Deploy ML Models 50% Cheaper with Auto-Scaling
Cut ML inference costs by 50% through model optimization, auto-scaling endpoints, multi-model deployment, and batch processing strategies for efficient model deployment and serving.

Introduction
Machine learning inference costs represent up to 90% of total ML expenses in deployed systems, far exceeding one-time training costs. A single idle SageMaker endpoint can drain over $1,000 monthly, while inefficient deployment strategies multiply costs exponentially as models scale. For ML engineers and MLOps teams, optimizing inference endpoints has become as critical as model accuracy.
Strategic model optimization combined with intelligent infrastructure choices enables dramatic cost reduction without sacrificing performance. From quantization techniques that reduce model size by 75% to multi-model endpoints that cut deployment costs by 80%, modern MLOps practices offer unprecedented opportunities for cost savings. This guide explores proven strategies for optimizing inference endpoints across model-level optimizations like quantization and pruning, infrastructure strategies including auto-scaling and batch processing, and advanced techniques for maximizing resource utilization.
Understanding Inference Cost Drivers
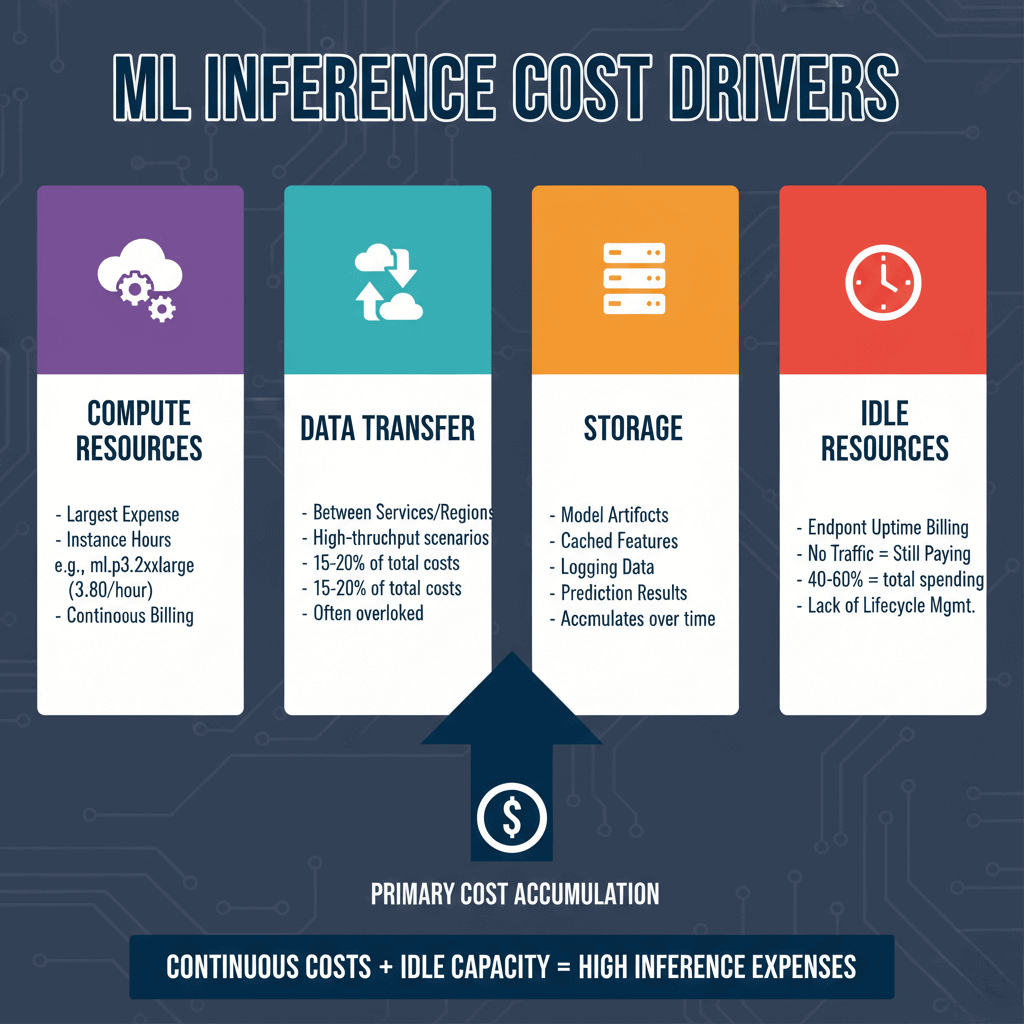
ML inference costs accumulate continuously as long as models serve predictions. The primary drivers include compute resources for instance hours, data transfer fees between services and regions, storage for model artifacts and logs, and idle resource consumption when endpoints sit unused.
Compute resources represent the largest expense. A single ml.p3.2xlarge instance on AWS costs approximately $3.80 per hour, translating to $2,736 monthly if running continuously. Data transfer costs surprise many teams, potentially representing 15-20% of total inference costs for high-throughput scenarios. Storage expenses accumulate from model artifacts, cached features, logging data, and prediction results.
The most insidious cost driver is idle resource consumption. Traditional ML endpoints bill for uptime regardless of traffic. An endpoint provisioned for peak traffic that sits idle during off-hours continues generating charges. Organizations without strict endpoint lifecycle management often find idle capacity representing 40-60% of total inference spending.
To also understand how to deploy LLMs serverlessly with scale‑to‑zero autoscaling (eliminating idle costs), see the guide on Auto‑Scale GPU Workloads on GKE Clusters.
Model Optimization Techniques
Quantization reduces model precision from 32-bit floating point to 8-bit integers, cutting model size by 75% while maintaining 95%+ accuracy for most applications. Smaller models require less memory, enabling deployment on cheaper instances and faster inference with lower latency. TensorFlow Lite, PyTorch quantization, and ONNX Runtime all provide quantization support with minimal code changes.
Pruning removes redundant neural network weights, reducing model size by 30-50% depending on architecture. Modern pruning techniques identify and eliminate connections with minimal impact on accuracy. Combined with quantization, pruning can reduce model size by 80-90%, dramatically lowering compute requirements.
Knowledge distillation trains smaller "student" models to mimic larger "teacher" models, achieving 90-95% of original accuracy at 10-20% of model size. This technique proves particularly effective for deploying large language models or transformer architectures where deployment costs scale with model size.
Infrastructure Optimization Strategies
Right-sizing inference endpoints prevents over-provisioning that wastes resources. Profile actual inference workload requirements including memory consumption, CPU utilization, and latency requirements. Many teams over-provision GPU instances when CPU instances suffice for inference at one-tenth the cost. Load testing reveals optimal instance types balancing cost and performance.
Multi-model endpoints allow deploying dozens or hundreds of models on a single endpoint, with SageMaker dynamically loading models based on incoming requests. This approach can reduce costs by 80% compared to dedicated endpoints per model. Organizations deploying personalized models per customer or A/B testing multiple variants benefit dramatically from multi-model architecture.
Serverless endpoints like SageMaker Serverless Inference eliminate idle capacity costs by scaling to zero when unused. You pay only for compute time during actual inference requests. For sporadic workloads with unpredictable traffic patterns, serverless inference can reduce costs by 60-90% compared to always-on dedicated endpoints. However, cold starts introduce latency, making serverless inappropriate for latency-sensitive applications requiring sub-100ms response times.
Auto-Scaling Configuration
Auto-scaling dynamically adjusts instance counts based on traffic, preventing both over-provisioning waste and under-provisioning performance degradation. Configure minimum instance counts to handle baseline traffic and maximum counts to cap costs during unexpected spikes.
Target tracking scaling policies maintain desired utilization levels, typically 70-75% for sustained performance. Scaling policies should trigger before utilization reaches 100%, preventing request queuing and latency spikes. Step scaling provides more granular control, adding instances incrementally as traffic increases.
Cooldown periods prevent thrashing where instances rapidly scale up and down. Set cooldown to 2-5 minutes allowing stabilization between scaling events. Monitor CloudWatch metrics including invocation count, model latency, CPU utilization, and memory consumption to tune scaling policies based on actual workload characteristics.
Batch Processing for Non-Real-Time Workloads
Batch transform jobs process large datasets offline at a fraction of real-time endpoint costs. For workloads without sub-second latency requirements, batch processing eliminates idle capacity costs entirely. SageMaker Batch Transform processes predictions in batches, automatically provisioning and terminating resources based on job requirements.
Batch processing proves ideal for periodic model scoring, overnight report generation, data preprocessing pipelines, and asynchronous prediction requests. Organizations processing millions of predictions daily can reduce costs by 70-85% by migrating appropriate workloads from real-time endpoints to batch processing.
Conclusion
ML inference cost optimization requires systematic attention to both model-level and infrastructure-level strategies. Quantization and pruning reduce model size by 75-90%, enabling deployment on cheaper instances. Multi-model endpoints consolidate dozens of models onto single infrastructure, cutting costs by 80%. Auto-scaling eliminates idle capacity waste while maintaining performance during traffic spikes. For appropriate workloads, batch processing and serverless endpoints reduce costs by 70-90% compared to always-on dedicated endpoints. Implement comprehensive monitoring to track cost per prediction, identify optimization opportunities, and maintain balance between cost efficiency and performance requirements.
Frequently Asked Questions
What is the difference between serverless and dedicated ML endpoints?
Dedicated endpoints run continuously on provisioned instances, billing for uptime regardless of traffic. They provide consistent low latency but generate costs even when idle. Serverless endpoints scale to zero when unused, billing only for actual inference requests. This eliminates idle costs but introduces cold start latency. Choose dedicated endpoints for consistent high-traffic applications requiring sub-100ms latency, serverless for sporadic workloads where cold starts are acceptable.
How much can quantization reduce inference costs?
Quantization typically reduces model size by 75% (32-bit to 8-bit) while maintaining 95%+ accuracy. This translates to 50-75% cost reduction through smaller instance requirements, faster inference enabling higher throughput per instance, and reduced data transfer costs for model loading. Combined with pruning, total cost reduction can reach 80-90%.
When should I use batch processing instead of real-time endpoints?
Use batch processing for workloads tolerating latency over 30 seconds including periodic model scoring, overnight analytics, data preprocessing, and asynchronous predictions. Batch processing eliminates idle capacity costs and optimizes resource utilization, reducing costs by 70-85%. Maintain real-time endpoints only for user-facing applications requiring sub-second response times.