Scaling Airbyte on Kubernetes
Complete guide to scaling Airbyte on ARM64 Kubernetes clusters. Learn real-world solutions for Temporal issues, PostgreSQL optimization, and cost-effective production deployment.

Master the hidden challenges, performance optimizations, and architectural decisions for running Airbyte at scale on ARM-based Kubernetes clusters
TL;DR
Scaling Airbyte on ARM64 Kubernetes is cost-effective but comes with hidden gotchas. Key takeaways:
- PostgreSQL CPU bottlenecks cause "workflow restarted" errors before Airbyte scales become the issue
- Temporal connectivity issues occur after hours/days due to stale gRPC connections
- Most "TEMPORAL_GRPC_*" environment variables aren't supported in Airbyte 1.8 - stick to official ones
- ARM64 offers 20-40% cost savings but requires proper tolerations and testing
- Database scaling is critical - upgrade from 2 vCPU to 4+ vCPU PostgreSQL instances early
- Connection pool alignment between Airbyte and PostgreSQL prevents mysterious failures
Bottom line: Focus on database performance first, then Airbyte scaling. A 4 vCPU PostgreSQL instance can handle 15+ concurrent syncs reliably on ARM64 infrastructure.
Introduction
Running Airbyte on Kubernetes seems straightforward until you hit production scale. Add ARM infrastructure to the mix, and you'll discover a whole new set of challenges that the documentation doesn't warn you about. After deploying and scaling Airbyte 1.8 on Google Kubernetes Engine (GKE) with ARM64 nodes and Cloud SQL, I've learned some hard lessons that could save you weeks of troubleshooting.
This post covers the real-world caveats, performance bottlenecks, and architectural decisions you need to know when scaling Airbyte on ARM-based Kubernetes infrastructure. If you're looking for expert Docker and Kubernetes consulting services to implement these optimizations, EaseCloud specializes in production-ready containerized data platforms.
The Setup: What We Built
Our production environment consists of:
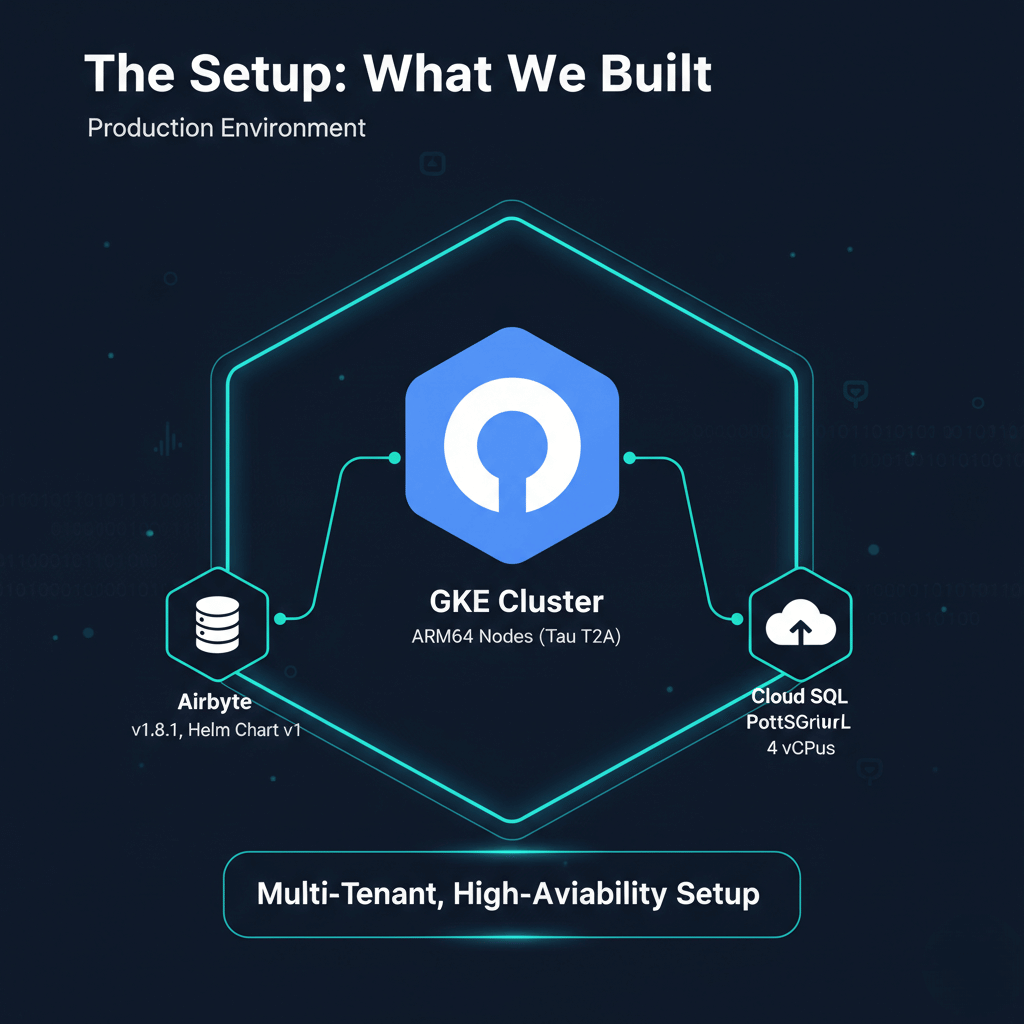
- GKE Cluster: ARM64 nodes (t2a-standard-16, Tau T2A processors)
- Airbyte: Version 1.8.1 (Helm Chart v1)
- Database: Cloud SQL PostgreSQL (initially 2 vCPUs, upgraded to 4 vCPUs)
- Storage: Google Cloud Storage
- Architecture: Multi-tenant, high-availability setup
The Hidden Challenges Nobody Talks About
1. Temporal Worker Connectivity Issues
The Problem: After running for hours or days, Airbyte workers would mysteriously stop polling the SYNC task queue, leading to:
No Workers Running - There are no Workers polling the SYNC Task Queue
Workflow task timed out
Warning from airbyte_platform: An internal transient Airbyte error has occurred
Root Cause: Long-running gRPC connections between workers and Temporal become stale without proper keep-alive configuration.
The Fix: Contrary to what you might find online, most "Temporal gRPC" environment variables are NOT officially supported in Airbyte 1.8. Here are the actually supported worker environment variables:
worker:
env:
- name: WORKER_ENVIRONMENT
value: kubernetes
- name: MAX_SYNC_WORKERS
value: "15"
- name: MAX_SPEC_WORKERS
value: "5"
- name: MAX_CHECK_WORKERS
value: "5"
- name: MAX_DISCOVER_WORKERS
value: "5"
- name: JAVA_OPTS
value: "-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp -Xms2g -Xmx3g"
Caveat: Avoid using unsupported environment variables like TEMPORAL_GRPC_KEEP_ALIVE_* - they'll be silently ignored and won't solve your connectivity issues.
2. ARM64 Compatibility and Performance
The Challenge: Not all Airbyte connectors are optimized for ARM64, and some Docker images may fall back to emulation.
Key Considerations:
global:
tolerations:
- key: kubernetes.io/arch
operator: Equal
value: arm64
effect: NoSchedule
# Apply to ALL services
webapp:
tolerations:
- key: kubernetes.io/arch
operator: Equal
value: arm64
effect: NoSchedule
Performance Tip: ARM64 nodes offer better price/performance for data processing workloads, but monitor CPU usage closely during initial deployment.
3. PostgreSQL: The Real Bottleneck
The Shocking Reality: A 2 vCPU PostgreSQL instance will become your biggest bottleneck long before you think about Airbyte scaling.
Symptoms:
- CPU spikes to 100%
Setting attempt to FAILED because the workflow for this connection was restarted- Database connection timeouts
- Temporal workflow restarts
Why This Happens:
- Temporal maintains massive history tables
- Multiple concurrent syncs create heavy database load
- Autovacuum operations compete for CPU resources
- Connection pooling becomes ineffective under high load
The Solution: Scale your database FIRST, then worry about Airbyte scaling.
Production-Ready PostgreSQL Configuration
Cloud SQL Optimization for Airbyte Workloads
Based on our experience, here's the optimized Cloud SQL configuration for a db-perf-optimized-N-4 (4 vCPUs, 32 GiB RAM) instance:
gcloud sql instances patch your-postgres-instance \
--database-flags \
max_connections=400,\
shared_buffers=2516582,\
work_mem=32768,\
maintenance_work_mem=1048576,\
effective_cache_size=2936012,\
wal_buffers=32768,\
checkpoint_timeout=900,\
checkpoint_completion_target=0.9,\
max_wal_size=4096,\
min_wal_size=1024,\
random_page_cost=1.1,\
effective_io_concurrency=200,\
max_worker_processes=8,\
max_parallel_workers=4,\
max_parallel_workers_per_gather=2,\
tcp_keepalives_idle=240,\
tcp_keepalives_interval=30,\
tcp_keepalives_count=10,\
autovacuum_max_workers=3,\
log_min_duration_statement=1000,\
log_connections=on,\
log_disconnections=on
Connection Pool Alignment
Match your Airbyte connection pool settings to PostgreSQL limits:
global:
env_vars:
HIKARI_MAXIMUM_POOL_SIZE: "40" # Calculated for 400 max connections
HIKARI_MINIMUM_IDLE: "10"
HIKARI_CONNECTION_TIMEOUT: "5000"
HIKARI_IDLE_TIMEOUT: "300000"
HIKARI_MAX_LIFETIME: "900000"
High-Availability Architecture Patterns
Multi-Replica Setup
# Server HA
server:
replicaCount: 3
podDisruptionBudget:
enabled: true
minAvailable: 2
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- server
topologyKey: kubernetes.io/hostname
# Worker HA with proper resource allocation
worker:
replicaCount: 3
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 2
memory: 4Gi
Temporal High Availability
temporal:
replicaCount: 3
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 2000m
memory: 4Gi
Resource Sizing Guidelines
Node Pool Recommendations
For production Airbyte on ARM64:
- Airbyte Services:
t2a-standard-8(8 vCPUs, 32 GiB) minimum - Job Execution: Dedicated node pool with
t2a-standard-16(16 vCPUs, 64 GiB) - Temporal: Can share with Airbyte services but monitor memory usage
Database Sizing Reality Check
| Concurrent Syncs | Recommended PostgreSQL Tier | Why |
|---|---|---|
| 1-5 | db-perf-optimized-N-2 | Development only |
| 5-15 | db-perf-optimized-N-4 | Production minimum |
| 15-30 | db-perf-optimized-N-8 | High-volume production |
| 30+ | db-perf-optimized-N-16+ | Enterprise scale |
Caveat: These are MINIMUM requirements. Temporal's history tables grow exponentially with job complexity.
Job Scheduling and Resource Management
Dedicated Job Pools
global:
jobs:
resources:
requests:
memory: 2Gi
cpu: 500m
limits:
memory: 8Gi
cpu: 4
kube:
nodeSelector:
workload: airbyte-jobs
tolerations:
- key: airbyte-jobs
operator: Equal
value: "true"
effect: NoSchedule
Worker Limits That Actually Work
worker:
env:
- name: MAX_SYNC_WORKERS
value: "15" # Don't go higher on 4 vCPU database
- name: MAX_SPEC_WORKERS
value: "5"
- name: MAX_CHECK_WORKERS
value: "5"
Critical Insight: These limits are per worker pod, not global. With 3 worker replicas, you can have 45 concurrent sync jobs, which will overwhelm a small database.
Monitoring and Observability
Key Metrics to Watch
-
PostgreSQL CPU Utilization
- Alert at >80% sustained
- Scale database before hitting 100%
-
Temporal Task Queue Length
kubectl exec -n airbyte temporal-pod -- tctl --namespace default taskqueue describe --taskqueue SYNC -
Worker Memory Usage
- Monitor for OOM kills
- ARM64 has different memory patterns than x86
-
Connection Pool Exhaustion
HIKARI_LEAK_DETECTION_THRESHOLD: "30000"
Troubleshooting Common Issues
"No Workers Running" Error
- Check worker pod logs for connection errors
- Verify Temporal service connectivity
- Restart worker deployment if connections are stale
- Consider PostgreSQL performance issues
Workflow Restarts and State Cleaning
This is almost always a database performance issue:
- Check PostgreSQL CPU usage
- Look for slow queries (>1000ms)
- Scale database or reduce concurrent syncs
- Monitor connection pool metrics
ARM64 Specific Issues
- Image Compatibility: Some connectors may not have native ARM64 builds
- Performance Variations: Monitor job execution times compared to x86 baselines
- Memory Management: ARM64 may have different garbage collection patterns
Cost Optimization Strategies
Right-Sizing for ARM64
ARM64 instances offer 20-40% cost savings but require careful sizing:
# Cost-optimized production setup
webapp:
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 1
memory: 2Gi
server:
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 2
memory: 4Gi
Database Cost vs Performance
- Don't under-provision the database - it's always cheaper to scale the database than deal with failed syncs
- Monitor connection utilization - unused connection capacity is wasted money
- Use read replicas for reporting and monitoring queries
Production Deployment Checklist
Pre-Deployment
- [ ] ARM64 tolerations configured for all services
- [ ] Database sized for expected concurrent syncs
- [ ] Dedicated node pools for job execution
- [ ] Connection pool limits aligned with database capacity
- [ ] Resource limits set to prevent resource starvation
Post-Deployment Monitoring
- [ ] PostgreSQL CPU and memory usage
- [ ] Temporal task queue health
- [ ] Worker pod restart rates
- [ ] Job success/failure rates
- [ ] Connection pool utilization
Scale-Out Triggers
- [ ] Database CPU >80% sustained
- [ ] Worker memory usage >70%
- [ ] Task queue backlog growing
- [ ] Job timeout increases
Lessons Learned: What We Wish We Knew
- Scale the database first: Your biggest bottleneck will always be PostgreSQL, not Airbyte
- ARM64 works great: But test your specific connectors thoroughly
- Connection pooling is critical: Misaligned pool sizes cause mysterious failures
- Temporal needs resources: Don't treat it as lightweight - it processes massive amounts of workflow state
- Job isolation matters: Separate node pools prevent noisy neighbor problems
- Monitor everything: ARM64 performance characteristics are different from x86
Conclusion
Scaling Airbyte on ARM-based Kubernetes is absolutely achievable and cost-effective, but it requires understanding the real bottlenecks and failure modes. The biggest lesson: your database will be the limiting factor long before Airbyte itself becomes the bottleneck.
Focus on:
- Database performance (CPU, memory, connection limits)
- Proper ARM64 configuration (tolerations, node selectors)
- Resource isolation (dedicated job pools)
- Connection pool alignment (Hikari settings matching PostgreSQL limits)
- Temporal stability (adequate resources, monitoring)
With these optimizations, you can run a stable, high-performance Airbyte deployment that handles hundreds of concurrent data pipelines on cost-effective ARM infrastructure.
Need Expert Help with Your Airbyte Deployment?
Implementing these optimizations and scaling Airbyte on ARM64 Kubernetes requires deep expertise in container orchestration, database performance tuning, and data platform architecture. Don't spend months troubleshooting production issues – let the experts handle it.
EaseCloud's data engineering team has successfully deployed and scaled Airbyte for enterprises handling terabytes of data daily. We specialize in:
- ✅ Production-ready Airbyte deployments on Kubernetes
- ✅ ARM64 optimization for cost-effective scaling
- ✅ Database performance tuning for high-throughput data pipelines
- ✅ Multi-tenant architecture design and implementation
- ✅ 24/7 monitoring and support for mission-critical data infrastructure
Ready to scale your data platform without the headaches? Get in touch with our team for a free consultation on your Airbyte scaling strategy.
Frequently Asked Questions (FAQs)
1. Why does my Airbyte deployment show "No Workers Running" after running for days?
This is typically caused by stale gRPC connections between Airbyte workers and Temporal. The connections become idle and aren't properly refreshed. The solution is to restart the worker pods or implement proper connection lifecycle management. Avoid using unsupported TEMPORAL_GRPC_* environment variables - they won't solve this issue.
2. What's the minimum PostgreSQL instance size for production Airbyte on ARM64?
For production workloads, start with a db-perf-optimized-N-4 (4 vCPUs, 32 GiB RAM) instance. A 2 vCPU instance will quickly become a bottleneck, causing workflow restarts and sync failures. The database is always the first bottleneck, not Airbyte itself.
3. Are there performance differences between ARM64 and x86 for Airbyte workloads?
ARM64 generally offers 20-40% cost savings with comparable performance for data processing workloads. However, some connectors may not have native ARM64 builds and will fall back to emulation, which can impact performance. Test your specific connectors thoroughly before production deployment.
4. How many concurrent syncs can a single Airbyte worker handle?
This depends on your database capacity, not the worker itself. With proper PostgreSQL sizing (4+ vCPUs), you can handle 15+ concurrent syncs per worker pod. However, the MAX_SYNC_WORKERS setting is per pod - with 3 worker replicas, you could have 45+ concurrent jobs, which may overwhelm your database.
5. What causes "Setting attempt to FAILED because the workflow was restarted" errors?
This error is almost always related to database performance issues. When PostgreSQL CPU hits 100%, database queries slow down, connection timeouts occur, and Temporal can't write workflow state. The solution is to scale your PostgreSQL instance, not increase Airbyte resources.