Implementing Site Reliability Engineering
Learn how to implement Site Reliability Engineering (SRE) for cloud-native systems. Master SLOs and error budgets, observability pillars, chaos engineering, and automation to balance innovation with reliability.

TL;DR
- SRE balances velocity and stability using error budgets—a quantifiable allowance for unreliability based on your SLOs (Service Level Objectives). This replaces subjective debates with data-driven decisions on when to deploy or freeze releases.
- Observability is your foundation: You need the three pillars—metrics (Prometheus), logs, and distributed tracing (Jaeger)—to measure SLOs, debug microservices, and understand system behavior. Without it, you're flying blind.
- Proactively find weaknesses with chaos engineering: Use tools like LitmusChaos or Chaos Mesh to intentionally inject failures (pod kills, network latency) in a controlled way. This uncovers vulnerabilities before they cause customer-facing outages.
- Automate everything possible: Eliminate manual toil by adopting GitOps (ArgoCD, Flux) for deployments and using Kubernetes operators for application management. Aim for self-healing systems where auto-scaling and auto-remediation are the norm.
Site Reliability Engineering for cloud native environments combines software engineering practices with infrastructure management to create scalable, reliable platforms.
As organizations embrace containerization, microservices, and Kubernetes, SRE has transformed from reactive firefighting to proactive reliability design.
This guide covers SLOs and error budgets, observability, chaos engineering, automation, and best practices that enable modern SRE teams to balance development velocity with system stability.
Understanding Cloud-Native SRE
Cloud native SRE applies software engineering practices to infrastructure and operations with the primary goal of creating scalable and highly reliable platforms without manual intervention. The discipline originated at Google and has become essential for organizations running containerized workloads on Kubernetes and managing microservices architectures.
Core principles include treating reliability as a feature not an afterthought, using error budgets to balance innovation velocity with stability, automating operations to eliminate manual toil, and designing systems for failure from inception. Cloud native SRE operates on immutable infrastructure, declarative APIs, automated remediation, and continuous validation.
The shift from traditional operations to cloud native SRE reflects fundamental changes. Traditional operations focused on maximizing uptime through change control and manual runbooks. Cloud native SRE embraces frequent deployments using error budgets to balance innovation and reliability. Services are designed to fail gracefully with circuit breakers, retry logic, and fallback mechanisms.
Key differences include dynamic infrastructure where containers are ephemeral and services scale automatically versus static on-premises servers, observability versus monitoring, and automated response versus manual intervention. Cloud native SRE teams work with abstractions like pods, services, and ingress controllers rather than physical servers.
Service Level Objectives and Error Budgets
Service Level Indicators quantitatively measure service behavior that matters to users. In cloud native environments, SLIs typically measure availability, latency, throughput, and error rates across distributed microservices. Effective SLIs focus on user experience rather than internal system metrics.
Service Level Objectives set target values for SLIs over specific time windows. An SLO might specify that 99.9% of API requests should complete within 200ms over a rolling 30-day window. SLOs represent contracts between service providers and consumers, balancing reliability requirements with the cost of achieving extreme availability. In microservices, SLOs must account for error propagation where Service A depending on Service B cannot exceed Service B's SLO.
Error budgets quantify how unreliable a service can be within its SLO targets. If your SLO specifies 99.9% availability, your error budget is 0.1% downtime, approximately 43 minutes per month. This concept transforms reliability from a binary goal into a quantifiable resource that teams can spend on innovation.
