Reduce AWS Machine Learning Costs by 70%
Optimize AWS AI/ML costs with proven strategies for training and inference. Reduce machine learning expenses by 40-70% while maintaining performance and scalability.

TL;DR
- 30-40% of ML spend is wasted on idle endpoints, overprovisioned instances, and orphaned storage.
- Training: Use Spot Instances (60-90% savings) with checkpointing. Profile GPU utilization – below 60% means you're overpaying.
- Inference: Right-size instances, use Serverless for sporadic traffic (90% savings), or multi-model endpoints (97% savings).
- Inferentia instances (Inf1/Inf2) deliver 70% lower cost per inference than GPUs.
- Savings Plans provide up to 72% discounts for consistent usage.
- Result: Most organizations cut ML costs 40-70% in 30-60 days.
AWS machine learning costs can spiral quickly without strategic management. Organizations waste 30-40% of their ML spending on overprovisioned instances, idle endpoints, and inefficient workflows. Unlike traditional applications, machine learning workloads present unique cost challenges with compute-intensive training jobs and unpredictable inference demand.
This guide reveals proven strategies to reduce AWS machine learning costs by 40-70% through right-sizing instances, leveraging Spot pricing, optimizing storage, and implementing FinOps practices. Whether you're running large-scale model training or deploying production inference endpoints, these strategies will transform your ML economics.
Understanding AWS ML Cost Drivers
Training costs represent the most significant expense in AI workloads. GPU-accelerated instances like P4, P5, and Trainium Trn1n require substantial investment.
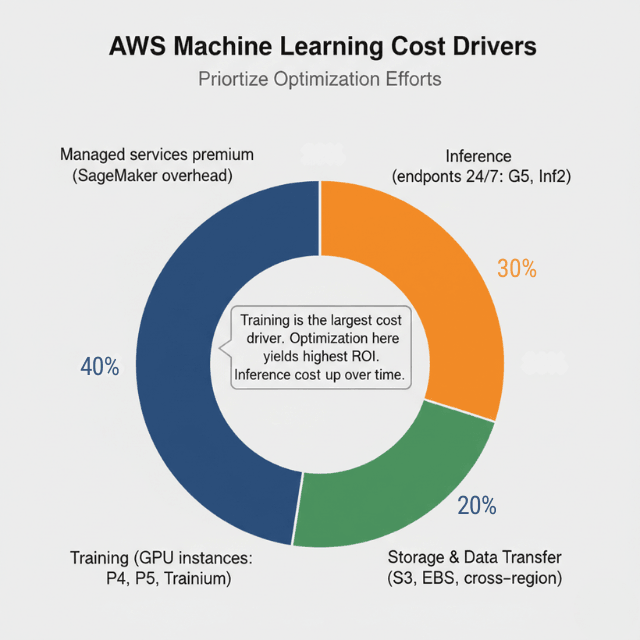
A single large language model training run can consume thousands of GPU-hours, translating to tens of thousands of dollars. The iterative nature of ML development compounds this expense as data scientists run hundreds of experiments.
| Cost Category | Description | Example |
|---|---|---|
| Training costs | GPU instances (P4, P5, Trainium), iterative experiments | Large language model: thousands of GPU-hours, tens of thousands of dollars |
| Inference costs | Production endpoints running 24/7 | ml.m5.xlarge endpoint: $0.269/hour → ~$193/month |
| Data storage & transfer | S3 storage, retrieval fees, cross-region transfer | 100TB at $0.023/GB = $2,300/month |
| Managed services premium | SageMaker convenience fee | 20-30% above underlying EC2 costs |
Optimizing Training Costs
Right-sizing compute resources forms the foundation of training optimization. AWS offers GPU instances (P4, P5, G5), Trainium chips (Trn1), and general-purpose instances. The price-performance ratio varies dramatically. Trn1 instances offer up to 50% better price-performance than comparable GPU instances for certain workloads.
Profiling training workloads reveals whether you're compute-bound, memory-bound, or I/O-bound. Many models don't require the most expensive instances. Use SageMaker Profiler to identify bottlenecks. If GPU utilization hovers below 60%, you're overpaying for unused capacity.
| Strategy | Implementation | Potential Savings |
|---|---|---|
| Right-sizing compute | Profile workloads (SageMaker Profiler); GPU utilization below 60% = overpaying | Significant |
| Distributed training | Use 4 instances; if runtime cuts 75%, same results at lower total cost | Reduces time-to-completion |
| Spot Instances | SageMaker Managed Spot Training with checkpointing | 60-90% vs. on-demand |
| Diversify instance types | Use EC2 Spot Instance Advisor; low interruption rates | Minimizes interruption impact |
| Checkpointing | Every 15-30 minutes | Minimizes progress loss |
| Trainium instances | Trn1 for certain workloads | Up to 50% better price-performance than GPUs |
Reducing Inference Costs
Inference workloads have different requirements than training, enabling use of specialized, cost-optimized instances. AWS Inferentia-based Inf1 and Inf2 instances deliver up to 70% lower cost per inference compared to GPU instances. Use SageMaker Neo to compile models for Inferentia.
For GPU-based inference, G5 instances provide better price-performance than training-optimized P4/P5 instances. Profiling reveals that inference typically requires lower compute than training. An ml.g4dn.xlarge at $0.736/hour often suffices where teams deployed ml.p3.2xlarge at $3.06/hour a 75% cost reduction.
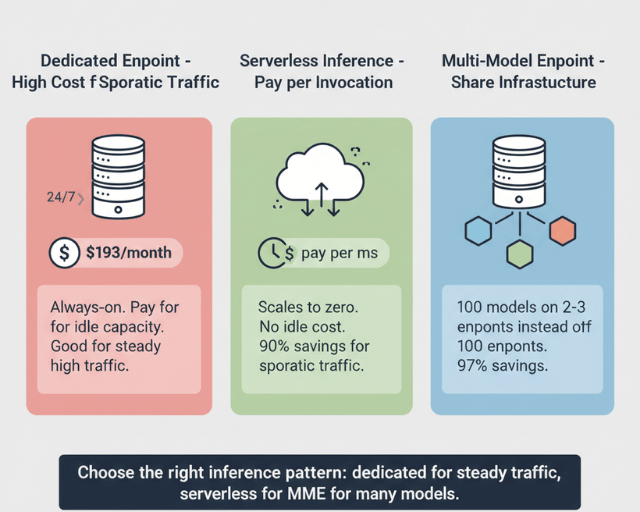
SageMaker Serverless Inference transforms cost structure for sporadic traffic. You're charged per millisecond of compute time used instead of paying for always-on capacity. For applications with irregular traffic, serverless inference can reduce costs by 90% compared to dedicated endpoints.
Auto-scaling prevents paying for idle capacity during traffic troughs. Configure target tracking policies based on invocations per instance or model latency. Set aggressive scale-in cooldown periods to quickly reduce capacity when traffic drops.
Multi-model endpoints (MMEs) serve multiple models on shared infrastructure. Instead of separate endpoints for each model, MMEs load models dynamically from S3 as needed. For 100 models needing ml.m5.large endpoints at $98.67/month each, traditional deployment costs $9,867 monthly. With MMEs sharing 2-3 endpoints, costs drop to $200-300 monthly a 97% savings.
Storage and Data Optimization
Storage and data optimization strategies:
| Strategy | Implementation | Savings |
|---|---|---|
| S3 Intelligent-Tiering | Automatically moves objects between access tiers | Optimized for changing access patterns |
| S3 Glacier Instant Retrieval | For archival data with millisecond retrieval | 68% savings ($0.004/GB/month) |
| Lifecycle policies | Automatically transition data through tiers | Reduces long-term storage costs |
| Columnar formats | Parquet or ORC instead of CSV/JSON | 50-80% storage reduction + faster loading |
| Image optimization | WebP or JPEG with appropriate quality | Significant storage reduction |
| EBS cleanup automation | Delete volumes when training jobs finish | Eliminates orphaned volume charges |
| Same region placement | Training, S3, data sources in same region | Eliminates cross-region transfer charges |
68% storage savings with Glacier. 80% with Parquet. We implement both.
