Run GLM-4 for Chinese Enterprise Applications
Deploy GLM-4 for enterprise Chinese applications. Production guide covering cloud deployment, fine-tuning, enterprise integration, and cost optimization strategies.

TLDR;
- Achieves 87% C-Eval accuracy for superior Chinese language understanding
- GLM-4 9B costs $8/month, GLM-4 32B reaches $180/month on Alibaba Cloud
- Native function calling enables enterprise database and system integration
- LoRA fine-tuning reduces training costs by 80% while customizing domain vocabulary
Deploy GLM-4 for enterprise applications requiring exceptional Chinese language capabilities and business system integration. Developed by Zhipu AI, a Tsinghua University spinoff, GLM-4 achieves 87% accuracy on C-Eval Chinese benchmarks while providing enterprise-grade SLAs and government compliance. This model excels in customer service automation, knowledge management, document processing, and financial services applications across Chinese markets. GLM-4 offers two deployment variants: the 9B parameter model for cost-sensitive deployments at $8 monthly, and the 32B parameter version for complex reasoning tasks at $180 monthly. Organizations choose GLM-4 for superior Chinese comprehension, native function calling capabilities, on-premise deployment options, and strong data sovereignty guarantees. This guide covers production deployment across Alibaba Cloud, AWS SageMaker, and Azure ML enterprise fine-tuning workflows using LoRA for 80% cost reduction, integration patterns with Salesforce and SAP systems, and monitoring strategies for production quality assurance.
Model Variants and Selection
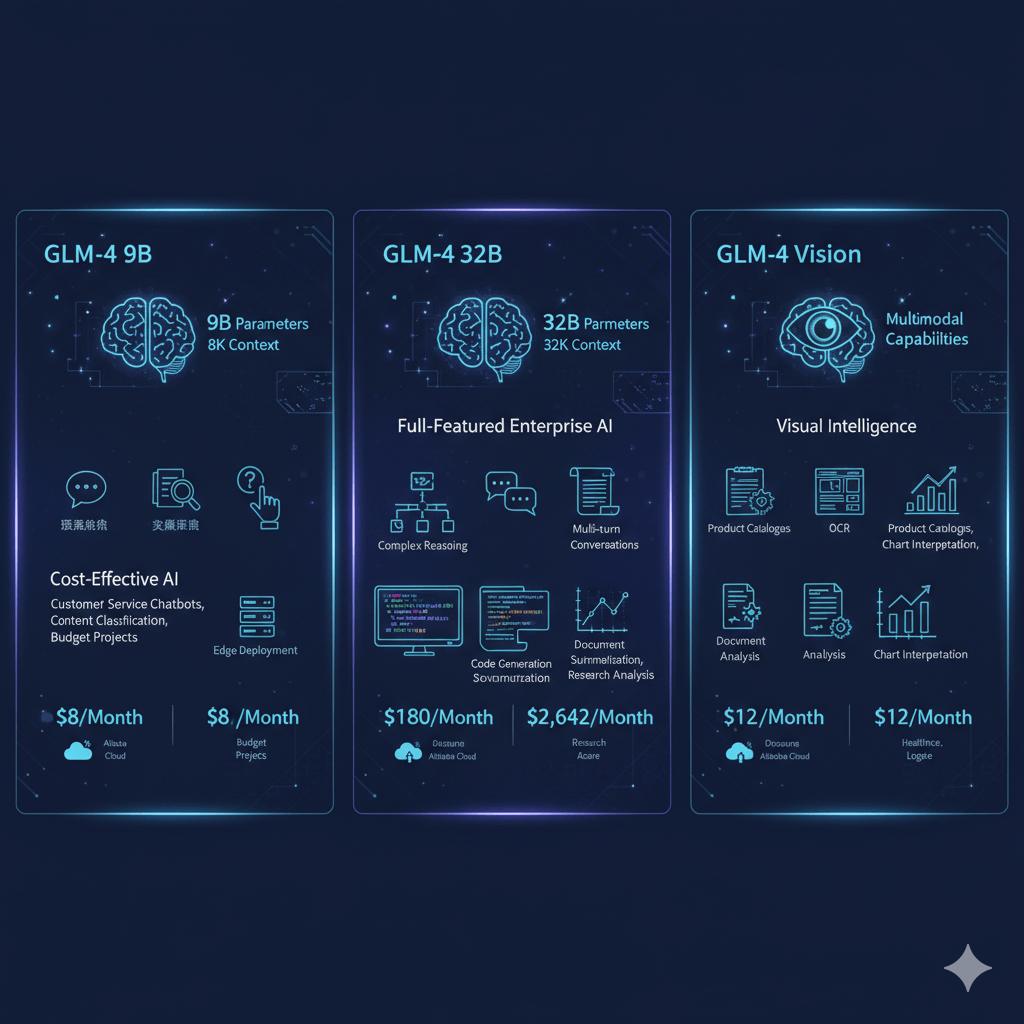
GLM-4 offers three variants optimized for different enterprise needs. GLM-4 9B provides cost-effective deployment with 9 billion parameters, 8K context window, and 18GB memory requirements in FP16 precision. This variant achieves 120 tokens per second throughput on single NVIDIA A10 GPU, making it ideal for customer service chatbots handling Chinese customer inquiries, content classification systems organizing Chinese documents, simple question-answering applications for employee support, budget-constrained projects requiring Chinese language capability, and edge deployment scenarios in retail or manufacturing environments. Monthly deployment cost reaches only $8 on Alibaba Cloud ecs.gn7-c8g1.2xlarge instances or $12 on Azure Standard_NC6s_v3.
GLM-4 32B delivers full-featured enterprise capabilities with 32 billion parameters, 32K context window supporting long document processing, and 64GB memory requirements for production deployment. Processing 60 tokens per second on 4x A10 GPUs, this model handles complex reasoning tasks requiring multi-step logic, multi-turn conversations maintaining context across extended dialogues, document summarization condensing lengthy Chinese business reports, code generation producing Python and JavaScript with Chinese comments, and research analysis processing academic papers in Chinese. Monthly cost reaches $180 for Alibaba Cloud deployment on ecs.gn7i-c32g1.8xlarge instances or $2,642 on Azure Standard_NC24ads_A100_v4. GLM-4 Vision extends capabilities to multimodal applications, supporting image understanding for product catalogs, OCR extracting text from scanned Chinese documents, document analysis processing invoices and contracts, and chart interpretation analyzing business metrics from visualizations. This variant serves industries requiring visual document processing including finance, healthcare, legal, and e-commerce sectors.
Cloud Deployment
Alibaba Cloud provides native GLM-4 support through PAI-EAS platform with simplified deployment. Azure ML offers enterprise-grade hosting with hybrid cloud integration. AWS SageMaker enables deployment via HuggingFace containers for global reach.
# Deploy via PAI-EAS
aliyun pai CreateService \
--ServiceName glm4-32b-service \
--ModelId glm4-32b-chat \
--InstanceType ecs.gn7i-c32g1.8xlarge \
--Replicas 2 \
--AutoScaling '{"min": 2, "max": 10, "metric": "cpu", "target": 70}'
# Get endpoint
ENDPOINT=$(aliyun pai DescribeService --ServiceName glm4-32b-service --query 'InternetEndpoint' --output text)
# Test inference
curl -X POST $ENDPOINT/api/predict \
-H "Content-Type: application/json" \
-d '{
"prompt": "解释量子计算的基本原理",
"max_tokens": 500,
"temperature": 0.7
}'
Alibaba Cloud pricing: GLM-4 9B costs $8 monthly on ecs.gn7-c8g1.2xlarge instances, while GLM-4 32B requires $180 monthly for ecs.gn7i-c32g1.8xlarge instances.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import ManagedOnlineDeployment, ManagedOnlineEndpoint, Model, Environment, CodeConfiguration
# Initialize client
ml_client = MLClient.from_config()
# Create endpoint
endpoint = ManagedOnlineEndpoint(
name="glm4-enterprise-endpoint",
description="GLM-4 32B for enterprise applications",
auth_mode="key"
)
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
# Deploy model
deployment = ManagedOnlineDeployment(
name="glm4-32b-deployment",
endpoint_name="glm4-enterprise-endpoint",
model=Model(path="azureml://models/glm-4-32b/versions/1"),
environment=Environment(
conda_file="environment.yml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.8-cudnn8-ubuntu22.04"
),
instance_type="Standard_NC24ads_A100_v4",
instance_count=2,
request_settings={
"request_timeout_ms": 90000,
"max_concurrent_requests_per_instance": 4
},
liveness_probe={
"period": 30,
"timeout": 2,
"failure_threshold": 3
}
)
ml_client.online_deployments.begin_create_or_update(deployment).result()
Azure pricing: Standard_NC24ads_A100_v4 instances cost $3.67 hourly or $2,642 monthly for continuous deployment. Spot instances reduce costs to $1.10 hourly, providing 70% savings.
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
role = sagemaker.get_execution_role()
# Configure model
hub_config = {
'HF_MODEL_ID': 'THUDM/glm-4-32b',
'HF_TASK': 'text-generation',
'SM_NUM_GPUS': '4'
}
huggingface_model = HuggingFaceModel(
image_uri=f"763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-pytorch-tgi-inference:2.1.1-tgi1.4.0-gpu-py310-cu121-ubuntu22.04",
env=hub_config,
role=role
)
# Deploy endpoint
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type='ml.g5.12xlarge',
endpoint_name='glm4-32b-endpoint'
)
# Inference
response = predictor.predict({
"inputs": "写一个关于人工智能的短文",
"parameters": {
"max_new_tokens": 512,
"temperature": 0.8,
"top_p": 0.9
}
})
AWS pricing: ml.g5.12xlarge instances with 4x A10 GPUs cost $7.09 hourly or $5,105 monthly.
