Deploy DeepSeek R1 for Math and Coding Tasks
Deploy DeepSeek R1 reasoning model for math, coding, and problem-solving. Production setup guide covering AWS, GCP, Azure deployment, optimization, and integration.

TLDR;
- Achieves 89.4% GSM8K math and 78.6% HumanEval coding accuracy with chain-of-thought reasoning
- MoE architecture activates only 37B of 671B parameters per token for efficient inference
- Self-hosted costs $0.60 per million tokens versus $30 for GPT-4 API (50x savings)
- INT4 quantization reduces memory from 1.3TB to 350GB for consumer GPU deployment
Deploy DeepSeek R1 for advanced reasoning applications requiring explicit step-by-step problem solving and chain-of-thought transparency. This mixture-of-experts model achieves 89.4% on GSM8K math benchmarks and 78.6% on HumanEval coding tests while activating only 37 billion of 671 billion total parameters per token. DeepSeek R1 provides cost-effective reasoning at $0.60 per million tokens, delivering performance approaching GPT-4 for mathematical problem solving, code generation, scientific reasoning, and educational tutoring applications. Organizations deploy R1 for educational platforms providing step-by-step explanations, code review assistants analyzing correctness and efficiency, research tools processing scientific data, and logic puzzle applications requiring multi-step deduction. This guide covers production deployment on AWS SageMaker using p4d.24xlarge instances at $32.77 hourly, GCP Vertex AI with a2-ultragpu-8g instances, Azure ML Standard_ND96asr_v4 deployment, quantization strategies reducing memory from 1.3TB to 350GB for consumer hardware, batch processing optimizations achieving 240 tokens per second throughput, and integration patterns building educational tutors and code review APIs.
Architecture and Capabilities
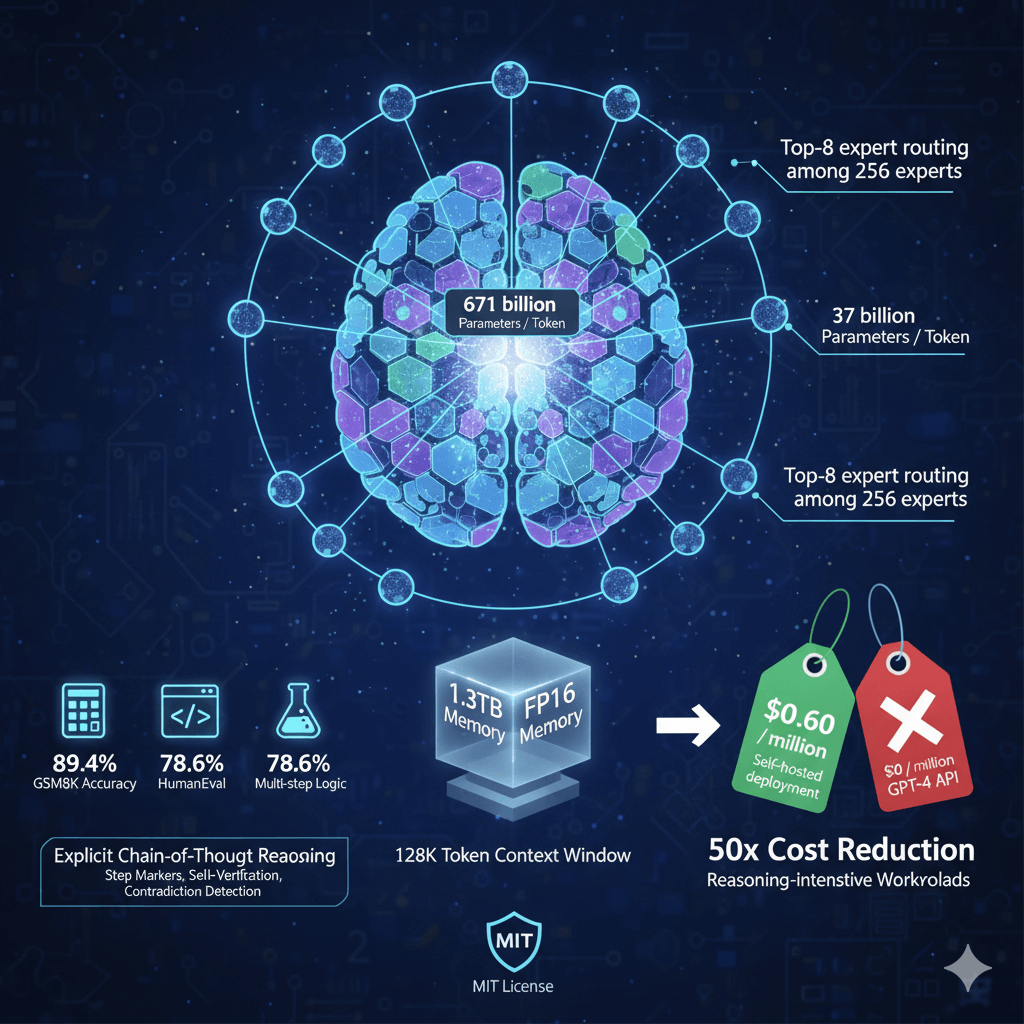
DeepSeek R1 uses sparse mixture-of-experts architecture with 671 billion total parameters, activating only 37 billion parameters per token through top-8 expert routing among 256 experts. This design delivers inference speed matching 37B dense models while achieving quality approaching 671B dense models. The model supports 128K token context windows and requires 1.3TB memory in FP16 precision.
R1 specializes in explicit chain-of-thought reasoning through training on reasoning datasets with step markers, self-verification capabilities, and contradiction detection. The model excels at mathematical problem solving with 89.4% GSM8K accuracy, coding tasks achieving 78.6% on HumanEval, and scientific reasoning requiring multi-step logic. MIT license enables commercial deployment without restrictions. Self-hosted deployment costs $0.60 per million tokens compared to $30 per million for GPT-4 API calls, providing 50x cost reduction for reasoning-intensive workloads.
Cloud Deployment
Deploy DeepSeek R1 on AWS SageMaker using p4d.24xlarge instances with 8x A100 80GB GPUs, GCP Vertex AI with a2-ultragpu-8g instances, or Azure ML Standard_ND96asr_v4 instances. All deployments require substantial GPU resources due to 671B parameter count, though MoE architecture activates only 37B per token.
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
role = sagemaker.get_execution_role()
# Configure DeepSeek R1 model
hub_config = {
'HF_MODEL_ID': 'deepseek-ai/DeepSeek-R1',
'HF_TASK': 'text-generation',
'SM_NUM_GPUS': '8', # Full p4d.24xlarge
'MAX_INPUT_LENGTH': '4096',
'MAX_TOTAL_TOKENS': '8192',
'MAX_BATCH_PREFILL_TOKENS': '16384'
}
# Use TGI (Text Generation Inference) container
model = HuggingFaceModel(
image_uri='763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-pytorch-tgi-inference:2.1.1-tgi1.4.0-gpu-py310-cu121-ubuntu22.04',
env=hub_config,
role=role
)
# Deploy to p4d.24xlarge (8x A100 80GB)
predictor = model.deploy(
initial_instance_count=1,
instance_type='ml.p4d.24xlarge',
endpoint_name='deepseek-r1-reasoning',
model_data_download_timeout=3600, # Large model needs time
container_startup_health_check_timeout=900
)
# Test reasoning
response = predictor.predict({
"inputs": "Solve step by step: If a train travels 120 km in 2 hours, and increases speed by 20%, how long will it take to travel 180 km?",
"parameters": {
"max_new_tokens": 1000,
"temperature": 0.1, # Low temp for reasoning
"do_sample": False,
"return_full_text": False
}
})
print(response[0]["generated_text"])
AWS costs: p4d.24xlarge instances cost $32.77 hourly or $23,595 monthly for continuous deployment. Spot instances reduce costs to $9.83 hourly, providing 70% savings.