Data storage and transfer costs accumulate silently. Most organizations discover hundreds of terabytes in unnecessary storage during audits.
We help you:
- Implement S3 lifecycle policies – Auto-transition data through storage tiers
- Convert to Parquet/ORC – Reduce storage 50-80%, accelerate data loading
- Automate orphaned volume cleanup – EBS volumes from completed training jobs
- Minimize cross-region transfer – Keep training data and compute in same region
Model Optimization Techniques
Model size directly correlates with inference costs through memory requirements and compute intensity. Quantization reduces model precision from FP32 to FP16 or INT8, cutting model size by 50-75% with minimal accuracy loss. SageMaker Neo automates quantization and optimization.
Model pruning removes redundant parameters, creating smaller models that maintain accuracy while reducing computational requirements. Distillation transfers knowledge from large teacher models to smaller student models, achieving similar performance with 5-10x fewer parameters.
Implement prediction caching for use cases with repeat queries. Using ElastiCache to store recent predictions eliminates redundant inference calls, reducing costs by 30-70% for applications with high query repetition.
Leveraging AWS Pricing Models
AWS Savings Plans offer significant discounts (up to 72% for 3-year commitments) in exchange for consistent usage. You can see AWS pricing models comparison below:
| Pricing Model | Discount (3-year) | Flexibility | Best For |
|---|---|---|---|
| Compute Savings Plans | Up to 72% | High (across families, sizes, regions, OS) | Variable workloads, conservative 40-60% of average usage |
| SageMaker Savings Plans | Up to 72% | SageMaker-specific | SageMaker instance usage |
| Reserved Instances (Standard) | Up to 75% | Low | Highly stable, long-running workloads (production endpoints) |
Monitoring and Governance
AWS Cost Explorer provides detailed visibility into spending patterns. Implement tagging strategies across ML resources with project, team, environment, and model tags. Cost allocation tags enable filtering and grouping expenses.
AWS Budgets enables proactive cost management through customizable alerts. Create budgets for overall ML spending and configure alerts at 50%, 75%, and 100% thresholds. Budget actions can automatically stop non-critical endpoints when spending thresholds are exceeded.
AWS Cost Anomaly Detection uses machine learning to identify unusual spending patterns. It learns normal spending behaviors and alerts you to anomalies like sudden cost increases.
Regular resource audits identify waste. AWS Trusted Advisor automatically scans for idle resources, including underutilized SageMaker endpoints and unattached EBS volumes. Many organizations discover 15-30% cost reduction potential from eliminating forgotten resources.
Implementing FinOps for ML
FinOps brings engineering, finance, and operations teams together for data-driven spending decisions.
- Establish cost ownership - Assign monthly budgets to engineering teams. When data scientists see costs of their experiments, behavior changes naturally.
- Track balance KPIs - Cost per training job, cost per 1000 inferences, accuracy per dollar spent. A model with 98% accuracy at $10,000/month may be less valuable than a 96% accurate model at $2,000/month.
- Cost estimation workflows - Before launching large-scale training jobs, require cost estimates for jobs exceeding thresholds. Use AWS Pricing Calculator or historical data.
- Staged model development - Start with small dataset samples and cheap instances for rapid prototyping. Only scale to full datasets and expensive instances after validating approaches.
Advanced Optimization Strategies
Lambda offers compelling alternatives for lightweight inference workloads with pay-per-request pricing. For models under deployment package size limits, Lambda costs pennies per million requests. A function with 1GB memory executing for 200ms costs $0.0000033 per invocation.
Edge inference using AWS IoT Greengrass or SageMaker Edge deploys models to edge devices, reducing cloud inference costs to zero for processed requests. Hybrid architectures use local inference for simple predictions and cloud inference for complex scenarios.
