Key Principles of SaaS Performance Optimization for Speed, Scalability, and Reliability
Master the three pillars of SaaS success: speed, scalability, and reliability. Learn key principles, metrics, and strategies to optimize user experience and drive growth.

TL;DR
- Speed, scalability, and reliability are the three pillars of SaaS success. Speed drives engagement and conversion; scalability enables growth without rewrites; reliability builds trust that retains customers. Neglect any pillar, and you lose to competitors.
- Speed is a competitive advantage. Every 100ms of latency can cost 1% in sales (Amazon's data). Mobile and international users feel slowness most acutely. Optimize frontend, backend, databases, and networks together.
- Scalability requires horizontal thinking. Stateless design, read replicas, caching, and asynchronous processing enable adding servers rather than upgrading them. Plan for scale from day one retrofitting is expensive.
- Reliability builds trust through redundancy and graceful degradation. Eliminate single points of failure. Use circuit breakers, retries, and monitoring. Test failover with chaos engineering.
- Balance the pillars against your context. Caching improves speed but complicates reliability. Strong consistency limits scalability. Cost constrains all three. Prioritize based on user needs: real-time trading needs speed; medical records need reliability.
Every successful SaaS application rests on three pillars: speed that keeps users engaged, scalability that supports growth, and reliability that builds trust. Master these principles, and your application becomes a platform users depend on. Neglect them, and you face an uphill battle against churn and competition.
Speed as a Competitive Advantage
Speed determines first impressions. When a potential customer tries your SaaS application, they form opinions within seconds. A fast, responsive interface signals quality and competence. A sluggish experience suggests the product might disappoint in other ways too.
| Finding | Source | Implication |
|---|---|---|
| Every 100ms of added latency cost 1% in sales | Amazon research | User patience is limited; faster = more revenue |
| 2 seconds vs 200ms per load × hundreds of loads per week | Example: project management tool | Meaningful time loss, accumulated frustration |
Mobile and international users feel speed problems most acutely. Higher latency connections amplify every delay. An application that feels acceptable on a fast office connection may feel unusable on mobile networks or from distant geographic regions. Speed optimization must consider your entire user base, not just those with optimal connections.
Achieving speed requires attention across the entire stack. Frontend code must minimize render-blocking resources and execute efficiently. Backend services must process requests quickly without unnecessary computation. Databases must retrieve data without delay. Networks must transmit information efficiently. Weakness in any layer compromises the whole.
Quick wins for speed improvement includes:
- Enable compression for API responses
- Implement browser caching for static assets
- Add indexes to frequently queried database columns
More substantial improvements require profiling to identify specific bottlenecks, then targeted optimization efforts.
Scalability for Sustainable Growth
Scalability determines whether your architecture supports growth or constrains it. A scalable system handles increased load by adding resources proportionally. An unscalable system hits walls where no amount of additional resources solves the problem.
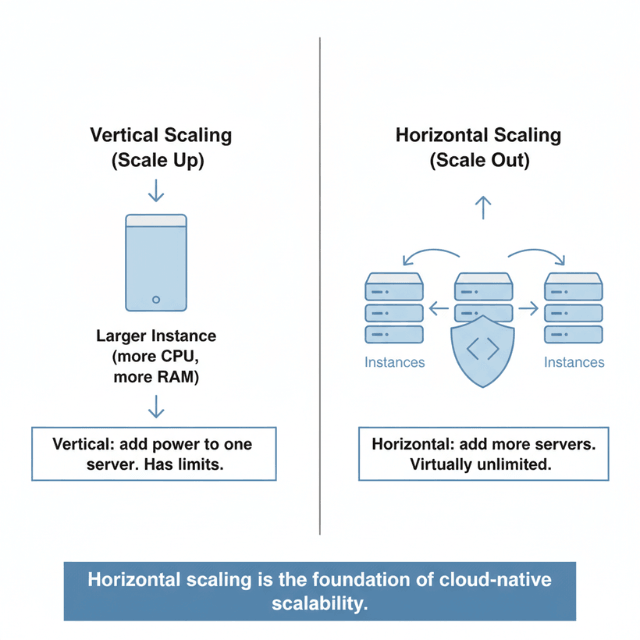
Horizontal scaling adds more servers to distribute load. This approach works well for stateless application layers where any server can handle any request. Load balancers distribute traffic across multiple instances. When traffic increases, you add more instances. When it decreases, you remove them.
Vertical scaling adds more resources to existing servers. This approach has natural limits: eventually, you reach the largest available server size. However, vertical scaling remains valuable for components that are difficult to distribute, such as relational databases with strong consistency requirements.
Database scalability often becomes the constraining factor. Application servers scale horizontally with relative ease, but databases require careful architecture.
| Strategy | Purpose | Implementation |
|---|---|---|
| Read replicas | Distribute query load | Multiple database copies for read operations |
| Sharding | Partition data across multiple servers | Split data by key (e.g., customer ID) |
| Caching | Reduce database load | Serve repeated queries from memory |
Stateless design enables scalability. When application servers maintain no session state, any server can handle any request. This flexibility allows load balancers to distribute traffic freely and enables seamless scaling. Store session data in shared caches or databases rather than in application server memory.
Asynchronous processing improves scalability by decoupling work from requests. Instead of performing time-consuming operations during request handling, queue work for background processing. Message queues like RabbitMQ or cloud services like Amazon SQS manage work distribution across worker processes.
Plan for scale before you need it. Architectural decisions made early in development become expensive to change later. Design for horizontal scaling from the start, even if initial traffic doesn't require it. The cost of scalable architecture during initial development is far less than retrofitting it later.
Reliability and the Trust Factor
Reliability builds the trust that retains customers. When users depend on your application for business-critical workflows, they need confidence that it will be available when needed. Every outage or error erodes that confidence.
Availability targets define reliability expectations. Choose targets that match customer expectations and your operational capabilities.
| Availability Target | Allowed Downtime per Year | Use Case |
|---|---|---|
| 99.9% ("three nines") | ~8.7 hours | Standard production |
| 99.99% ("four nines") | ~52 minutes | High-stakes applications |
| Higher targets | Less downtime | Requires sophisticated infrastructure and operational practices |
Some of the most important reliability strategies includes:
- Redundancy eliminates single points of failure. Every critical component should have backups ready to take over if the primary fails. Multiple application servers behind load balancers ensure that individual server failures don't affect users. Database replicas ready for promotion protect against primary database failures.
- Graceful degradation maintains core functionality during partial failures. When a non-essential service becomes unavailable, the application should continue operating with reduced functionality rather than failing completely. Users can tolerate missing recommendations or analytics more easily than a completely broken application.
- Error handling protects user experience. When problems occur, applications should fail gracefully with helpful error messages rather than crashing or displaying technical errors. Retry logic handles transient failures automatically. Circuit breakers prevent cascading failures when downstream services become unavailable.
- Monitoring provides early warning of reliability issues. Track error rates, response times, and resource utilization continuously. Set alert thresholds that notify your team before problems affect users significantly. The best reliability engineering prevents outages rather than just responding to them quickly.
- Testing validates reliability before production. Chaos engineering deliberately introduces failures to verify that redundancy and failover mechanisms work correctly. Load testing ensures the system handles expected traffic. Disaster recovery testing validates backup and restore procedures.
Balancing the Three Pillars
Speed, scalability, and reliability often create tension. Optimizing for one can compromise another. Effective performance engineering requires balancing these priorities based on your specific context and constraints.
Caching improves speed but complicates reliability. Cached data can become stale if invalidation fails. Cache failures can cause sudden load spikes on databases. Design caching strategies that provide speed benefits while maintaining data accuracy and handling failures gracefully.
Strong consistency improves reliability but limits scalability. Distributed systems that guarantee immediate consistency across all nodes sacrifice performance and partition tolerance. Many SaaS applications can accept eventual consistency for non-critical data, using strong consistency only where truly necessary.
Optimization for speed can reduce scalability. Code that achieves maximum single-request performance through aggressive in-memory caching may not scale horizontally. Balance per-request optimization with distributed architecture requirements.
Cost constrains all three pillars. More servers improve scalability but increase expenses. Redundant systems improve reliability but multiply costs. The fastest hardware improves speed but commands premium prices. Optimization must consider budget realities alongside technical goals.
User experience should guide priorities. Different applications have different requirements:
| Application Type | Primary Priority | Secondary |
|---|---|---|
| Real-time trading platform | Speed | Reliability |
| Medical records system | Reliability | Data integrity |
| Consumer social application | Scalability | Speed |
Speed, scalability, and reliability create tension. We help you balance them.
Every SaaS application faces trade-offs. The right balance depends on your users, your business model, and your stage of growth.
Our fractional CTO and DevOps experts help you:
- Identify your priority pillar – Speed, scalability, or reliability based on user needs
- Design for your constraints – Startup budget, team size, and growth trajectory
- Implement monitoring first – You can't optimize what you can't measure
- Build for incremental improvement – Perfect is the enemy of shipped
Measuring What Matters
Metrics transform abstract principles into concrete targets. Without measurement, optimization efforts become guesswork. With proper metrics, you can identify problems, track improvements, and make informed decisions.
Response time percentiles reveal user experience better than averages. An average response time of 200 milliseconds might mask that 5% of requests take over two seconds. Track p50 (median), p95, and p99 percentiles to understand the full distribution of user experiences.
| Metric | What It Measures | Why It Matters |
|---|---|---|
| p50 (median) | Typical user experience | Baseline performance |
| p95 | Experience of 95% of users | Reveals issues affecting many users |
| p99 | Extreme worst cases | Identifies rare but severe problems |
Throughput measures scalability in practice. Track requests per second during normal operation and during peak periods. Compare current throughput to historical trends and to theoretical capacity limits. Declining throughput relative to traffic indicates scaling problems.
Error rates indicate reliability issues. Track both application errors and infrastructure errors. Distinguish between client errors (user mistakes) and server errors (your problems). Set baselines and alert on significant deviations.
Availability calculations require accurate uptime tracking. Monitor from multiple locations to detect regional outages. Use external monitoring services to detect problems that internal monitoring might miss. Calculate availability over rolling periods to identify trends.
Resource utilization helps predict scaling needs. Track CPU, memory, disk I/O, and network utilization across your infrastructure. High utilization indicates approaching capacity limits. Correlate resource utilization with traffic to understand scaling requirements.
Business metrics connect performance to outcomes. They can track:
- Conversion rates
- User engagement
- Customer satisfaction
- Connect these to technical metrics to prioritize based on business impact
Implementation Strategies
Start with monitoring and observability. You cannot optimize what you cannot measure. Implement application performance monitoring (APM) tools that provide visibility into request traces, error rates, and resource utilization. Tools like Datadog, New Relic, or open-source alternatives like Jaeger and Prometheus provide this visibility.
Establish performance baselines before making changes. Measure current performance across key metrics. Document these baselines clearly. After optimization efforts, measure again against the same metrics to quantify improvements.
Prioritize optimizations by impact. Not all performance problems affect users equally. Focus on the slowest endpoints that users access frequently. A 50% improvement to a rarely-used feature matters less than a 10% improvement to core daily workflows.
Implement changes incrementally. Large architectural changes carry high risk. Break optimization efforts into smaller, testable increments. Deploy changes progressively, monitoring for regressions at each step. This approach limits blast radius if something goes wrong.
Automate performance testing. Include load tests and performance benchmarks in continuous integration pipelines. These tests catch regressions before they reach production. Set thresholds that fail builds when performance degrades significantly.
Build operational playbooks for common scenarios. Document procedures for handling traffic spikes, scaling resources, and responding to performance incidents. Clear procedures enable faster response when problems occur.
Building for Long-Term Success
- Performance optimization is continuous, not a one-time project. Traffic patterns change, features expand, and new bottlenecks emerge. Build performance engineering into your ongoing development practices rather than treating it as occasional maintenance.
- Include performance in feature planning. When designing new features, consider their performance implications from the start. Estimate the additional load they will create. Plan for the infrastructure capacity they will require. Performance considerations should influence feature design, not just implementation.
- Allocate engineering capacity for optimization work. Roadmaps dominated by feature development leave no room for performance improvements. Reserve capacity for technical work including optimization. Some teams dedicate specific percentages of each sprint; others schedule focused optimization sprints quarterly.
- Review performance trends regularly. Schedule periodic reviews of performance metrics and trends. Identify gradual degradation before it becomes severe. Celebrate improvements and investigate regressions. These reviews keep performance visible in team discussions.
- Learn from incidents. When performance problems affect users, conduct thorough postmortems. Understand root causes, not just symptoms. Identify what monitoring or testing could have caught the problem earlier. Implement preventive measures to avoid recurrence.
The principles of speed, scalability, and reliability provide a framework for building SaaS applications that users trust and depend on. Apply these principles thoughtfully, measure your results carefully, and continuously improve. Your users will reward you with loyalty and growth.
Conclusion
Speed, scalability, and reliability are not optional checkboxes they are the foundation of SaaS competitiveness. Users expect instant responses, seamless growth, and near-perfect uptime. Achieving all three requires deliberate architecture, continuous measurement, and ongoing investment. Start with monitoring to understand your current state. Prioritize optimizations that affect core user journeys.
Implement changes incrementally, testing for regressions. Build operational playbooks for incidents. And most importantly, embed performance thinking into your culture from feature design to sprint planning. The organizations that master these principles don't just retain users; they turn performance into a growth engine. Your users will notice the difference, and your business will benefit.
FAQs
1. What's the single most important metric to track for performance?
There is no single metric. Track three:
- p95 response time - user experience (shows experience of slow users)
- Error rate - reliability
- Requests per second vs. capacity - scalability
Average latency hides outliers; p95 shows the true user experience. Combine these three for a complete picture.
2. How do I know when to prioritize speed over scalability?
When you have a concrete performance problem affecting users. If your app is fast but can't handle growth, focus on scalability. If it scales but feels slow, focus on speed. Use data: if p95 latency exceeds 500ms and users complain, fix speed first. If CPU/memory consistently exceeds 80% during peak, fix scalability first.
3. Can I achieve all three pillars on a startup budget?
Yes, you can but here are some of these strategies, implementations and their trade-offs:
| Strategy | Implementation | Trade-offs |
|---|---|---|
| Use open-source tools | Prometheus, Grafana, Jaeger | More operational work |
| Start monolithic | Can be split later | May limit initial scalability |
| Use cloud auto-scaling | Managed services | Reduces operational burden |
| Prioritize by user segment | Focus on most critical pillar | Invest in others as you grow |
Summarize this post with:
