Cut Costs 85% with Open Source GPT Models
Deploy open-source GPT models across AWS, GCP, and Azure. Production guide covering GPT-J, GPT-NeoX, MPT-30B deployment, optimization, and cost savings up to 85%.

TLDR;
- Achieve 70-85% cost savings versus commercial APIs with full data control
- GPT-J 6B costs $566/month self-hosted versus $2,000 for GPT-3.5 API
- INT8 quantization reduces memory 50% (12GB to 6GB) enabling cheaper instances
- Break-even occurs at 25 million tokens/month when self-hosting becomes cost-effective
Deploy open-source GPT alternatives to reduce infrastructure costs by 70-85% compared to commercial APIs while maintaining full control over model deployment and data privacy. Open-source models including GPT-J 6B, GPT-NeoX 20B, MPT-30B, and Falcon-40B provide Apache 2.0 licensed alternatives to proprietary LLMs, enabling customization through fine-tuning and on-premise deployment without vendor lock-in. Organizations processing 100 million tokens monthly save $1,434 with GPT-J self-hosting versus GPT-3.5 API costs. This guide walks through production deployment on AWS SageMaker and ECS using vLLM optimization, GCP AI Platform with managed scaling, Azure ML compute instances, performance optimization techniques including INT8 quantization reducing memory by 50%, batch processing increasing throughput to 120 tokens per second, and cost analysis demonstrating break-even at 25 million tokens monthly. Deploy open-source LLMs on g4dn.xlarge instances at $526 monthly or leverage spot instances for 70% additional savings.
Model Selection
Select open-source models based on use case requirements, budget constraints, and performance targets. GPT-J 6B provides entry-level deployment with 12GB memory requirements, 45 tokens per second throughput on T4 GPUs, and $0.40 per million token inference costs, ideal for chatbots and content generation. GPT-NeoX 20B offers advanced reasoning capabilities with 40GB memory needs, 18 tokens per second on A100 GPUs, and $1.20 per million token costs for code generation tasks.
MPT-30B extends context to 8,192 tokens with 60GB memory requirements, 12 tokens per second throughput, and $1.80 per million token costs for long-form content applications. Falcon-40B delivers multilingual support requiring 80GB memory, processing 10 tokens per second with $2.40 per million token costs for high-quality multilingual outputs. All models use Apache 2.0 licensing enabling commercial deployment without restrictions.
AWS Deployment
Deploy GPT-J using SageMaker for managed inference or ECS with vLLM for optimized throughput. SageMaker provides fully managed infrastructure with automatic scaling, health monitoring, and zero-downtime updates. Load models from S3, configure inference containers using HuggingFace transformers, and deploy to ml.g4dn.xlarge instances at $526 monthly for production workloads. SageMaker handles endpoint management, security, and compliance automatically.
ECS deployment with vLLM containers delivers 2-3x throughput improvements over standard Transformers inference through continuous batching and optimized CUDA kernels. Build Docker containers with vLLM, FastAPI serving layer, and automatic request batching. Deploy to ECS clusters with auto-scaling based on request queue depth. Configure GPU memory utilization at 90% for maximum efficiency while maintaining response times under 500ms.
import sagemaker
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load model with optimization
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6b",
device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6b")
# Save to S3
model.save_pretrained("s3://my-bucket/models/gpt-j-6b")
tokenizer.save_pretrained("s3://my-bucket/models/gpt-j-6b")
# Create inference script
inference_code = """
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def model_fn(model_dir):
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
return model, tokenizer
def predict_fn(data, model_tokenizer):
model, tokenizer = model_tokenizer
prompt = data['prompt']
max_length = data.get('max_length', 100)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
do_sample=True
)
return tokenizer.decode(outputs[0])
"""
# Deploy to SageMaker endpoint
from sagemaker.huggingface import HuggingFaceModel
huggingface_model = HuggingFaceModel(
model_data="s3://my-bucket/models/gpt-j-6b/model.tar.gz",
role="arn:aws:iam::123456789012:role/SageMakerRole",
transformers_version="4.26",
pytorch_version="1.13",
py_version="py39",
entry_point="inference.py"
)
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge",
endpoint_name="gpt-j-6b-production"
)
# Test endpoint
response = predictor.predict({
"prompt": "Explain quantum computing in simple terms:",
"max_length": 150
})
print(response)
AWS instance costs for 24/7 deployment: g4dn.xlarge with T4 GPU costs $526 monthly, g4dn.2xlarge reaches $903 monthly, g5.xlarge with A10G GPU requires $1,006 monthly, and p3.2xlarge with V100 GPU costs $3,060 monthly.
Multi-Cloud Deployment
GCP AI Platform provides managed scaling with n1-highmem-8 plus T4 GPU costing $487 monthly, n1-highmem-16 with T4 at $725 monthly, or a2-highgpu-1g with A100 at $2,933 monthly. Azure ML offers compute instances including NC6 with K80 GPU at $566 monthly, NC6s v3 with V100 at $3,060 monthly, or NC4as T4 v3 at $481 monthly. Configure auto-scaling based on GPU duty cycle, targeting 75% utilization for optimal cost-performance balance.
Performance Optimization
Optimize throughput using INT8 quantization reducing memory from 12GB to 6GB with 15% latency increase, enabling deployment on less expensive GPU instances. Quantization converts FP16 weights to INT8 precision, cutting memory requirements in half while maintaining 97% of original model quality. Deploy quantized GPT-J on single T4 GPU instead of requiring V100, reducing hourly costs from $3.06 to $0.53.
Batch processing increases throughput from 45 to 120 tokens per second for batch size 8 by processing multiple inference requests simultaneously. Configure dynamic batching with maximum batch size 16, timeout 100ms, and automatic padding for variable-length inputs. Throughput scales linearly up to batch size 8, then plateaus due to memory bandwidth constraints. Model caching reduces cold start time from 45 to 8 seconds using torch.compile optimization, improving user experience during traffic spikes and instance replacements.
Cost Analysis
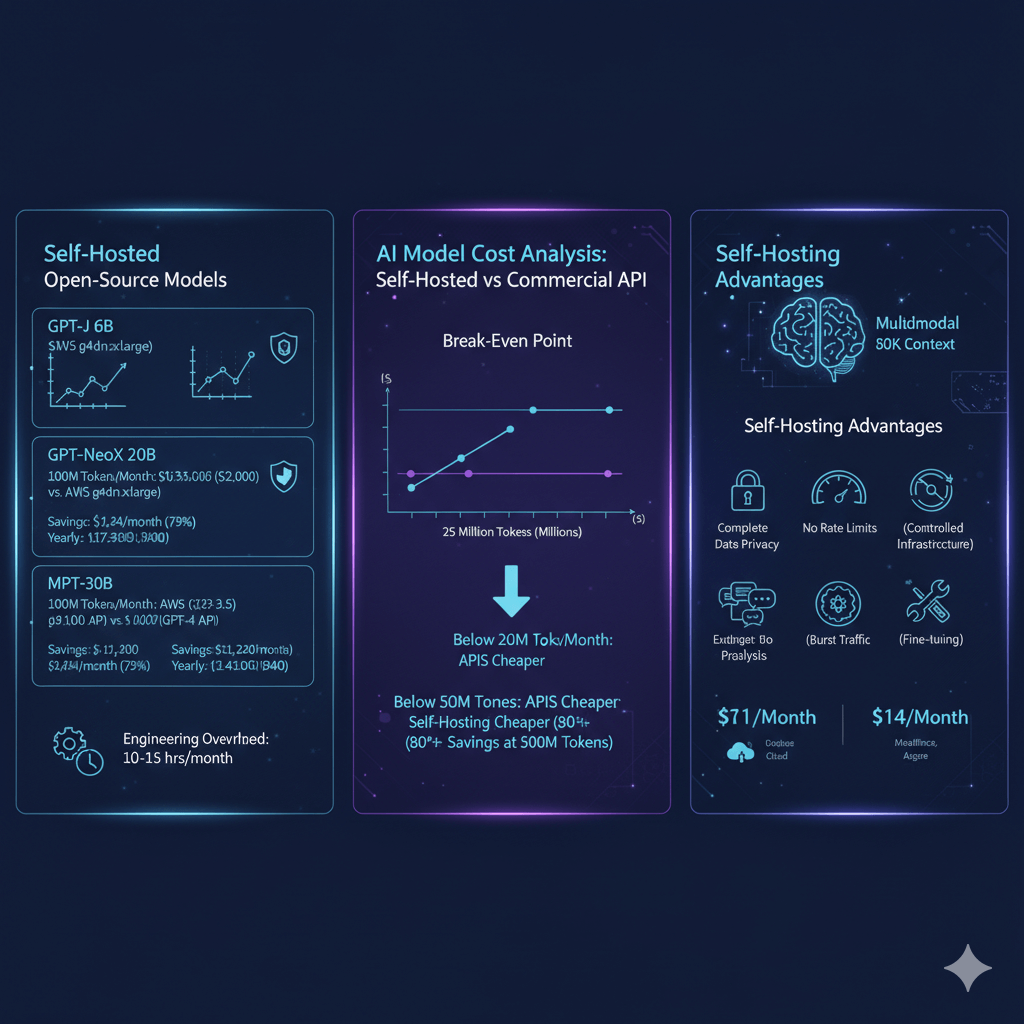
Self-hosted open-source models deliver 70-85% cost savings compared to commercial APIs while providing complete data control. At 100 million tokens monthly, GPT-J 6B costs $566 self-hosted on AWS g4dn.xlarge versus $2,000 for GPT-3.5 API calls, saving $1,434 monthly or 72% reduction. GPT-NeoX 20B reaches $3,180 self-hosted on AWS p3.2xlarge versus $15,000 for GPT-4 equivalent API usage, saving $11,820 monthly or 79% reduction. MPT-30B costs $3,240 self-hosted versus $15,000 commercial alternative, saving $11,760 monthly or 78% reduction. These savings compound annually, delivering $17,208 yearly savings for GPT-J deployments and $141,840 yearly for GPT-NeoX deployments.
