How Much Downtime Is Too Much for a Startup? (AWS Reliability Explained)
Learn how much downtime startups can tolerate, what uptime percentages mean, and how AWS reliability features help protect your growing business.

TLDR;
- Uptime targets by stage: Pre-MVP (flexible), early traction (99%), growth (99.9%), revenue-critical (99.99%)
- Common causes: Single-AZ architectures, manual deployments, weak monitoring
- Start simple: Multi-AZ + basic alerts first, add DR as business demands
- Match investments to actual risk, not enterprise playbooks
Every startup founder dreads the moment their product goes offline. Whether it happens during a product launch, a critical demo, or while onboarding a major customer, downtime creates problems that extend far beyond lost revenue. For early-stage companies building trust with their first users, even brief outages can damage credibility in ways that take months to repair.
This article examines how much downtime is acceptable at different startup stages, what causes most AWS-based outages, and which reliability investments make sense for growing companies. You will learn practical strategies for balancing reliability costs against business risk while building a foundation for scale.
Why Downtime Hits Startups Harder Than Enterprises
Large enterprises absorb downtime differently than startups. When Amazon or Microsoft experiences an outage, customers complain but rarely leave. Startups face a different reality.
Limited brand trust makes every interaction count. According to PwC research, 32% of customers will stop doing business with a brand they love after just one bad experience. For startups without established loyalty, that percentage climbs higher.
Fewer recovery resources compound the problem. Enterprise teams have dedicated site reliability engineers, runbooks, and incident management processes. Most startups have a handful of developers who must troubleshoot production issues while also building new features.
Higher growth impact amplifies every outage. According to Gartner research, the average cost of IT downtime is approximately $5,600 per minute. For a startup burning runway and chasing growth targets, losing potential customers during an outage creates damage that compounds over time.
What Downtime Really Means for a Startup
Downtime costs extend beyond the obvious revenue gap. Consider the full picture:
Revenue loss happens immediately. Every minute your signup flow or checkout process stays offline, you lose potential customers who may never return. E-commerce startups see this most directly, but SaaS companies feel it through failed trial conversions and churned subscribers.
Customer churn accelerates silently. Users who experience outages during their first week often abandon products without explanation. You see the drop in retention metrics weeks later without connecting it to the incident.
Team distraction pulls focus from growth. Engineers debugging production issues cannot ship new features. Founders managing customer complaints cannot close deals. This opportunity cost rarely appears on any dashboard.
Reputation damage spreads through word of mouth. According to Zendesk research, customers are twice as likely to share negative experiences as positive ones. In tight-knit startup communities and European B2B networks, reliability problems become common knowledge quickly.
How Much Downtime Is Technically Acceptable
Uptime percentages sound straightforward but often mislead founders. Understanding what these numbers mean helps you set realistic targets.
| Uptime | Annual Downtime | Monthly Downtime |
|---|---|---|
| 99% | 3.65 days | 7.3 hours |
| 99.9% | 8.76 hours | 43.8 minutes |
| 99.99% | 52.6 minutes | 4.4 minutes |
| 99.999% | 5.26 minutes | 26.3 seconds |
According to AWS documentation, Amazon EC2 offers a 99.99% monthly uptime SLA for individual instances in a Region. However, this only covers AWS infrastructure failures. Application bugs, deployment errors, and configuration mistakes remain your responsibility.
Why numbers alone mislead: A 99.9% uptime target sounds impressive until you realize it allows 43 minutes of monthly downtime. If that downtime occurs during your product launch or biggest sales day, the impact far exceeds what the percentage suggests.
Downtime Tolerance Depends on Your Startup Stage
Your acceptable downtime threshold should evolve as your company grows.
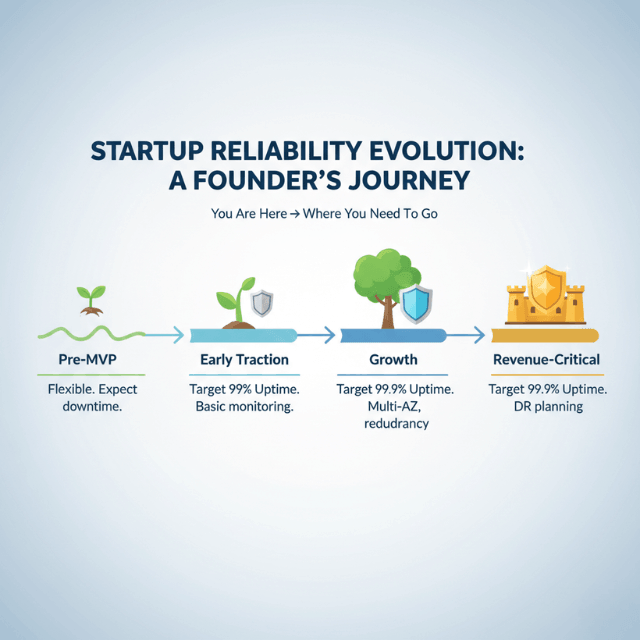
Pre-MVP stage: Some downtime is expected. You are iterating rapidly, deploying frequently, and learning what works. Users at this stage typically accept occasional issues if you communicate openly and fix problems quickly.
Early traction stage: Tolerance tightens. Your first paying customers expect stability. Brief outages during business hours start damaging relationships. Target 99% uptime and invest in basic monitoring.
Growth stage: Downtime becomes expensive. With significant MRR and active sales processes, each outage costs real revenue. Target 99.9% uptime and implement redundancy for critical systems.
Revenue-critical products: Near-zero tolerance. If your product processes payments, handles sensitive data, or supports customer operations, extended downtime creates legal and contractual exposure. Target 99.99% and invest in disaster recovery.
Common Causes of Downtime in AWS-Based Startups
Understanding failure patterns helps you prevent them. Most startup outages stem from predictable causes.
Single-AZ architectures create single points of failure. Running your entire application in one Availability Zone means any AZ issue takes you offline. According to AWS Well-Architected Framework, distributing workloads across multiple AZs is a foundational reliability practice.
Manual deployments introduce human error. Deploying through SSH sessions or manual console changes leads to configuration drift and mistakes under pressure. Automated CI/CD pipelines reduce this risk substantially.
Poor monitoring and alerts delay response. Without proper observability, you often learn about outages from customers rather than your own systems. AWS CloudWatch provides native monitoring, but many startups fail to configure meaningful alerts.
Configuration mistakes cause preventable failures. Security group changes, IAM policy updates, and database parameter modifications frequently trigger outages. Infrastructure as Code practices help prevent these errors.
AWS Reliability Basics Every Startup Should Implement
Building reliability does not require enterprise budgets. These foundational practices provide significant protection at reasonable cost.
Multi-AZ deployments should be your default. Services like Amazon RDS offer Multi-AZ configurations that automatically replicate data and fail over during outages. The additional cost typically ranges from 50-100% of single-AZ pricing but provides substantial protection.
Health checks and auto recovery catch failures automatically. Configure Elastic Load Balancing health checks to detect unhealthy instances and route traffic away from them. Enable EC2 auto recovery to automatically restart instances that fail status checks.
Monitoring and alerting essentials ensure fast response. At minimum, configure CloudWatch alarms for CPU utilization, memory usage, disk space, and application error rates. Set up notifications through SNS to alert your team immediately when issues occur.
Disaster Recovery When Downtime Is No Longer Acceptable
As your startup matures, basic reliability may not suffice. Disaster recovery planning becomes necessary when business continuity requirements demand it.
What DR means for startups: Disaster recovery differs from high availability. HA keeps your application running during component failures. DR ensures you can recover from catastrophic events that take down entire regions or corrupt critical data.
Backup vs recovery strategies: Backups alone do not constitute disaster recovery. You need tested procedures for restoring those backups and bringing systems back online. According to Gartner, organizations should define Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) based on business requirements.
When to plan beyond basic reliability: Consider DR planning when you handle customer data subject to GDPR or other European regulations, when contractual SLAs require specific recovery guarantees, or when your revenue depends on continuous operations.
Balancing Reliability, Cost, and Complexity
Reliability investments require careful calibration. Both over-engineering and under-preparing carry risks.
Over-engineering wastes resources: Multi-region active-active deployments cost significantly more and add operational complexity. Most early-stage startups do not need this level of protection.
Smart reliability investments focus on likely failures first. Fix single points of failure before building cross-region replication. Implement monitoring before automating failover. Address the 80% of risks that cause 80% of outages.
Cost-aware resilience decisions consider probability and impact. A brief database outage during business hours affects more users than an overnight batch processing failure. Prioritize protection accordingly.
When Startups Should Invest in AWS Reliability and DR
Certain signals indicate the time has come to increase reliability investments.
Warning signs you cannot ignore: Repeated outages from the same causes suggest systemic problems. Customer complaints about reliability indicate trust erosion. Near-misses that almost caused major outages reveal gaps in your architecture.
Business milestones that demand higher uptime: Closing enterprise contracts often requires demonstrable reliability practices. European B2B customers increasingly require GDPR-compliant disaster recovery plans. Series A and beyond investors expect operational maturity.
How EaseCloud Helps Startups Improve AWS Reliability and DR
Building reliability expertise takes time most startup teams do not have. EaseCloud provides the guidance and implementation support to accelerate your reliability journey.
Reliability architecture reviews identify gaps and prioritize improvements based on your specific risk profile and budget constraints.
Disaster recovery planning creates practical, tested procedures tailored to your technology stack and business requirements.
Ongoing uptime optimization helps you evolve your reliability practices as your company grows, ensuring your infrastructure keeps pace with your business.
Final Thoughts
Downtime is a business risk, not just a technical problem. The acceptable threshold depends on your startup stage, customer expectations, and growth trajectory. Start with foundational reliability practices like Multi-AZ deployments and proper monitoring. Add disaster recovery capabilities as your business demands them.
The key lies in matching your reliability investments to your actual risk exposure. Startups that get this balance right protect their growth while preserving capital for product development.
Ready to assess your startup's reliability posture? Contact EaseCloud for a free architecture review.
FAQs
How much downtime is normal for startups?
Early-stage startups typically experience 1-4 hours of monthly downtime. Growth-stage companies should target less than 45 minutes monthly (99.9% uptime). Revenue-critical products should aim for less than 5 minutes monthly (99.99% uptime).
Is 99.9% uptime enough for early-stage startups?
For most pre-Series A startups, 99.9% uptime provides adequate reliability. This allows approximately 43 minutes of monthly downtime. Focus on achieving this consistently before targeting higher levels.
What AWS services help reduce downtime?
Key services include Multi-AZ RDS for database redundancy, Elastic Load Balancing for traffic distribution, Auto Scaling for capacity management, and CloudWatch for monitoring and alerting.
How expensive is disaster recovery on AWS?
Costs vary by strategy. Backup-only approaches cost relatively little. Pilot light and warm standby configurations typically add 10-30% to infrastructure costs. Hot standby deployments can double your infrastructure spend.
When should startups plan for disaster recovery?
Plan for DR when you handle regulated data, sign enterprise contracts with SLA requirements, or reach revenue levels where extended downtime would threaten company survival.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.