from google.cloud import aiplatform
from google.cloud.aiplatform import gapic
# Initialize Vertex AI
aiplatform.init(project='your-project', location='us-central1')
# Upload model to Vertex AI
model = aiplatform.Model.upload(
display_name='deepseek-r1',
artifact_uri='gs://your-bucket/deepseek-r1',
serving_container_image_uri='gcr.io/your-project/deepseek-r1-tgi:latest',
serving_container_environment_variables={
'MODEL_ID': 'deepseek-ai/DeepSeek-R1',
'NUM_SHARD': '8',
'MAX_INPUT_LENGTH': '4096',
'MAX_TOTAL_TOKENS': '8192'
}
)
# Deploy to A100 GPU instances
endpoint = model.deploy(
deployed_model_display_name='deepseek-r1-endpoint',
machine_type='a2-ultragpu-8g', # 8x A100 80GB
accelerator_type='NVIDIA_TESLA_A100',
accelerator_count=8,
min_replica_count=1,
max_replica_count=4
)
# Inference
prediction = endpoint.predict(
instances=[{
"prompt": "Prove that the sum of angles in a triangle is 180 degrees",
"max_tokens": 1500,
"temperature": 0.0
}]
)
GCP costs: a2-ultragpu-8g instances cost $30.00 hourly or $21,600 monthly. Preemptible instances provide 70% discount at $9.00 hourly.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
ml_client = MLClient.from_config()
# Create endpoint
endpoint = ManagedOnlineEndpoint(
name="deepseek-r1-reasoning",
description="DeepSeek R1 for mathematical and coding reasoning",
auth_mode="key"
)
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
# Deploy model
deployment = ManagedOnlineDeployment(
name="deepseek-r1-v1",
endpoint_name="deepseek-r1-reasoning",
model=Model(path="azureml://models/deepseek-r1/versions/1"),
instance_type="Standard_ND96asr_v4", # 8x A100 80GB
instance_count=1,
request_settings={
"request_timeout_ms": 180000, # 3 minutes for complex reasoning
"max_concurrent_requests_per_instance": 2
},
environment_variables={
"MODEL_ID": "deepseek-ai/DeepSeek-R1",
"CUDA_VISIBLE_DEVICES": "0,1,2,3,4,5,6,7"
}
)
ml_client.online_deployments.begin_create_or_update(deployment).result()
Azure costs: Standard_ND96asr_v4 instances cost $27.20 hourly or $19,584 monthly. Spot instances provide 70% savings at $8.16 hourly.
Optimization Strategies
Reduce deployment costs and memory requirements using quantization and batching techniques. INT8 quantization cuts memory from 1.3TB to 650GB, enabling deployment on 4x A100 80GB GPUs. INT4 GPTQ quantization further reduces memory to 350GB, fitting on 4-5x RTX 4090 consumer GPUs.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 8-bit quantization configuration
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_8bit_compute_dtype=torch.float16,
bnb_8bit_use_double_quant=True
)
# Load quantized model
model = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/DeepSeek-R1",
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1")
# Model now fits in 4x RTX 4090 (96GB total VRAM)
Batch processing improves throughput from 30 tokens per second for single requests to 240 tokens per second for batch size 16, providing 8x throughput improvement.
from vllm import LLM, SamplingParams
llm = LLM(
model="deepseek-ai/DeepSeek-R1",
tensor_parallel_size=8,
gpu_memory_utilization=0.95,
max_model_len=8192,
dtype="float16"
)
# Batch inference
prompts = [
"Solve: 2x + 5 = 15",
"Calculate: integral of x^2 from 0 to 3",
"Prove: sqrt(2) is irrational"
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=1000,
stop=["</reasoning>"]
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(output.outputs[0].text)
Application Integration
Build reasoning applications using FastAPI gateways for educational tutoring, code review, and problem-solving services. DeepSeek R1 provides explicit step-by-step solutions with reasoning transparency, making it ideal for educational platforms and development tools.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import asyncio
app = FastAPI()
class TutorRequest(BaseModel):
problem: str
subject: str
difficulty: str = "medium"
@app.post("/tutor/solve")
async def solve_problem(request: TutorRequest):
# Construct reasoning prompt
prompt = f"""As a tutor, solve this {request.subject} problem step by step.
