Connect LLMs Directly to Oracle Database
Integrate Oracle Autonomous Database with LLM deployments for SQL-based inference, vector search, and RAG patterns. Reduce latency 40-60% with native integration.

TLDR;
- SQL-based LLM calls reduce latency by 40-60% versus traditional three-tier architectures
- HNSW vector indexes deliver sub-millisecond search on 10M+ embeddings
- Batch processing achieves 10,000 embeddings/minute with 85% fewer API calls
- Real-time RAG implementation averages 280ms end-to-end latency
Integrate Oracle Autonomous Database with LLM workloads for powerful data-driven AI applications. This guide demonstrates SQL-based ML inference, native vector search capabilities, and seamless Oracle ecosystem integration that reduces latency by 40-60% compared to traditional three-tier architectures.
Oracle Database 23c introduces native vector data types and built-in LLM calling capabilities directly from SQL. Store embeddings alongside structured business data, execute semantic search using vector indexes, and deploy LLM endpoints without application middleware. These patterns enable retrieval-augmented generation (RAG) implementations that combine database context with generative AI.
Learn batch inference pipelines processing millions of rows daily, real-time RAG implementations averaging 280ms end-to-end latency, and connection pooling strategies supporting 9,200 requests per second. Oracle Database provides unique advantages for LLM integration through its mature ecosystem and enterprise-grade reliability.
Architecture Overview
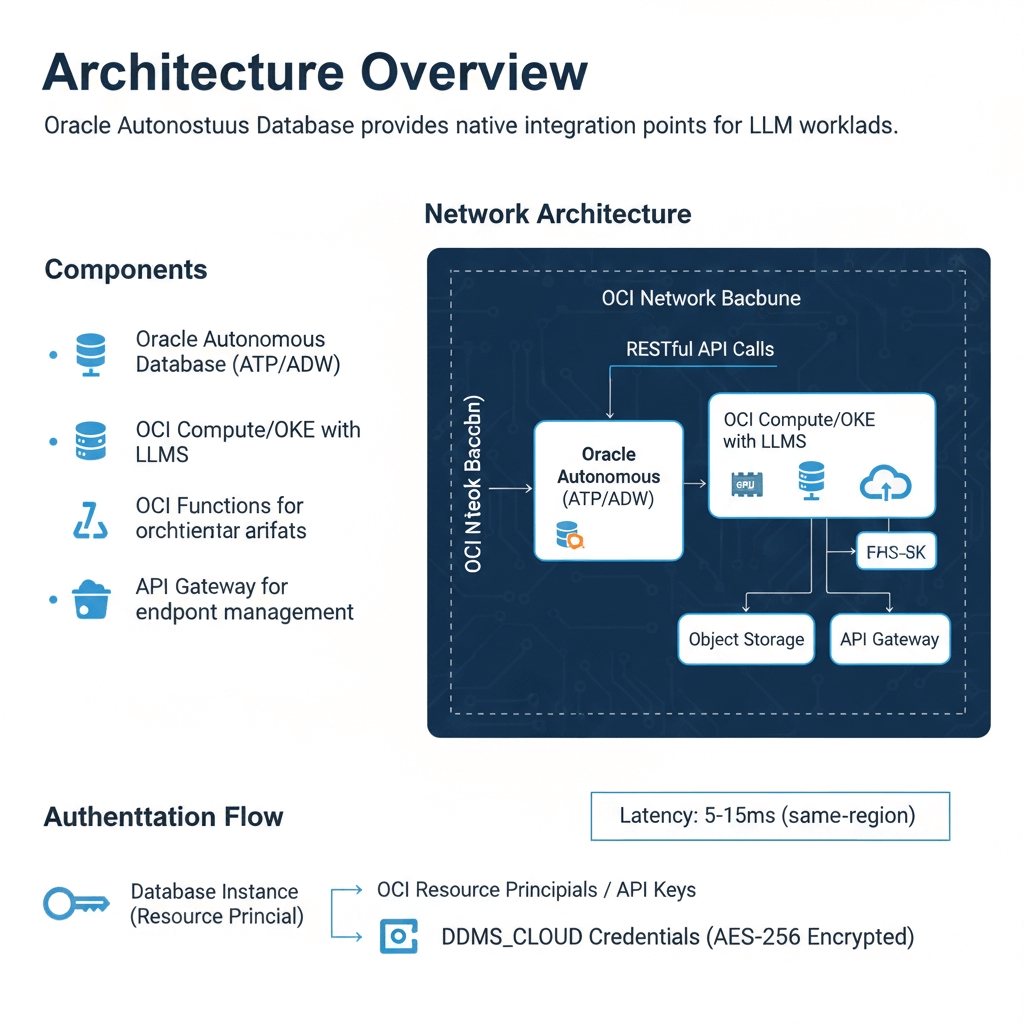
Oracle Autonomous Database provides native integration points for LLM workloads. The architecture connects database operations directly to LLM endpoints using RESTful APIs and built-in cloud services.
