compensating rollbacks.
Event Sourcing captures complete audit trails and enables temporal queries. CQRS optimizes read performance independently from write logic. The key is matching pattern to problem: most applications need Database Per Service and Outbox; some need Sagas; few need full Event Sourcing and CQRS.
Start simple, add complexity as requirements emerge, and always design for the eventual consistency that distributed systems demand. The investment in these patterns pays back through independent service evolution, fault isolation, and scalability that monolithic architectures cannot achieve.
FAQs
1. How to query across services?
Three options: API composition (call each service, join in memory), CQRS read models (denormalized tables updated via events), or BFF aggregator. Start with API composition; move to CQRS when performance demands.
2. How to handle eventual consistency in CQRS?
Design for it: show loading states, use optimistic UI, route read-after-write requests to the write model, ensure idempotent projectors. The gap is typically milliseconds acceptable for most SaaS apps.
3. Simplest way to start?
Step 1: Database Per Service + API composition (split monolith, enforce API access). Step 2: Add Outbox (outbox table + relay to Kafka/RabbitMQ). Step 3: Add Saga orchestration for multi-step transactions. Step 4: Add Event Sourcing + CQRS only for audit trails or complex queries.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.