Enterprise Fine-Tuning
Customize GLM-4 for domain-specific applications using supervised fine-tuning or parameter-efficient LoRA methods. Standard fine-tuning costs $80-150 for GLM-4 9B and $300-500 for GLM-4 32B, requiring 4-12 hours on A100 GPUs. LoRA reduces training costs by 80% while maintaining quality, training only 0.09% of parameters.
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
import torch
# Load model
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"THUDM/glm-4-9b",
trust_remote_code=True
)
# Prepare company dataset
def preprocess_function(examples):
inputs = [f"问题:{q}\n回答:" for q in examples["question"]]
targets = examples["answer"]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
labels = tokenizer(targets, max_length=512, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
dataset = load_dataset("json", data_files="company_qa.jsonl")
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Training configuration
training_args = TrainingArguments(
output_dir="./glm4-finetuned",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
warmup_steps=100,
logging_steps=10,
save_steps=500,
fp16=True,
evaluation_strategy="steps",
eval_steps=500
)
# Train
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"]
)
trainer.train()
from peft import LoraConfig, get_peft_model, TaskType
# Configure LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # LoRA rank
lora_alpha=32,
lora_dropout=0.05,
target_modules=["query_key_value"]
)
# Apply LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 8M || all params: 9B || trainable%: 0.09%
# Train with same Trainer as above
Production Integration
Integrate GLM-4 into enterprise systems through REST APIs and function calling capabilities. Deploy FastAPI gateway for inference serving, implement function calling for database queries and system integration, and configure monitoring with Prometheus metrics tracking request counts, latency, and token generation.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import torch
app = FastAPI()
class InferenceRequest(BaseModel):
prompt: str
max_tokens: int = 512
temperature: float = 0.7
@app.post("/v1/completions")
async def generate(request: InferenceRequest):
try:
inputs = tokenizer(request.prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=request.max_tokens,
temperature=request.temperature,
do_sample=True
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {
"text": response,
"model": "glm-4-32b",
"usage": {
"prompt_tokens": len(inputs["input_ids"][0]),
"completion_tokens": len(outputs[0]) - len(inputs["input_ids"][0])
}
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# Run with: uvicorn app:app --host 0.0.0.0 --port 8000
GLM-4 function calling enables enterprise agent workflows:
functions = [
{
"name": "query_database",
"description": "查询企业数据库获取客户信息",
"parameters": {
"type": "object",
"properties": {
"customer_id": {"type": "string", "description": "客户ID"},
"fields": {"type": "array", "items": {"type": "string"}, "description": "要查询的字段"}
},
"required": ["customer_id"]
}
}
]
prompt = "帮我查询客户ID C12345 的订单历史和联系方式"
response = model.chat(
tokenizer,
prompt,
functions=functions,
temperature=0.1
)
# Response includes function call:
# {
# "function_call": {
# "name": "query_database",
# "arguments": {"customer_id": "C12345", "fields": ["orders", "contact"]}
# }
# }
Performance Monitoring
Track request volume, latency, and token generation using Prometheus metrics in production environments.
from prometheus_client import Counter, Histogram, start_http_server
import time
# Metrics
request_count = Counter('glm4_requests_total', 'Total inference requests')
request_duration = Histogram('glm4_request_duration_seconds', 'Request duration')
token_count = Counter('glm4_tokens_generated_total', 'Total tokens generated')
@request_duration.time()
async def generate_with_metrics(request: InferenceRequest):
request_count.inc()
start = time.time()
result = await generate(request)
latency = time.time() - start
token_count.inc(result["usage"]["completion_tokens"])
return result
# Start metrics server
start_http_server(9090)
Conclusion
GLM-4 delivers exceptional Chinese language understanding for enterprise applications, achieving 87% C-Eval accuracy while providing government compliance and enterprise SLAs. Deploy GLM-4 9B at $8 monthly for cost-sensitive chatbot applications, or GLM-4 32B at $180 monthly for complex reasoning and multi-turn conversations. Choose Alibaba Cloud for native Chinese market deployment, Azure ML for hybrid enterprise integration, or AWS SageMaker for global reach. Fine-tune models using LoRA to reduce training costs by 80% while customizing for domain-specific vocabulary and workflows. Integrate with Salesforce and SAP systems through REST APIs and function calling capabilities. Monitor production deployments using Prometheus metrics tracking latency, throughput, and error rates. GLM-4 provides optimal solution for Chinese-primary enterprise applications requiring data sovereignty, government approval, and superior language comprehension compared to Western alternatives.