AutoML and model compression through SageMaker Autopilot discover efficient models that balance accuracy and computational efficiency. Autopilot explores architectures, finding solutions that require 30-60% less compute than manually designed alternatives.
| Strategy | Implementation | Benefit |
|---|---|---|
| Lambda inference | For models under deployment package size limits | Pay-per-request; pennies per million requests |
| Edge inference | AWS IoT Greengrass or SageMaker Edge | Reduce cloud inference costs to zero for processed requests |
| Hybrid architectures | Local for simple predictions, cloud for complex | Balance cost and capability |
| AutoML (SageMaker Autopilot) | Discover efficient architectures | 30-60% less compute than manual design |
Conclusion
Optimizing AWS machine learning costs requires systematic attention to training optimization, inference right-sizing, storage management, and FinOps practices. Organizations typically achieve 40-70% cost reductions through the strategies outlined in this guide.
Start with high-impact changes like using Spot Instances for training, right-sizing inference endpoints, and implementing S3 lifecycle policies. These quick wins demonstrate value and build momentum for advanced optimizations like multi-model endpoints and serverless inference.
Remember that cost optimization is not about minimizing spending at all costs it's about maximizing business value per dollar invested. By implementing monitoring, governance, and continuous improvement practices, you'll build ML systems that scale economically with your business, transforming cost management from a reactive fire drill into a proactive competitive advantage.
Frequently Asked Questions
How much can I realistically save on AWS machine learning costs?
Organizations typically achieve 40-70% cost reductions through systematic optimization. Quick wins like eliminating idle endpoints and using Spot Instances for training often yield 30-40% savings within the first month.
Comprehensive optimization including inference optimization, storage lifecycle management, and pricing model selection can reach 70-80% total cost reduction. The key is addressing multiple cost drivers training, inference, storage, and data transfer optimization compound for maximum impact.
Should I use SageMaker or self-managed EC2 instances for cost efficiency?
| Scale | Recommendation | Rationale |
|---|---|---|
| Small-to-medium (<$10,000-20,000/month) | SageMaker | Productivity benefits justify 20-30% premium; integrated tooling saves engineering time |
| Large (>$50,000/month) | Self-managed EC2/EKS | Significant savings justify operational complexity |
| Consideration | Factor in engineering time for custom ML infrastructure |
What are the best AWS instances for cost-effective machine learning inference?
For deep learning inference, AWS Inferentia-based Inf1 and Inf2 instances offer the best price-performance, delivering up to 70% lower cost per inference than GPU alternatives. Use SageMaker Neo to compile models for Inferentia.
For GPU-based inference, G5 instances balance cost and performance. For simpler models, CPU-based instances like M6g (Graviton) or M5 often suffice at a fraction of GPU costs. The best choice depends on model architecture, latency requirements, and throughput needs.
How do Spot Instances work for ML training and what are the risks?
Spot instance risk management
- Trade-off: 60-90% discounts with 2-minute interruption warning
- Mitigation: SageMaker Managed Spot Training automates checkpointing
- Interrupted jobs: Resume from last checkpoint, don't restart
- Main risk: Job delays when Spot capacity is limited (most complete successfully)
- Best practice: Combine Spot with on-demand fallback for time-sensitive training
What cost optimization should I prioritize first for AWS machine learning?
| Priority | Optimization Area | Timeline | Expected Savings |
|---|---|---|---|
| First | Eliminate waste (idle endpoints, orphaned volumes, unnecessary S3) | First days | 15-30% |
| Second | Spot Instances for training | First week | 40-60% of training compute (often 40-60% of total ML spend) |
| Third | Inference optimization (right-sizing, auto-scaling, serverless) | First 30-60 days | 30-90% depending on workload |
| Comprehensive | All strategies combined | 30-90 days | 40-70% total cost reduction |
| Maximum | Including advanced optimizations | 90+ days | 70-80% total cost reduction |
Summarize this post with:
