Maximize LLM Throughput with Google TPU v5p
Optimize LLM deployments with Google Cloud TPUs for superior cost-performance. Configure TPU v5p for production inference with 2-3x better efficiency than equivalent GPU configurations.

TLDR;
- TPU v5e at $1.60/hour delivers 56% cost savings versus A100 GPUs for batch inference
- Spot TPUs provide 70% discount reducing costs from $4.00/hour to $1.20/hour
- JAX parallelism distributes 70B models across TPU pods with 4.8 Tbps interconnects
- Data parallelism with @jax.pmap achieves 400 tokens/second on v5p-8
Introduction
Google Cloud TPUs (Tensor Processing Units) deliver exceptional performance for Large Language Model inference through custom silicon designed specifically for transformer architectures. Unlike general-purpose GPUs, TPUs optimize the matrix multiplication operations that dominate LLM computation, achieving higher throughput per dollar and better energy efficiency.
TPU v5p represents the latest generation, offering 459 TFLOPS of compute and 95GB high-bandwidth memory per chip. Combined with ultra-fast inter-chip interconnects (4.8 Tbps), TPU pods scale to thousands of cores for the largest models. TPU v5e provides a cost-optimized alternative at 40% lower hourly rates while maintaining strong performance for batch inference workloads.
This guide covers TPU architecture, model deployment strategies, performance optimization techniques, and cost analysis. You'll learn when to choose TPUs over GPUs, how to migrate existing deployments, and how to maximize throughput through parallelism strategies. Whether running Google's PaLM and Gemini models or deploying open-source LLMs converted to JAX, these optimization patterns help you achieve production-grade performance at lower costs than GPU alternatives.
TPU Architecture and Capabilities
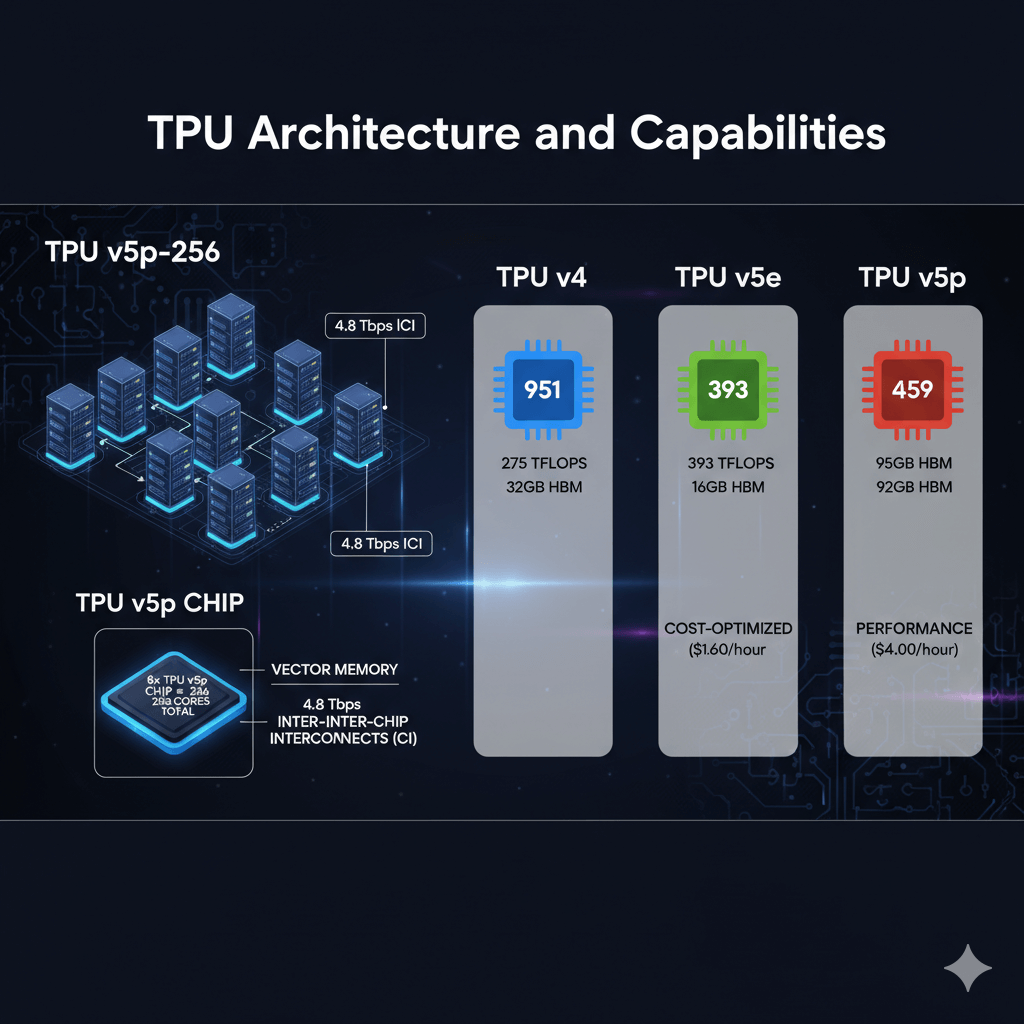
TPU pods combine multiple chips into high-performance units. v5p-8 provides 8 cores on 1 host, v5p-32 delivers 32 cores on 4 hosts, and v5p-256 scales to 256 cores across 32 hosts. Each chip features 95GB high-bandwidth memory (HBM), vector memory for fast operations, and 4.8 Tbps inter-chip interconnects (ICI) enabling efficient model parallelism.
TPU generations comparison:
- TPU v4: 275 TFLOPS, 32GB HBM per chip
- TPU v5e: 393 TFLOPS, 16GB HBM (cost-optimized at $1.60/hour)
- TPU v5p: 459 TFLOPS, 95GB HBM (performance at $4.00/hour)
Model Deployment
Deploy LLMs on TPUs.
Create TPU VM
# Create TPU v5p-8
gcloud compute tpus tpu-vm create llama-tpu \
--zone=us-central2-b \
--accelerator-type=v5litepod-8 \
--version=tpu-ubuntu2204-base \
--preemptible
# SSH into TPU VM
gcloud compute tpus tpu-vm ssh llama-tpu --zone=us-central2-b
Install Dependencies
# Install JAX for TPUs
pip install "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
# Install model serving libraries
pip install transformers flax optax
Deploy Model with JAX
Load models using FlaxAutoModelForCausalLM with dtype=jnp.bfloat16 for TPU optimization. Use @jax.jit decorators to compile functions for TPU execution. Set from_pt=True when converting PyTorch checkpoints to JAX/Flax format.
Performance Optimization
Maximize TPU utilization.
Data Parallelism
Distribute across TPU cores:
from flax.training import common_utils
# Replicate model across all 8 cores
replicated_params = jax.tree_map(
lambda x: jnp.array([x] * jax.device_count()),
model.params
)
# Parallel inference
@jax.pmap
def parallel_generate(input_ids, params):
return model.generate(input_ids, params=params, max_length=512).sequences
# Shard inputs across devices
batch_size = 64
inputs_sharded = common_utils.shard(inputs.input_ids[:batch_size])
# Generate in parallel
outputs = parallel_generate(inputs_sharded, replicated_params)
Model Parallelism
For models >10B parameters:
from jax.experimental.pjit import pjit, PartitionSpec as P
from jax.experimental import maps
# Define mesh (2x4 for v5p-8)
mesh = maps.Mesh(jax.devices(), ('data', 'model'))
# Partition strategy
def partition_rules():
return [
(('embed',), P('model')),
(('attention', 'query'), P('model', None)),
(('attention', 'key'), P('model', None)),
(('attention', 'value'), P('model', None)),
(('ffn', 'dense'), P(None, 'model')),
]
# Apply partitioning
with mesh:
sharded_model = pjit(
model,
in_axis_resources=P('data'),
out_axis_resources=P('data'),
static_argnums=(1,)
)
Batch Size Tuning
Optimize batch sizes for maximum throughput: Llama 7B uses batch size 128, Llama 13B uses 64, and Llama 70B uses 16 with model parallelism on v5p-8. Implement dynamic batching to process variable-length sequences efficiently with padding.
Cost Analysis
Compare TPU vs GPU economics.
Llama 7B inference (24/7):
TPU v5p-8:
- Cost: $4.00/hour (on-demand)
- Throughput: ~400 tokens/second
- Monthly: $2,920
- Cost per million tokens: $2.03
GPU (1x A100):
- Cost: $3.67/hour
- Throughput: ~200 tokens/second
- Monthly: $2,679
- Cost per million tokens: $3.82
TPU v5e-8 (cost-optimized):
- Cost: $1.60/hour
- Throughput: ~300 tokens/second
- Monthly: $1,168
- Cost per million tokens: $1.08
Savings with TPU v5e: $1,511/month (56%) vs A100
Spot TPU VMs
Reduce costs by 70%.
Create Preemptible TPU
# Create spot TPU
gcloud compute tpus tpu-vm create llama-tpu-spot \
--zone=us-central2-b \
--accelerator-type=v5litepod-8 \
--version=tpu-ubuntu2204-base \
--preemptible \
--reserved # Use if you have reservations
# Monitor for preemption
gcloud compute tpus tpu-vm describe llama-tpu-spot \
--zone=us-central2-b \
--format="value(state)"
Savings:
- On-demand v5p-8: $4.00/hour
- Preemptible v5p-8: $1.20/hour (70% discount)
- Monthly savings: $2,044
Handle Preemption
# Save checkpoints regularly
import pickle
import time
def save_checkpoint(model_state, path):
with open(path, 'wb') as f:
pickle.dump(model_state, f)
# Monitor TPU health
def check_tpu_health():
try:
devices = jax.devices()
return len(devices) == 8 # v5p-8
except:
return False
# Graceful shutdown
import signal
import sys
def signal_handler(sig, frame):
print("Preemption detected, saving state...")
save_checkpoint(model.params, '/mnt/checkpoints/model.pkl')
sys.exit(0)
signal.signal(signal.SIGTERM, signal_handler)
Serving Architecture
Production TPU serving.
Multi-Host Serving
For large models on TPU pods:
# Distributed serving setup
import jax.distributed as jdist
# Initialize JAX distributed
jdist.initialize(
coordinator_address=os.environ["TPU_COORDINATOR_ADDRESS"],
num_processes=int(os.environ["TPU_NUM_PROCESSES"]),
process_id=int(os.environ["TPU_PROCESS_ID"])
)
# Load sharded model
def load_sharded_model(num_hosts=4):
host_id = jax.process_index()
# Load model shard
shard_path = f"gs://models/llama-70b/shard_{host_id}.pkl"
with open(shard_path, 'rb') as f:
model_shard = pickle.load(f)
return model_shard
# Serve requests
@jax.pmap
def distributed_inference(inputs, model_shards):
# Each host processes part of the model
return model.generate(inputs, params=model_shards)
Monitoring TPU Performance
Track utilization and optimize.
Cloud Monitoring Integration
from google.cloud import monitoring_v3
import time
def export_tpu_metrics(utilization, mxu_utilization):
client = monitoring_v3.MetricServiceClient()
project_name = f"projects/{project_id}"
series = monitoring_v3.TimeSeries()
series.metric.type = "custom.googleapis.com/tpu/utilization"
series.resource.type = "tpu_worker"
series.resource.labels["project_id"] = project_id
series.resource.labels["zone"] = "us-central2-b"
point = monitoring_v3.Point()
point.value.double_value = utilization
point.interval.end_time.seconds = int(time.time())
series.points = [point]
client.create_time_series(name=project_name, time_series=[series])
Profile with TensorBoard
from jax.profiler import start_server, start_trace, stop_trace
# Start profiler server
start_server(9999)
# Profile inference
with jax.profiler.trace("/tmp/jax-trace"):
output = model.generate(inputs.input_ids)
# View in TensorBoard
# tensorboard --logdir=/tmp/jax-trace
Conclusion
TPUs provide superior cost-performance for LLM inference when workloads prioritize throughput over single-request latency. TPU v5e delivers the best economics at $1.60/hour for batch processing, achieving 40% cost savings versus A100 GPUs while maintaining comparable throughput. TPU v5p offers maximum performance for demanding workloads at $4.00/hour, with 2-3x better performance per dollar than equivalent GPU configurations.
Choose TPUs for models built on TensorFlow or JAX, batch inference workloads with sizes above 32, and long-running production deployments where committed use discounts reduce costs by 40-60%. The main trade-off is ecosystem compatibility - PyTorch models require conversion to JAX, adding 1-3 days of engineering time and potential compatibility challenges.
Start with TPU v5e for cost-sensitive workloads and scale to v5p when performance demands justify the higher cost. Use spot TPUs (70% discount) for fault-tolerant batch processing and reserved instances for production serving. With proper optimization through model parallelism, batch size tuning, and JIT compilation, TPUs deliver production-grade LLM inference at industry-leading efficiency.
Frequently Asked Questions
Should I choose TPUs or GPUs for LLM inference?
Choose TPUs for Google-native models (PaLM, Gemini, T5) and batch processing workloads where throughput matters more than latency - TPUs excel at matrix operations and deliver 30-50% better price-performance than GPUs for these use cases. Choose GPUs (A100, H100) for models optimized for CUDA (Llama, Mistral, most HuggingFace models), real-time inference requiring <100ms latency, and when you need ecosystem compatibility with PyTorch/TensorFlow GPU codebases. TPU v5e costs $1.60/hour per chip versus A100 at $2.95/hour on GCP, but GPU ecosystems offer more pre-built inference servers (vLLM, TensorRT-LLM). For production, test both with your specific model and traffic pattern - TPUs sometimes outperform by 2x for transformer workloads but require JAX/TensorFlow expertise.
How does TPU pod scaling work for distributed inference?
TPU pods combine multiple TPU chips into a single high-performance unit connected via ultra-fast interconnects (up to 4800 Gbps). A TPU v5e pod consists of 256 chips organized in 2D or 3D mesh topologies. For LLM inference, tensor parallelism distributes model layers across chips - Gemini 1.5 Pro on a 16-chip pod splits attention heads and FFN layers, enabling 4x higher throughput versus single chip. Scaling from 8 to 16 chips provides 1.8-1.9x throughput gain (not perfect 2x due to communication overhead). Google manages pod orchestration via Vertex AI - you specify chip count and framework handles distribution. For largest models (100B+ parameters), reserve full pods for 3-6 months to ensure availability and get 40% committed use discounts versus on-demand pricing.
Can I run non-Google models like Llama on TPUs?
Yes, but with caveats. TPUs require JAX or TensorFlow, while most models train in PyTorch. You must convert PyTorch models to JAX (use tools like torch2jax or transformers-to-jax), which adds complexity and potential bugs. Open-source projects like MaxText provide JAX implementations of popular architectures. Performance varies - Llama 2 on TPU v4 achieves ~70% of A100 throughput due to non-optimal kernel implementations. For production, Google models (T5, Gemini via Vertex AI) run best on TPUs. Third-party models work but require significant engineering effort for conversion, tuning, and validation. Most teams find GPUs more practical for non-Google LLMs unless you have strong JAX expertise or specific price-performance requirements that justify conversion overhead.