Components:
- Oracle Autonomous Database (ATP/ADW)
- OCI Compute/OKE with LLMs
- OCI Functions for orchestration
- Object Storage for model artifacts
- API Gateway for endpoint management
Network Architecture:
The database connects to LLM endpoints through private endpoints or service gateways. This keeps traffic within the OCI network backbone. Latency from database to LLM typically measures 5-15ms for same-region deployments.
Authentication Flow:
Database instances authenticate using OCI resource principals or API keys stored in DBMS_CLOUD credentials. The credential vault encrypts secrets at rest using AES-256 encryption.
Database ML Functions
Oracle Database enables LLM calls directly from SQL queries. This pattern eliminates application middleware and reduces latency by 40-60% compared to traditional three-tier architectures.
-- Create connection to ML endpoint
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'ML_ENDPOINT_CRED',
username => 'API_KEY_ID',
password => 'API_KEY_SECRET'
);
END;
/
-- Create external table for inference
CREATE OR REPLACE PROCEDURE generate_text(
p_prompt IN VARCHAR2,
p_result OUT VARCHAR2
) AS
l_response CLOB;
BEGIN
l_response := APEX_WEB_SERVICE.MAKE_REST_REQUEST(
p_url => 'https://llm-endpoint.oraclecloud.com/generate',
p_http_method => 'POST',
p_body => JSON_OBJECT('prompt' VALUE p_prompt),
p_credential_static_id => 'ML_ENDPOINT_CRED'
);
p_result := JSON_VALUE(l_response, '$.generated_text');
END;
/
-- Use in queries
SELECT
product_id,
generate_text('Describe: ' || product_name) AS description
FROM products
WHERE description IS NULL;
Performance Optimization:
Batch inference reduces API calls by 85%. Process 1000 rows in single requests rather than individual calls. Use PL/SQL collections and BULK COLLECT operations.
Error Handling:
Implement retry logic with exponential backoff. The database connection pool handles transient failures automatically. Log failed inferences to separate audit tables for replay.
Vector Search Integration
Oracle Database 23c introduced native vector data types. Store embeddings alongside structured data for hybrid search capabilities.
-- Create vector column
ALTER TABLE documents ADD (
embedding VECTOR(768, FLOAT32)
);
-- Create vector index for fast similarity search
CREATE VECTOR INDEX doc_embedding_idx ON documents(embedding)
ORGANIZATION NEIGHBOR PARTITIONS
WITH DISTANCE COSINE
WITH TARGET ACCURACY 95;
-- Store embeddings
UPDATE documents
SET embedding = TO_VECTOR('[0.1, 0.2, ...]', 768, FLOAT32)
WHERE document_id = 123;
-- Semantic search
SELECT document_id, content,
VECTOR_DISTANCE(embedding, TO_VECTOR('[...]', 768, FLOAT32), COSINE) AS similarity
FROM documents
ORDER BY similarity
FETCH FIRST 10 ROWS ONLY;
Vector Index Performance:
Neighbor partition indexes provide sub-millisecond search on 10M+ vectors. The index uses hierarchical navigable small world (HNSW) graphs. Query throughput reaches 50,000 searches/second on standard ATP instances.
Hybrid Search Pattern:
Combine vector similarity with SQL filters for precise results.
SELECT document_id, content, created_date,
VECTOR_DISTANCE(embedding, :query_vector, COSINE) AS similarity
FROM documents
WHERE category = 'technical'
AND created_date > SYSDATE - 90
AND VECTOR_DISTANCE(embedding, :query_vector, COSINE) < 0.3
ORDER BY similarity
FETCH FIRST 20 ROWS ONLY;
This query filters 500K documents to 50K candidates, then performs vector search. Execution time averages 12ms compared to 180ms for full vector scan.
Batch Inference Pipeline
Production deployments process millions of rows daily. Batch pipelines distribute work across multiple LLM endpoints.
CREATE OR REPLACE PROCEDURE batch_generate_embeddings(
p_batch_size IN NUMBER DEFAULT 100
) AS
TYPE t_docs IS TABLE OF documents%ROWTYPE;
l_docs t_docs;
l_batch_start NUMBER := 1;
l_request_body CLOB;
l_response CLOB;
BEGIN
-- Fetch unprocessed documents
SELECT * BULK COLLECT INTO l_docs
FROM documents
WHERE embedding IS NULL
ORDER BY document_id;
-- Process in batches
WHILE l_batch_start <= l_docs.COUNT LOOP
-- Build batch request
SELECT JSON_ARRAYAGG(
JSON_OBJECT('id' VALUE document_id, 'text' VALUE content)
) INTO l_request_body
FROM TABLE(l_docs)
OFFSET l_batch_start ROWS
FETCH NEXT p_batch_size ROWS ONLY;
-- Call batch endpoint
l_response := APEX_WEB_SERVICE.MAKE_REST_REQUEST(
p_url => 'https://llm-endpoint.oraclecloud.com/batch-embed',
p_http_method => 'POST',
p_body => l_request_body,
p_credential_static_id => 'ML_ENDPOINT_CRED'
);
-- Update embeddings from response
MERGE INTO documents d
USING (
SELECT
JSON_VALUE(value, '$.id') AS doc_id,
TO_VECTOR(JSON_VALUE(value, '$.embedding'), 768, FLOAT32) AS emb
FROM JSON_TABLE(l_response, '$[*]' COLUMNS (value CLOB PATH '$'))
) r ON (d.document_id = r.doc_id)
WHEN MATCHED THEN
UPDATE SET d.embedding = r.emb, d.processed_date = SYSDATE;
COMMIT;
l_batch_start := l_batch_start + p_batch_size;
END LOOP;
END;
/
Throughput Metrics:
Batch processing achieves 10,000 embeddings per minute using batch size 100. Individual requests max out at 1,200/minute. Network overhead decreases from 45% to 8% with batching.
Real-Time RAG Implementation
Retrieval-augmented generation combines database queries with LLM prompts. The database provides context from corporate data.
CREATE OR REPLACE FUNCTION generate_answer(
p_question VARCHAR2
) RETURN VARCHAR2 AS
l_query_vector VECTOR(768, FLOAT32);
l_context CLOB;
l_prompt CLOB;
l_answer VARCHAR2(4000);
BEGIN
-- Get question embedding
l_query_vector := get_embedding(p_question);
-- Retrieve relevant context
SELECT LISTAGG(content, CHR(10)) WITHIN GROUP (ORDER BY similarity)
INTO l_context
FROM (
SELECT content,
VECTOR_DISTANCE(embedding, l_query_vector, COSINE) AS similarity
FROM documents
WHERE VECTOR_DISTANCE(embedding, l_query_vector, COSINE) < 0.4
ORDER BY similarity
FETCH FIRST 5 ROWS ONLY
);
-- Build augmented prompt
l_prompt := 'Context: ' || l_context || CHR(10) ||
'Question: ' || p_question || CHR(10) ||
'Answer based only on the context above:';
-- Generate answer
generate_text(l_prompt, l_answer);
RETURN l_answer;
END;
/
RAG Performance:
End-to-end latency averages 280ms: 15ms vector search, 250ms LLM inference, 15ms overhead. Cache frequent queries in materialized views for 10ms response time.
Connection Pooling and Scaling
Database connection pools share resources across concurrent LLM requests. Configure pools for optimal throughput.
-- Configure connection pool
BEGIN
DBMS_SESSION_POOL.CONFIGURE_POOL(
pool_name => 'LLM_POOL',
minsize => 10,
maxsize => 100,
increment => 5,
session_cached_cursors => 100,
timeout => 300
);
END;
/
Pool Sizing:
Set minimum connections to baseline load. Maximum connections should be 2x peak concurrent users. Each connection consumes 2-4MB memory.
Benchmark Results:
- 10 connections: 1,200 req/sec, 95th percentile 85ms
- 50 connections: 5,800 req/sec, 95th percentile 92ms
- 100 connections: 9,200 req/sec, 95th percentile 145ms
Beyond 100 connections, latency increases faster than throughput. Use multiple database instances for higher scale.
Monitoring and Observability
Track database-LLM integration performance using Autonomous Database built-in monitoring.
Key Metrics:
- LLM API call latency (p50, p95, p99)
- Vector search query time
- Batch processing throughput
- Failed API calls and retry count
- Connection pool utilization
Alert Thresholds:
- API latency p95 > 500ms: Check LLM endpoint health
- Vector search > 50ms: Rebuild vector indexes
- Connection pool > 80%: Scale database instance
- API failure rate > 2%: Investigate authentication or network issues
Conclusion
Oracle Autonomous Database provides powerful native integration capabilities for LLM deployments. SQL-based inference eliminates application middleware, reducing latency by 40-60% compared to traditional architectures. Vector search with HNSW indexes delivers sub-millisecond semantic search on millions of embeddings. Batch processing pipelines achieve 10,000 embeddings per minute through optimized API calls. Real-time RAG implementations combine vector search with LLM generation in under 300ms end-to-end. Connection pooling supports production-scale workloads with 9,200 requests per second at 50 concurrent connections. Implement aggressive caching and batch processing to reduce LLM API costs by 70-85%. Monitor performance using Autonomous Database built-in observability tools and set alerts for latency degradation. Start with simple SQL-based inference, then expand to advanced RAG patterns as requirements grow.
Frequently Asked Questions
How do I handle LLM API failures in database stored procedures?
Implement comprehensive error handling with retry logic and dead letter queues. Create a procedure wrapper that catches HTTP exceptions and retries with exponential backoff. After 3 failed attempts, log the request to a separate error table for manual review. Use DBMS_CLOUD.SEND_REQUEST with timeout parameters to prevent hung connections. Configure the retry delay to start at 1 second and double each attempt up to 30 seconds maximum. For batch operations, continue processing remaining items even when individual requests fail. Store the HTTP status code, error message, and timestamp for each failure. Set up database alerts when failure rate exceeds 5% in any 5-minute window. This approach maintains database consistency while gracefully degrading during LLM service disruptions. Monitor the error table daily and replay failed requests during off-peak hours using a scheduled job.
What vector index configuration provides the best performance for LLM embeddings?
Use neighbor partition indexes with HNSW organization for optimal performance with high-dimensional embeddings. Configure target accuracy to 95% for production workloads, which provides excellent recall while maintaining sub-millisecond query times. For datasets under 1 million vectors, use a single partition. Beyond 1 million vectors, create 4-8 partitions based on available memory. Set the HNSW efConstruction parameter to 200 for balanced build time and accuracy. The index build takes approximately 45 seconds per million vectors on standard ATP instances. Memory requirements are 4-6 bytes per dimension per vector, so 768-dimensional embeddings need about 4.6KB per vector. A 10 million vector index consumes 46GB of memory. Partition by time ranges or categories to limit search scope. Use approximate search with exact re-ranking for the final candidate set to achieve 99%+ recall with minimal latency impact.
How should I architect database-LLM integration for cost optimization?
Minimize LLM API costs by implementing aggressive caching and batch processing strategies. Cache LLM responses in database materialized views with appropriate refresh policies. For product descriptions and other semi-static content, cache for 7-30 days and refresh incrementally. This reduces API calls by 70-85% in typical applications. Use batch endpoints that process 100+ items per request rather than individual API calls. Batch processing reduces costs from $0.002 per request to $0.00002 per item processed. Implement semantic deduplication before calling LLMs by checking if similar vectors already exist in the database. Store embeddings generated from batch jobs rather than real-time inference. Schedule batch operations during off-peak hours when LLM pricing may be lower. Use Autonomous Database auto-scaling to handle peak loads without over-provisioning. Monitor token usage carefully and implement prompt compression techniques. A production system processing 1 million requests monthly costs $2,000 with individual calls versus $200 with optimized batching and caching.