Disaster Recovery Planning for Lean Startup Teams on AWS
Learn practical disaster recovery planning for lean startup teams on AWS with right-sized strategies that match your stage and budget.

TLDR;
- DR is a business safeguard, not an enterprise luxury
- Right-size by stage: Backup-and-restore first (~$10-50/mo), pilot light with paying customers, warm standby when revenue justifies it
- Key steps: Define RTO/RPO based on business impact, document procedures, test quarterly
Disaster recovery planning often gets postponed at startups. Teams assume DR is an enterprise concern, something to address once they reach scale. This assumption creates risk that grows invisibly until a major failure exposes it. A corrupted database, a compromised account, or a regional AWS outage can set an unprepared startup back months.
For lean teams with limited engineering bandwidth, the key lies in right-sized DR strategies that provide meaningful protection without enterprise-level complexity or cost. This article explains what DR means for startups, debunks common myths, and provides practical frameworks for building recovery capabilities that match your stage and resources.
Why Disaster Recovery Matters Even for Lean Startup Teams
Startups face unique vulnerabilities that make DR planning more important, not less.
Downtime directly impacts trust and growth. Your first customers take a risk by adopting an unproven product. According to PwC research, 32% of customers abandon brands after one bad experience. For startups without established loyalty, reliability failures create lasting damage.
Small teams recover slower without planning. Enterprises have dedicated incident response teams and documented runbooks. Lean startups often have founders and a few engineers who must figure out recovery procedures during the crisis itself. This extends outage duration and increases the chance of making recovery mistakes.
DR is a business safeguard, not an enterprise luxury. The question is not whether you can afford disaster recovery. The question is whether you can afford the alternative. According to the U.S. Small Business Administration, roughly 25% of businesses do not reopen following a major disaster. Startups operating without DR planning take on existential risk.
What Disaster Recovery Really Means for Startups
Understanding DR terminology helps you make informed decisions about your strategy.
Backup vs recovery represents a critical distinction. Backups store copies of your data. Recovery means actually restoring service using those backups. Many startups have backups but have never tested whether they can successfully restore from them. According to Gartner research, untested backups frequently fail to restore due to corruption, incomplete captures, or procedural gaps.
Recovery Time Objective (RTO) defines how quickly you need to restore service. Recovery Point Objective (RPO) defines how much data loss is acceptable. A startup processing financial transactions might need RPO measured in seconds, while a content platform might tolerate hours of data loss. These metrics drive your DR strategy selection.
Right-sized resilience for lean teams means matching protection to actual needs. Not every workload requires the same recovery guarantees. Your core product database probably needs stronger protection than your analytics pipeline.
Common DR Myths That Hold Startup Teams Back
Several misconceptions prevent startups from implementing appropriate DR measures.
"We're too small for DR" reflects a dangerous misunderstanding. Size does not determine vulnerability to disasters. A regional AWS outage affects startups and enterprises equally. Data corruption from a bad deployment hits small databases just as hard as large ones. Your size only affects your ability to recover without preparation.
"AWS handles everything" overstates cloud provider responsibility.

According to the AWS Shared Responsibility Model, AWS manages security and reliability of the cloud, while customers manage security and reliability in the cloud. Your data, your configurations, and your application logic remain your responsibility.
"DR is too expensive" often results from comparing startup needs against enterprise solutions. Right-sized DR strategies for startups cost far less than multi-region active-active deployments. Basic backup-and-restore capabilities can be implemented for tens of dollars monthly.
Defining Your Startup's Downtime and Data Loss Tolerance
Before selecting a DR strategy, understand your actual requirements.
Understanding RTO and RPO starts with business questions, not technical ones. How long can your product be offline before customers leave permanently? How much data can you lose before operations become unrecoverable? The answers vary by startup stage and business model.
Mapping downtime to business impact creates concrete context. If your MRR is $30,000 and an average outage loses you 5% of customers, each major incident costs $1,500 in recurring monthly revenue plus acquisition costs to replace those customers. This calculation justifies appropriate DR investment.
Prioritizing critical systems focuses limited resources effectively. Your authentication system and primary database likely need stronger protection than logging infrastructure. Document which systems must recover first and plan accordingly.
Right-Sized DR Strategies for Lean Startup Teams
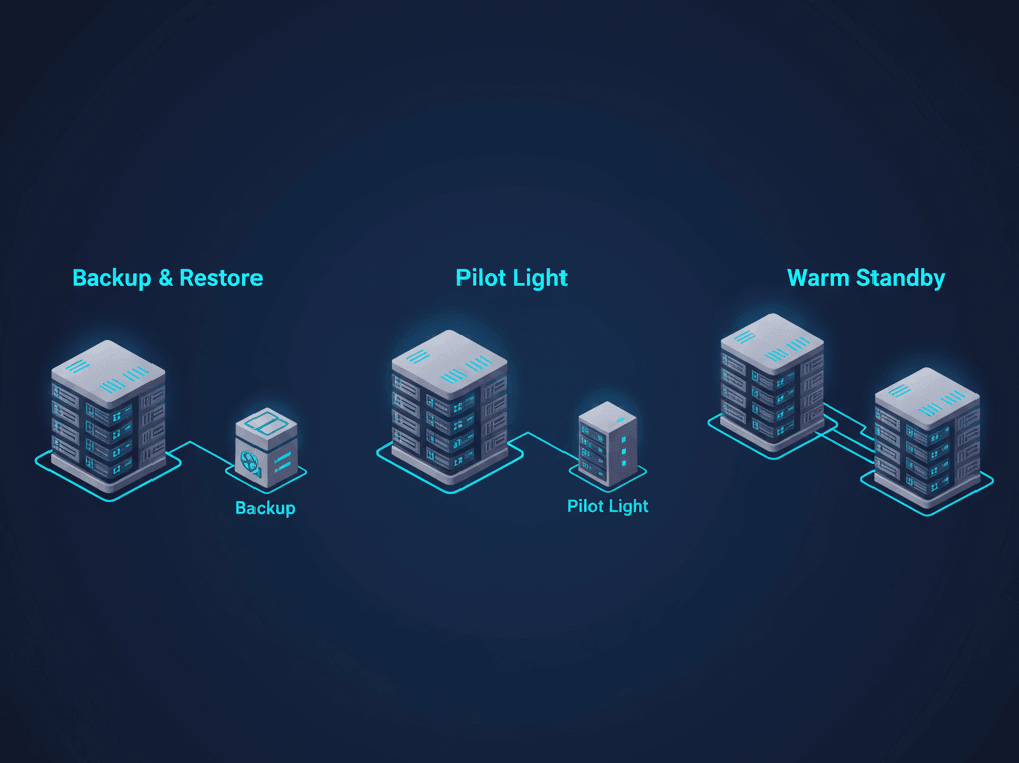
AWS supports several DR approaches at different cost and complexity levels.
Backup and restore represents the simplest strategy. You maintain regular backups in a separate region and restore them if disaster strikes. RTO can be hours to days depending on data volume. RPO depends on backup frequency. This approach costs little but provides meaningful protection against data corruption, accidental deletion, and regional failures.
Pilot light keeps core systems running in a recovery region with minimal resources. Your database replicates continuously, but compute resources remain off until needed. During disaster, you scale up the recovery region and redirect traffic. According to AWS DR documentation, pilot light typically achieves RTO measured in tens of minutes.
Warm standby runs a scaled-down version of your production environment continuously in the recovery region. During normal operations, it may handle read traffic or background processing. During disaster, you scale it up and fail over. RTO drops to minutes, but costs increase proportionally.
Choosing what fits your stage requires honest assessment. Pre-revenue startups often start with backup-and-restore. Growth-stage companies with paying customers typically move to pilot light. Revenue-critical products may need warm standby.
Core AWS Services That Support Disaster Recovery
AWS provides native services that simplify DR implementation for startups.
Backups and snapshots form the foundation. Amazon RDS automated backups capture daily snapshots and transaction logs, enabling point-in-time recovery. AWS Backup centralizes backup management across EC2, RDS, EFS, and other services. Cross-region replication copies backups to a secondary region automatically.
Multi-AZ and regional options provide redundancy at different scales. Multi-AZ deployments protect against single availability zone failures. Cross-region replication protects against entire region outages. Choose based on your RTO requirements and regulatory needs.
Monitoring and alerts enable rapid response. Amazon CloudWatch detects failures and triggers notifications. AWS Health Dashboard provides visibility into AWS service issues that might affect your workloads. Fast detection reduces overall recovery time.
Building a Simple Disaster Recovery Plan
A practical DR plan need not be complex, but it must be documented and tested.
Identifying critical workloads creates focus. List every component of your application. Mark which ones must recover first for the product to function. Databases and authentication typically top this list. Background jobs and analytics can wait.
Documenting recovery steps ensures repeatability under pressure. Write down exactly how to restore each critical system. Include commands, configuration values, and verification steps. During an actual disaster, your team will operate under stress with limited sleep. Clear documentation prevents mistakes.
Assigning ownership and responsibilities clarifies who does what. In lean teams, one person might own multiple responsibilities. The key is explicit assignment so nothing falls through cracks during crisis response.
Testing and Maintaining Your DR Plan
An untested DR plan provides false confidence.
Why untested DR plans fail comes down to hidden assumptions. Configuration drift means recovery procedures written six months ago may not work against today's infrastructure. Data volume growth affects recovery timing. Personnel changes mean the person who wrote the plan may not be available during the disaster.
How often to test depends on change velocity. According to AWS best practices, organizations should test DR procedures quarterly at minimum. Startups with frequent infrastructure changes may need monthly testing.
Keeping DR aligned with growth requires regular review. As you add new services, databases, and integrations, your DR plan must expand to cover them. Schedule quarterly reviews to ensure coverage remains complete.
Balancing Disaster Recovery, Cost, and Complexity
DR investments should scale with your business, not ahead of it.
Avoiding over-engineering preserves resources for growth. Multi-region active-active architectures cost significantly more and add operational complexity. Most early-stage startups do not need this level of protection.
Cost-aware DR decisions consider probability and impact together. Regional AWS outages are rare. Data corruption from bad deployments happens more frequently. Prioritize protection against likely failures first.
Scaling DR as the startup grows makes investment incremental. Start with backup-and-restore. Add pilot light when you have paying customers who expect uptime guarantees. Move to warm standby when revenue justifies the cost.
When Lean Teams Need Help with AWS DR Planning
Certain situations indicate the value of external expertise.
Warning signs your DR is insufficient include failed recovery tests, DR plans older than your current architecture, and no documented procedures at all. If any of these apply, your current protection provides less value than you assume.
Risks of ad-hoc recovery become apparent during actual incidents. Improvised recovery procedures take longer, create more errors, and often result in data loss that proper planning would prevent.
Value of expert guidance lies in experience across many similar situations. An AWS consulting services has seen common failure patterns and proven recovery approaches that your team would otherwise learn through painful experience.
How EaseCloud Helps Startups Build Practical DR Plans
EaseCloud brings enterprise DR expertise to startup-appropriate solutions.
DR readiness assessments evaluate your current protection and identify gaps. You receive prioritized recommendations matched to your stage and budget.
AWS-based DR architecture implements proven patterns for your specific technology stack. From cross-region RDS replication to automated failover configurations, EaseCloud brings experience from dozens of similar implementations.
Ongoing reliability support ensures your DR capabilities evolve with your business. As you scale, your protection scales with you.
Ready to protect your startup against the unexpected? Contact EaseCloud for a DR readiness assessment.
Final Thoughts
Disaster recovery is about preparedness, not perfection. Lean startup teams cannot match enterprise DR investments, nor do they need to. Right-sized strategies provide meaningful protection at costs that fit startup budgets.
Start with honest assessment of your RTO and RPO requirements. Implement backup-and-restore as a foundation. Add sophistication as your business grows and requirements tighten. Test your plans regularly. The goal is not eliminating all disaster risk but reducing it to levels your business can absorb.
FAQs
Do early-stage startups need disaster recovery?
Yes. The question is not whether to have DR, but how sophisticated it needs to be. Even pre-revenue startups should maintain cross-region backups and basic recovery documentation. The cost is minimal and the protection is meaningful.
What's the simplest DR strategy for startups?
Backup and restore provides the simplest starting point. Configure automated daily backups of databases and critical data. Enable cross-region replication. Document restore procedures. Test quarterly. This approach costs tens of dollars monthly and protects against most disaster scenarios.
How expensive is disaster recovery on AWS?
Costs vary by strategy. Backup-and-restore adds 5-10% to storage costs. Pilot light configurations typically add 10-20% to infrastructure costs. Warm standby may add 30-50%. The right answer depends on your RTO requirements and risk tolerance.
How often should startups test DR plans?
Quarterly testing represents the minimum standard. Startups with high change velocity should test monthly. Each test should include actual restoration from backups, verification of recovered data, and timing measurement against RTO targets.
Can DR be added later as the startup scales?
Yes, DR capabilities can be implemented incrementally. However, postponing all DR planning until scale creates unnecessary risk. Start with basic backup-and-restore, then add sophistication as requirements grow.