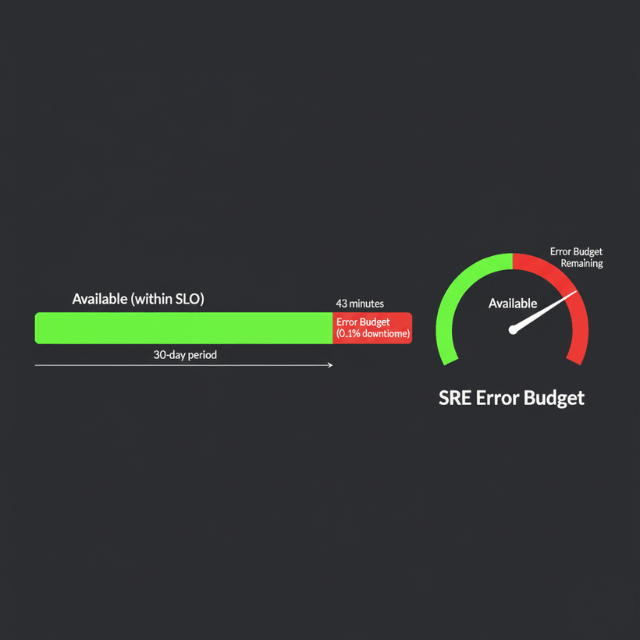
Implementation requires automated tracking and enforcement. Modern SRE platforms integrate with observability tools to continuously measure SLI compliance, calculate error budget consumption, and trigger policy actions when thresholds are exceeded. Policies might include requiring additional testing before deployments, implementing deployment freezes, or automatically rolling back changes degrading reliability.
Error budget policies create healthy tension between development velocity and system stability. Rather than subjective arguments about whether a release is too risky, teams have objective data about current reliability and remaining error budget. When services consistently meet SLOs with error budget to spare, teams might consider loosening SLOs to enable faster iteration.
Building Observability for Cloud-Native Systems
The three pillars provide complementary perspectives on system behavior. Metrics provide high-level quantitative data about resource utilization, request rates, error rates, and latency distributions.
Logs capture detailed event information from applications, infrastructure, and platform components. Distributed tracing tracks requests as they flow through microservices, revealing dependencies and latency contributions.
Building observability pipelines requires collecting, processing, and routing telemetry from distributed sources to appropriate storage and analysis. Pipelines must handle high data volumes, support multiple data types, enable real-time processing, and provide reliability guarantees. Modern pipelines use agents deployed as Kubernetes DaemonSets collecting data close to sources.
Prometheus and Grafana form the foundation of cloud native observability. Prometheus provides metrics collection with its pull-based model and dimensional data model. Grafana provides visualization and dashboarding supporting multiple backends. Pre-built dashboards for Kubernetes components speed up implementation.
Distributed tracing with Jaeger provides end-to-end visibility into request flows across microservices. It supports OpenTelemetry standards, making it compatible with most instrumentation libraries. Integration with service meshes automatically generates traces without requiring application code changes.
Chaos Engineering
Chaos engineering validates system resilience by intentionally introducing controlled failures. The practice emerged from Netflix's recognition that complex distributed systems will fail in unpredictable ways, and the best defense is discovering vulnerabilities before they cause outages.
Principles include starting small with limited blast radius, automating experiments to run continuously, and limiting impact on customers. Experiments should be reversible with clear rollback procedures. Results should be captured and analyzed to drive concrete improvements.
Kubernetes chaos experiments test whether applications properly handle pod restarts, node failures, network partitions, resource constraints, and platform-level disruptions. LitmusChaos provides a library of pre-defined experiments including pod deletion, node drain, network latency injection, and resource exhaustion. Chaos Mesh provides chaos experiments for Kubernetes with web UI simplifying experiment creation.
Implementation requires careful planning. Start by identifying critical user journeys and mapping them to underlying services. Design experiments testing assumptions about resilience. Establish clear success criteria and monitoring to detect when experiments cause excessive impact. Use pod disruption budgets and resource quotas to limit blast radius.
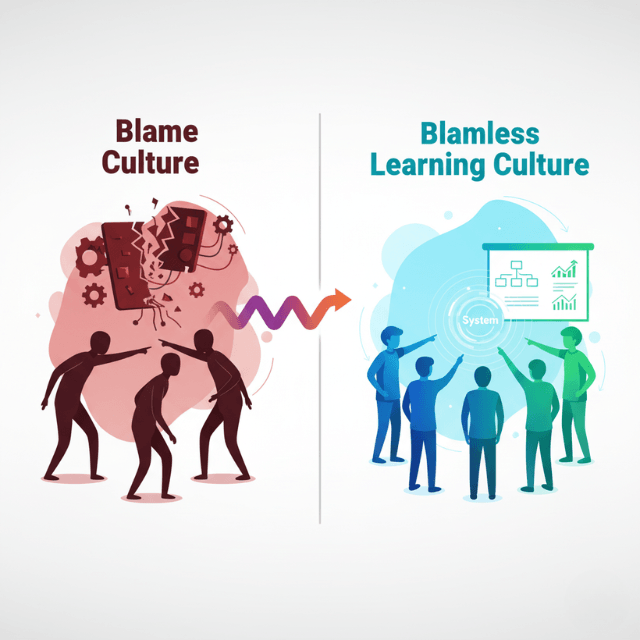
Best practices include obtaining organizational buy-in, beginning with observability to establish baselines, starting small with limited blast radius, automating experiments to run regularly, and sharing results broadly to drive improvements. Create a blameless culture where discovering weaknesses is celebrated. Chaos engineering should become standard practice, not a one-time project.
Automation and AIOps
Automating toil represents manual, repetitive, automatable work providing no enduring value. Google's SRE principles suggest SREs should spend no more than 50% of their time on toil. Kubernetes operators provide a powerful framework for automating operational knowledge, extending Kubernetes with custom resources and controllers managing complex applications.
GitOps workflows automate infrastructure and application management through Git-based workflows. Tools like ArgoCD and Flux continuously reconcile cluster state with declarative configurations stored in Git. Changes go through code review, testing, and approval before merging. After merge, GitOps controllers automatically apply changes to clusters.
AI and machine learning transform SRE practices by enabling automation of tasks requiring human intelligence. Anomaly detection uses machine learning to identify unusual patterns in metrics, logs, and traces. Traditional threshold-based alerting generates false positives, while ML-based anomaly detection learns normal patterns and detects statistical deviations.
Automated incident response systems use AI to diagnose problems and execute remediation procedures. When alerts fire, AI systems analyze symptoms, consult runbooks, execute diagnostic commands, correlate with similar historical incidents, and recommend or automatically execute fixes.
Self-healing systems automatically detect failures, diagnose root causes, and execute remediation without human intervention. Kubernetes restarts crashed containers, reschedules pods from failed nodes, and replaces unhealthy instances. Service meshes implement circuit breakers, automatic retries, and request timeouts.
Capacity Planning and Resource Optimization
Right-sizing workloads balances performance, reliability, and cost. Kubernetes resource requests specify minimum resources that must be available for pod scheduling. Limits define maximum consumption. Setting these values requires analyzing historical usage data using tools like Vertical Pod Autoscaler.
Horizontal Pod Autoscaler adjusts replica counts based on observed metrics like CPU utilization, memory usage, or custom application metrics. HPA continuously monitors target metrics and scales deployments up or down to maintain configured targets. Custom metrics enable sophisticated autoscaling beyond CPU and memory alone.
Cluster autoscaling adjusts node counts based on pod scheduling needs. When pods cannot be scheduled due to insufficient resources, cluster autoscaler provisions additional nodes. When nodes are underutilized, it safely drains and removes them, reducing costs.
Cost optimization in multi-cloud environments provides resilience and avoids vendor lock-in but introduces complexity in cost management. Reserved instances and committed use discounts provide 30-70% savings for predictable workloads. Spot instances and preemptible VMs offer 50-90% discounts for interruptible workloads.
Incident Management and On-Call
Incident response processes balance rapid response with thorough investigation and communication. Roles include incident commander coordinating response, communications lead updating stakeholders, technical lead guiding investigation, and subject matter experts providing domain expertise.
Severity classification helps teams prioritize responses. SEV-1 incidents cause complete service outages or severe degradation affecting many customers, requiring immediate all-hands response. SEV-2 incidents impact functionality but have workarounds. SEV-3 incidents involve minor issues handled through normal support.
Blameless postmortems transform incidents into learning opportunities. Rather than seeking individuals to blame, postmortems examine system factors enabling failures. Detailed timelines reconstruct events. Root cause analysis identifies underlying issues, not just proximate causes. Action items specify concrete improvements tracked to completion.
Sustainable on-call practices balance reliability needs with engineer wellbeing. Primary/secondary rotations ensure backup coverage. Follow-the-sun rotations distribute on-call across global teams, reducing nighttime pages. Alert hygiene dramatically impacts on-call quality of life through actionable, urgent, and real alerts.
Security and Compliance Integration
Security best practices implement defense in depth across multiple layers. Container images must be scanned for vulnerabilities. Kubernetes provides security controls including Pod Security Standards enforcing security restrictions, network policies controlling pod-to-pod communication, and RBAC controlling access to APIs.
Service mesh security provides encryption, authentication, and authorization at the service-to-service communication level. Mutual TLS encrypts traffic and verifies both client and server identities. Service meshes can enforce fine-grained authorization policies controlling which services can communicate and what operations they can perform.
Runtime security monitoring detects anomalous behavior in production. Tools like Falco use kernel-level instrumentation to detect suspicious activity including unexpected process execution, file system modifications, network connections to unusual destinations, and privilege escalations.
Compliance frameworks impose specific controls on data handling, availability maintenance, and security demonstration. SRE teams play critical roles in implementing these controls. Policy-as-code tools like Open Policy Agent enforce compliance requirements programmatically, preventing non-compliant configurations from reaching production.
Conclusion
Cloud native Site Reliability Engineering transforms reliability from reactive operations into proactive design. Service Level Objectives and error budgets balance innovation velocity with system stability through objective, data-driven decisions. Observability provides visibility essential for understanding distributed system behavior. Chaos engineering validates resilience before failures impact users.
Automation eliminates toil, enabling small teams to manage large, complex environments. AI and machine learning increasingly augment human capabilities through anomaly detection, intelligent alerting, and automated remediation. Self-healing systems automatically recover from common failures without human intervention.
Success requires both technical mastery and cultural transformation. Teams must embrace declarative thinking, automated operations, and continuous delivery. Security must be embedded throughout, not bolted on. Blameless postmortems enable learning from failures without fear.
Organizations mastering cloud native SRE gain competitive advantages through faster delivery, improved reliability, better capacity planning, and superior user experiences. The journey to SRE maturity is continuous, but the operational benefits justify the investment.
FAQs
What's the difference between SLOs, SLIs, and error budgets?
SLIs (Service Level Indicators) are the specific metrics you measure, like request latency or error rate. An SLO (Service Level Objective) is your target value for that metric, e.g., "99.9% of requests complete under 200ms."
The error budget is the allowable margin of failure (the 0.1% or ~43 minutes of downtime per month) before you breach your SLO. You can "spend" this budget on risky deployments.
How is chaos engineering different from just testing?
Standard testing (like unit or integration tests) validates that the system works as expected under known conditions.
Chaos engineering tests how the system behaves under unexpected, real-world failure conditions—like a sudden network partition or a slow database. It's about discovering the unknown weaknesses in your distributed system's resilience.
What's the first step for a team new to SRE?
Start with measurement. You cannot improve what you don't measure. Begin by defining a single, simple SLO for a critical user journey (e.g., "checkout flow latency").
Instrument your system to collect that SLI using tools like Prometheus. Once you have data, you can establish a baseline, set a realistic SLO, and start tracking your error budget.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.