Show your reasoning clearly.
Problem: {request.problem}
Solution:"""
# Generate solution
response = await asyncio.to_thread(
model.generate,
prompt,
max_tokens=2000,
temperature=0.1
)
# Extract steps
solution = response[0]["generated_text"]
steps = extract_reasoning_steps(solution)
return {
"problem": request.problem,
"solution": solution,
"steps": steps,
"subject": request.subject
}
def extract_reasoning_steps(text):
"""Parse step markers from response"""
steps = []
current_step = []
for line in text.split('\n'):
if line.startswith("Step "):
if current_step:
steps.append('\n'.join(current_step))
current_step = [line]
elif current_step:
current_step.append(line)
if current_step:
steps.append('\n'.join(current_step))
return steps
Code review integration:
class CodeReviewRequest(BaseModel):
code: str
language: str
@app.post("/code/review")
async def review_code(request: CodeReviewRequest):
prompt = f"""Review this {request.language} code for:
1. Correctness
2. Efficiency
3. Best practices
4. Potential bugs
Code:
```{request.language}
{request.code}
```
Analysis:"""
response = await asyncio.to_thread(
model.generate,
prompt,
max_tokens=1500,
temperature=0.2
)
return {
"code": request.code,
"review": response[0]["generated_text"],
"language": request.language
}
Performance Monitoring
Track reasoning quality metrics including step count, verification presence, and contradiction detection using Prometheus.
from prometheus_client import Counter, Histogram, Gauge
# Metrics
reasoning_requests = Counter('deepseek_reasoning_requests_total', 'Total reasoning requests', ['subject'])
reasoning_latency = Histogram('deepseek_reasoning_latency_seconds', 'Reasoning request latency')
reasoning_steps = Histogram('deepseek_reasoning_steps_count', 'Number of reasoning steps')
model_tokens_per_second = Gauge('deepseek_tokens_per_second', 'Current throughput')
def monitor_reasoning(prompt, response, subject="math"):
reasoning_requests.labels(subject=subject).inc()
# Count reasoning steps
steps = len([l for l in response.split('\n') if l.startswith('Step')])
reasoning_steps.observe(steps)
# Measure quality indicators
has_verification = "verify" in response.lower()
has_contradiction = "however" in response.lower() or "but" in response.lower()
return {
"steps": steps,
"has_verification": has_verification,
"has_contradiction": has_contradiction
}
Conclusion
DeepSeek R1 delivers exceptional reasoning capabilities for mathematical problem solving, code generation, and educational applications at 50x lower cost than GPT-4 API. Deploy on AWS p4d.24xlarge at $32.77 hourly, GCP a2-ultragpu-8g at $30 hourly, or Azure Standard_ND96asr_v4 at $27.20 hourly for production workloads requiring 8x A100 80GB GPUs. Reduce deployment costs using spot instances providing 70% savings or quantization techniques cutting memory requirements from 1.3TB to 350GB for consumer hardware deployment. Achieve 89.4% accuracy on GSM8K math benchmarks and 78.6% on HumanEval coding tests while providing explicit step-by-step reasoning transparency. Optimize throughput using batch processing reaching 240 tokens per second for batch size 16. Integrate R1 into educational tutoring platforms providing detailed problem-solving explanations, code review tools analyzing correctness and efficiency, and research applications processing scientific reasoning tasks. Monitor reasoning quality tracking step count, verification presence, and contradiction detection. DeepSeek R1 provides optimal solution for reasoning-intensive applications requiring transparent chain-of-thought explanations and cost-effective deployment compared to commercial alternatives.