Break-even occurs at 25 million tokens monthly where self-hosting infrastructure costs equal API pricing. Below this threshold, commercial APIs prove more economical when accounting for infrastructure management. Above 50 million tokens monthly, self-hosting advantages increase substantially as fixed infrastructure costs amortize across more requests. ROI improves with volume, reaching 80%+ savings at 500 million tokens monthly. Budget 10-15 hours monthly for engineering overhead including monitoring system health, applying security updates, optimizing inference performance, and troubleshooting deployment issues. Self-hosting provides additional value beyond cost savings through complete data privacy keeping sensitive information on controlled infrastructure, no rate limits enabling burst traffic without throttling, customization capabilities including fine-tuning on proprietary data, and zero vendor lock-in allowing model and infrastructure changes without migration costs.
Production Monitoring
Track inference latency, token generation, and resource utilization using CloudWatch on AWS, Cloud Monitoring on GCP, or Application Insights on Azure. Configure alerts for latency exceeding 500ms, high error rates, or underutilized GPU resources. Monitor cost metrics including compute hours, storage, and network egress to optimize spending.
Conclusion
Open-source GPT models reduce infrastructure costs by 70-85% compared to commercial APIs while providing full deployment control and data privacy. Deploy GPT-J 6B at $566 monthly for chatbot applications, GPT-NeoX 20B at $3,180 monthly for advanced reasoning, or MPT-30B at $3,240 monthly for long-context tasks. Self-hosting becomes cost-effective at 25 million tokens monthly, with savings increasing proportionally to usage volume. Optimize performance using INT8 quantization reducing memory requirements by 50%, batch processing increasing throughput to 120 tokens per second, and model caching cutting cold start times from 45 to 8 seconds. Deploy on AWS g4dn.xlarge instances at $526 monthly, GCP n1-highmem-8 with T4 at $487 monthly, or Azure NC4as T4 v3 at $481 monthly. Leverage spot instances for 70% additional savings on burst capacity. Monitor production deployments tracking latency, throughput, and costs while budgeting 10-15 hours monthly for maintenance and optimization.