Multi-Region Data Management
Master multi-region data management for global SaaS. Learn PostgreSQL logical replication, MongoDB zone sharding, Redis active-active, and failover strategies for compliance and low latency.

TL;DR
- Three purposes for multi-region: Disaster recovery (region outages happen), performance (200ms → 20ms latency), and compliance (GDPR data residency).
- Start active-passive, graduate to active-active: Active-passive (single primary, read replicas elsewhere) is simpler. Active-active (writes in multiple regions) needs conflict resolution (last-write-wins, CRDTs) only do it when business truly requires.
- PostgreSQL options: Physical replication (byte-identical, simple DR), logical replication (selective tables/rows), bidirectional (active-active with conflict handlers).
- MongoDB options: Distributed replica sets with
readPreference: "nearest", zone sharding (data stays in region), write concerns like{ w: "majority" }. - Redis options: Redis Enterprise supports active-active with CRDTs. Open-source lacks native active-active use application-level writes to multiple instances.
- Data residency: Partition tables by region + row-level security + application routing. Never store regulated data in wrong region enforce at database and app layers.
- Failover automation: Health checks → update DNS (low TTL) → promote replica → quarterly drills.
- Cost optimization: Asymmetric deployments (full capacity in primary, minimal in secondary), compress replication traffic (gzip 60-80% reduction), replicate only necessary data, storage tiering.
Distributing data across geographic regions improves resilience, reduces latency for global users, and ensures compliance with data sovereignty regulations. Multi-region architectures introduce complexity around consistency, replication lag, failover procedures, and cost management. Understanding trade-offs between consistency models and performance characteristics enables informed architecture decisions.
Why Multi-Region Data Architecture
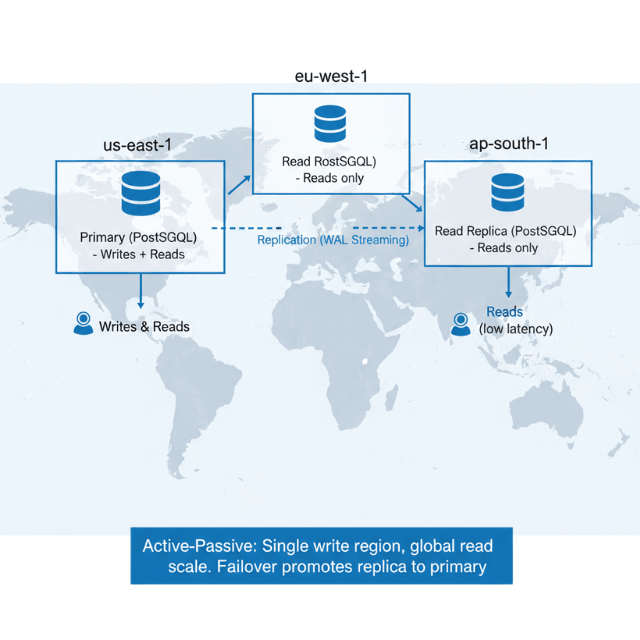
Disaster recovery protects against regional failures. Cloud provider outages affecting entire regions occur periodically. Multi-region deployment ensures business continuity when primary regions experience problems.
Performance optimization reduces latency for geographically distributed users. Serving data from nearby regions decreases response times from hundreds of milliseconds to tens of milliseconds. This improvement significantly impacts user experience for latency-sensitive applications.
Regulatory compliance requires data residency in specific jurisdictions. GDPR mandates European user data storage in EU regions. Similar regulations exist globally. Multi-region architecture enables compliance while maintaining global service availability.
High availability exceeds what single regions provide. Regional deployments typically achieve 99.9% availability. Multi-region active-active configurations can reach 99.99% or higher through redundancy and automated failover.
PostgreSQL Multi-Region Replication
PostgreSQL supports multiple replication strategies for multi-region deployments. Each approach balances consistency, performance, and complexity differently.
Physical replication streams Write-Ahead Log (WAL) files from primary to standby instances. This provides byte-level identical replicas suitable for disaster recovery.
# Primary PostgreSQL cluster in us-east-1
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgres-us-east
namespace: production
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:15.5
storage:
size: 500Gi
storageClass: fast-ssd
postgresql:
parameters:
max_connections: "500"
wal_keep_size: "8GB"
max_wal_senders: "10"
max_replication_slots: "10"
backup:
barmanObjectStore:
destinationPath: s3://postgres-backups-us-east-1/primary
s3Credentials:
accessKeyId:
name: s3-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: s3-creds
key: SECRET_ACCESS_KEY
wal:
compression: gzip
maxParallel: 4
retentionPolicy: "30d"
---
# Replica cluster in eu-west-1
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgres-eu-west
namespace: production
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:15.5
replica:
enabled: true
source: postgres-us-east
externalClusters:
- name: postgres-us-east
connectionParameters:
host: postgres-us-east-rw.production.svc.cluster.local
user: streaming_replica
dbname: postgres
password:
name: replica-creds
key: password
Logical replication selectively replicates specific tables or databases. This enables filtering data by region, supporting multi-tenant architectures with data isolation requirements.
-- On primary database (us-east-1)
CREATE PUBLICATION us_to_eu FOR TABLE
users WHERE (region = 'eu'),
orders WHERE (shipping_region = 'eu'),
products; -- All products replicated
-- On replica database (eu-west-1)
CREATE SUBSCRIPTION eu_from_us
CONNECTION 'host=postgres-us-east.example.com port=5432 dbname=production user=replicator password=secret sslmode=require'
PUBLICATION us_to_eu
WITH (copy_data = true, synchronous_commit = 'local');
-- Monitor replication lag
SELECT
subscription_name,
received_lsn,
latest_end_lsn,
last_msg_send_time,
last_msg_receipt_time,
latest_end_time
FROM pg_stat_subscription;
Bidirectional replication enables active-active configurations where both regions accept writes. This requires conflict resolution strategies.
-- Configure conflict resolution
ALTER SUBSCRIPTION eu_from_us SET (origin = 'any');
ALTER SUBSCRIPTION us_from_eu SET (origin = 'any');
-- Use last-write-wins with timestamps
CREATE OR REPLACE FUNCTION resolve_conflict()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.updated_at > OLD.updated_at THEN
RETURN NEW;
ELSE
RETURN OLD;
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER conflict_resolution
BEFORE UPDATE ON users
FOR EACH ROW EXECUTE FUNCTION resolve_conflict();
MongoDB Multi-Region Clusters
MongoDB's replica sets and sharded clusters provide built-in multi-region support with configurable read preferences and write concerns.
Geographically distributed replica sets place replicas across regions with priority-based elections ensuring specific regions host the primary.
apiVersion: mongodbcommunity.mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: global-mongodb
spec:
members: 5
type: ReplicaSet
version: "6.0.5"
additionalMongodConfig:
replication.enableMajorityReadConcern: true
statefulSet:
spec:
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: global-mongodb
topologyKey: topology.kubernetes.io/zone
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/region
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: global-mongodb
Configuration in replica set:
// MongoDB replica set configuration
rs.initiate({
_id: "globalRS",
members: [
{ _id: 0, host: "mongo-0.us-east.example.com:27017", priority: 2 },
{ _id: 1, host: "mongo-1.us-east.example.com:27017", priority: 1 },
{ _id: 2, host: "mongo-2.eu-west.example.com:27017", priority: 1 },
{ _id: 3, host: "mongo-3.eu-west.example.com:27017", priority: 0.5 },
{ _id: 4, host: "mongo-4.ap-south.example.com:27017", priority: 0.5 }
]
});
// Configure read preferences for local reads
db.products.find().readPref("nearest");
// Configure write concern for durability
db.orders.insertOne(
{ customer: "user123", total: 99.99 },
{ writeConcern: { w: "majority", j: true, wtimeout: 5000 } }
);
Zone sharding distributes data based on geographic location.
// Enable sharding
sh.enableSharding("ecommerce");
// Define zones for regions
sh.addShardTag("shard-us", "us-east");
sh.addShardTag("shard-eu", "eu-west");
sh.addShardTag("shard-ap", "ap-south");
// Shard collection by user region
sh.shardCollection("ecommerce.users", { region: 1, userId: 1 });
// Create zone ranges
sh.addTagRange(
"ecommerce.users",
{ region: "us", userId: MinKey },
{ region: "us", userId: MaxKey },
"us-east"
);
sh.addTagRange(
"ecommerce.users",
{ region: "eu", userId: MinKey },
{ region: "eu", userId: MaxKey },
"eu-west"
);
sh.addTagRange(
"ecommerce.users",
{ region: "ap", userId: MinKey },
{ region: "ap", userId: MaxKey },
"ap-south"
);
Redis Multi-Region Patterns
Redis Enterprise supports active-active replication across regions. For open-source Redis, implement application-level replication or use Redis Cluster with replica migration.
Redis Cluster with cross-region replicas distributes hash slots across regions.
apiVersion: redis.redis.opstreelabs.in/v1beta1
kind: RedisCluster
metadata:
name: global-redis
spec:
clusterSize: 9 # 3 masters, 6 replicas across 3 regions
kubernetesConfig:
image: redis:7.0
redisConfig:
cluster-enabled: "yes"
cluster-node-timeout: "15000"
cluster-replica-validity-factor: "10"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: global-redis
topologyKey: topology.kubernetes.io/zone
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/region
whenUnsatisfiable: DoNotSchedule
Application-level replication writes to multiple Redis instances.
import redis
from concurrent.futures import ThreadPoolExecutor
class MultiRegionRedis:
def __init__(self):
self.clients = {
'us-east': redis.Redis(host='redis-us.example.com'),
'eu-west': redis.Redis(host='redis-eu.example.com'),
'ap-south': redis.Redis(host='redis-ap.example.com')
}
self.executor = ThreadPoolExecutor(max_workers=3)
def set(self, key, value, ttl=None):
"""Write to all regions concurrently"""
def write_region(client):
if ttl:
client.setex(key, ttl, value)
else:
client.set(key, value)
futures = [
self.executor.submit(write_region, client)
for client in self.clients.values()
]
# Wait for primary region write
futures[0].result()
return True
def get(self, key, region='us-east'):
"""Read from nearest region"""
return self.clients[region].get(key)
def get_with_fallback(self, key, preferred_region='us-east'):
"""Read with automatic fallback to other regions"""
try:
return self.clients[preferred_region].get(key)
except:
# Try other regions
for region, client in self.clients.items():
if region != preferred_region:
try:
value = client.get(key)
if value:
return value
except:
continue
return None
Data Residency and Compliance
Regulations require user data storage in specific geographic locations. Implement data partitioning by region with strict access controls.
Region-based data isolation:
-- PostgreSQL: Partition tables by region
CREATE TABLE users (
id UUID,
email VARCHAR(255),
region VARCHAR(10),
data JSONB,
created_at TIMESTAMP DEFAULT NOW()
) PARTITION BY LIST (region);
CREATE TABLE users_eu PARTITION OF users FOR VALUES IN ('eu');
CREATE TABLE users_us PARTITION OF users FOR VALUES IN ('us');
CREATE TABLE users_ap PARTITION OF users FOR VALUES IN ('ap');
-- Ensure partition constraints
ALTER TABLE users_eu ADD CONSTRAINT eu_region_check CHECK (region = 'eu');
ALTER TABLE users_us ADD CONSTRAINT us_region_check CHECK (region = 'us');
ALTER TABLE users_ap ADD CONSTRAINT ap_region_check CHECK (region = 'ap');
-- Row-level security for region isolation
CREATE POLICY region_isolation ON users
USING (region = current_setting('app.user_region'));
ALTER TABLE users ENABLE ROW LEVEL SECURITY;
Application-level region routing:
class RegionRouter:
def __init__(self):
self.db_connections = {
'us': get_db_connection('postgres-us.example.com'),
'eu': get_db_connection('postgres-eu.example.com'),
'ap': get_db_connection('postgres-ap.example.com')
}
def get_user_connection(self, user_id):
"""Route to appropriate region based on user data"""
# Lookup user region from metadata service
user_region = self.lookup_user_region(user_id)
return self.db_connections[user_region]
def create_user(self, user_data, region):
"""Create user in appropriate regional database"""
conn = self.db_connections[region]
# Set region context
conn.execute("SET app.user_region = %s", (region,))
# Insert user data
conn.execute(
"INSERT INTO users (id, email, region, data) "
"VALUES (%s, %s, %s, %s)",
(user_data['id'], user_data['email'], region, user_data)
)
conn.commit()
Handling Failover Scenarios
Automated failover ensures continuity when primary regions fail.
DNS-based failover redirects traffic to healthy regions.
# External DNS configuration for multi-region routing
apiVersion: v1
kind: Service
metadata:
name: api-global
annotations:
external-dns.alpha.kubernetes.io/hostname: api.example.com
external-dns.alpha.kubernetes.io/ttl: "60"
external-dns.alpha.kubernetes.io/policy: latency
external-dns.alpha.kubernetes.io/set-identifier: us-east-1
spec:
type: LoadBalancer
selector:
app: api
ports:
- port: 443
targetPort: 8080
Health check based promotion:
class FailoverManager:
def __init__(self):
self.regions = ['us-east', 'eu-west', 'ap-south']
self.primary_region = 'us-east'
def check_region_health(self, region):
"""Check database and application health"""
try:
db = get_db_connection(region)
db.execute("SELECT 1")
api = requests.get(f"https://{region}.example.com/health")
return api.status_code == 200
except:
return False
def perform_failover(self, failed_region):
"""Promote secondary region to primary"""
healthy_regions = [
r for r in self.regions
if r != failed_region and self.check_region_health(r)
]
if not healthy_regions:
raise NoHealthyRegionsError()
new_primary = healthy_regions[0]
# Update DNS records
update_dns_records(new_primary)
# Promote database replica
promote_database_replica(new_primary)
# Update application configuration
update_app_config(primary_region=new_primary)
self.primary_region = new_primary
logger.info(f"Failover complete: {failed_region} -> {new_primary}")
Failover Automation Looks Complex? We've Built It Dozens of Times.
The failover code above works. But production-ready multi-region requires:
- Health check tuning – Avoiding false positives that trigger unnecessary failover
- Stateful failover – Preserving transaction integrity during region
- Observability – Correlation across regions (metrics, logs, traces)
- Regular drills – Quarterly failover testing you'll actually run
We help startups implement active-passive (and active-active) multi-region architectures.
Cost Optimization
Multi-region deployments increase infrastructure costs. Strategic optimizations reduce expenses while maintaining resilience.
- Asymmetric deployments - Run full capacity in primary regions with smaller standby capacity in secondary regions. Scale secondary only during failover events
- Compress replication traffic - Reduce cross-region data transfer costs
- Replicate only necessary data - Use logical filtering to minimize replication volume
- Storage tiering - Keep hot data in expensive low-latency storage, archive cold data to cheaper regional storage
# S3 Intelligent-Tiering for backups
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: production-postgres
spec:
backup:
barmanObjectStore:
destinationPath: s3://postgres-backups/prod
s3Credentials:
accessKeyId:
name: s3-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: s3-creds
key: SECRET_ACCESS_KEY
data:
compression: gzip
wal:
compression: gzip
retentionPolicy: "30d"
- Read replicas - Serve read traffic locally while writes route to primary region, reducing cross-region traffic for read-heavy workloads
Monitoring Multi-Region Systems
Observability across regions requires correlation of metrics, logs, and traces.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: multi-region-alerts
spec:
groups:
- name: replication
interval: 30s
rules:
- alert: HighReplicationLag
expr: |
pg_replication_lag_seconds > 300
for: 5m
labels:
severity: warning
annotations:
summary: "Replication lag exceeds 5 minutes"
- alert: ReplicationBroken
expr: |
up{job="postgres-replica"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Replication connection down"
- alert: RegionFailure
expr: |
up{region=~".*"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Entire region unhealthy"
Multi-region data management balances availability, performance, compliance, and cost. Architect systems thoughtfully based on business requirements, user distribution, and regulatory constraints. Start simple with active-passive configurations before introducing active-active complexity. Test failover procedures regularly to ensure they work when needed.
Conclusion
Multi-region data management is the price of global scale and enterprise resilience. The complexity is real consistency tradeoffs, replication lag, failover automation, and compliance enforcement but so are the benefits: users everywhere experience fast responses, regional outages become survivable, and regulators stay satisfied. The key is matching architecture to actual requirements.
Most applications don't need active-active writes; active-passive with local read replicas provides excellent performance and simpler failover. Use PostgreSQL's logical replication for selective data distribution, MongoDB's zone sharding for geographic partitioning, and Redis Enterprise or application-level replication for caching across regions.
Automate failover, test it quarterly, and monitor replication lag aggressively. And always, always respect data residency partition, route, and enforce at the database level. The investment in multi-region pays off when your primary region goes dark and your users never notice.
Frequently Asked Questions
1. Active-active vs. active-passive: which to choose?
Start with active-passive. Only choose active-active if:
- You need writes accepted in multiple regions simultaneously (e.g., APAC users can't tolerate 200ms latency to US primary)
- You're willing to handle conflict resolution. Active-active complexity is significant test thoroughly in staging.
2. How to handle GDPR data residency?
Three-layer enforcement:
- Database partitioning –
PARTITION BY LISTto prevent cross-region mixing. - Row-level security – enforce region isolation at query time.
- Application routing – look up user region, route to correct database connection.
Never rely solely on app logic defense in depth with database constraints.
3. What's the cost impact?
| Cost Factor | Example / Rate |
|---|---|
| Cross-region transfer | ~$0.02/GB |
| 1TB database transfer cost | ~$20/month just in transfer (plus storage, compute, overhead) |
| Compression savings | gzip reduces 60-80% of transfer data |
| Batch replication | Many apps tolerate 5-minute RPO; batch instead of continuous streaming dramatically cuts costs |
Summarize this post with:
