Event-Driven Architecture
Master event-driven architecture with Apache Kafka, RabbitMQ, event sourcing, CQRS, and saga patterns. Learn implementation patterns with production-ready code examples.

TL;DR
- Events as the backbone: EDA uses events (state changes) for service communication. Services publish events without knowing consumers—creating loose coupling, independent scaling, and real-time responsiveness. Companies like Uber (1 trillion events/day) and Netflix (700 billion/day) run on EDA.
- Apache Kafka for high-throughput streaming: Kafka provides durable, distributed event storage with horizontal scaling. Use it for event sourcing, stream processing, and multi-service event distribution. Consumer groups enable parallel processing with exactly-once semantics.
- Event sourcing + CQRS for auditability: Store all state changes as immutable events (event sourcing). Reconstruct current state by replaying events. Combine with CQRS—separate write (commands) and read (queries) models—for independent optimization and scaling.
- Sagas for distributed transactions: Coordinate multi-service operations without distributed locks. Each service performs local transactions and publishes events. If any step fails, execute compensating transactions (e.g., release inventory if payment fails). Essential for order processing, travel bookings, etc.
- Monitor everything critical: Track consumer lag, processing latency, error rates, and dead letter queues. Use correlation IDs for distributed tracing. Set alerts for lag spikes—they're the first sign of trouble.
Applications built on event-driven architecture respond to state changes as they happen, processing information asynchronously through message brokers and event streams. This architectural pattern enables loose coupling between services, allowing independent scaling and deployment while maintaining real-time responsiveness.
Organizations using event-driven architectures report 60% faster feature delivery and 45% reduction in system downtime according to 2024 Gartner research. Companies like Uber process 1 trillion events daily using Kafka, while Netflix handles 700 billion events per day across their streaming platform.
This guide demonstrates how to design and implement event-driven systems using Apache Kafka, RabbitMQ, event sourcing patterns, CQRS, and saga orchestration with production-ready code examples.
Event-Driven Architecture Fundamentals
Event-driven architecture relies on events as the primary mechanism for communication between system components.
An event represents a state change or occurrence in the system, such as user registration, order placement, or sensor reading. Services publish events to message brokers without knowing which consumers will process them, creating loose coupling.
Apache Kafka provides distributed streaming with multi-terabyte retention, processing millions of events per second. RabbitMQ offers flexible routing with multiple messaging patterns including publish-subscribe and work queues.
AWS EventBridge connects AWS services through event-driven integration. Financial services use complex event processing to detect fraud by correlating transaction events across accounts, identifying suspicious patterns within milliseconds.
CloudEvents standardizes event format across platforms and languages. The specification defines required fields including event type, source, subject, and data schema.
{
"specversion": "1.0",
"type": "com.example.order.created",
"source": "https://api.example.com/orders",
"id": "A234-1234-1234",
"time": "2025-01-15T10:30:00Z",
"datacontenttype": "application/json",
"data": {
"orderId": "ORD-2025-001234",
"customerId": "CUST-789456",
"totalAmount": 299.99,
"currency": "EUR",
"items": [
{"productId": "PROD-456", "quantity": 2, "price": 149.99}
]
}
}
Apache Kafka Implementation
Apache Kafka provides distributed event streaming with horizontal scalability and durable storage. Topics organize events into categories, with partitions enabling parallel processing.
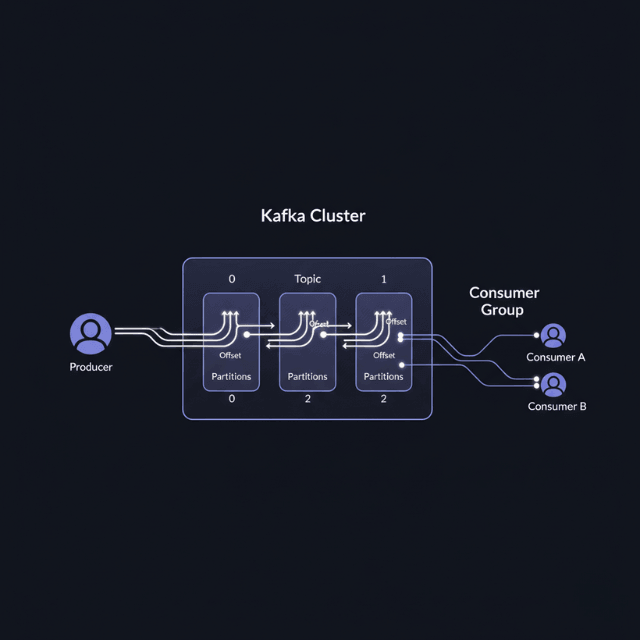
Producers publish events to topics, while consumers read events from subscribed topics. Consumer groups allow multiple instances to process events in parallel, with Kafka ensuring each partition is consumed by only one instance in the group.
"""
Apache Kafka producer and consumer implementation
Prerequisites:
- Kafka cluster running (localhost:9092)
- pip install confluent-kafka
"""
from confluent_kafka import Producer, Consumer, KafkaError
import json
import logging
from datetime import datetime
from typing import Dict, List
import uuid
logger = logging.getLogger(__name__)
class EventProducer:
def __init__(self, bootstrap_servers: str = 'localhost:9092'):
"""Initialize Kafka producer with reliability settings"""
self.config = {
'bootstrap.servers': bootstrap_servers,
'client.id': 'event-producer-001',
'acks': 'all',
'retries': 10,
'compression.type': 'snappy',
'linger.ms': 10,
'batch.size': 32768
}
self.producer = Producer(self.config)
def publish_event(self, topic: str, event_type: str,
event_data: Dict, key: str = None) -> str:
"""Publish CloudEvents-compliant event to Kafka topic"""
event_id = str(uuid.uuid4())
cloud_event = {
'specversion': '1.0',
'type': event_type,
'source': 'order-service',
'id': event_id,
'time': datetime.utcnow().isoformat() + 'Z',
'datacontenttype': 'application/json',
'data': event_data
}
self.producer.produce(
topic=topic,
key=key.encode('utf-8') if key else None,
value=json.dumps(cloud_event).encode('utf-8'),
callback=self._delivery_callback
)
self.producer.poll(0)
logger.info(f"Published event {event_id} to topic {topic}")
return event_id
def _delivery_callback(self, err, msg):
"""Handle delivery report from Kafka broker"""
if err:
logger.error(f"Event delivery failed: {err}")
else:
logger.info(f"Event delivered to {msg.topic()} "
f"partition {msg.partition()}")
class EventConsumer:
def __init__(self, bootstrap_servers: str = 'localhost:9092',
group_id: str = 'event-consumer-group'):
"""Initialize Kafka consumer with consumer group"""
self.config = {
'bootstrap.servers': bootstrap_servers,
'group.id': group_id,
'auto.offset.reset': 'earliest',
'enable.auto.commit': False
}
self.consumer = Consumer(self.config)
def subscribe_and_process(self, topics: List[str], handler_function):
"""Subscribe to topics and process events"""
self.consumer.subscribe(topics)
while True:
msg = self.consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() != KafkaError._PARTITION_EOF:
logger.error(f"Consumer error: {msg.error()}")
else:
event = json.loads(msg.value().decode('utf-8'))
handler_function(event)
self.consumer.commit(asynchronous=False)
# Example usage
producer = EventProducer()
order_data = {
'orderId': 'ORD-2025-001234',
'customerId': 'CUST-789456',
'totalAmount': 299.99,
'items': [{'productId': 'PROD-456', 'quantity': 2, 'price': 149.99}]
}
producer.publish_event(
topic='order-events',
event_type='com.example.order.created',
event_data=order_data,
key=order_data['customerId']
)
Kafka Streams enables stateful stream processing with aggregations, joins, and windowing operations. E-commerce platforms use this to calculate real-time inventory levels by aggregating purchase and restock events.
Event Sourcing and CQRS Patterns
Event sourcing stores all state changes as a sequence of events rather than persisting current state directly. Applications reconstruct current state by replaying events from the event store. This provides complete audit history, temporal queries, and the ability to rebuild state at any point in time.
"""
Event sourcing and CQRS implementation
"""
from dataclasses import dataclass, field
from datetime import datetime
from typing import List, Dict
from enum import Enum
class OrderEventType(Enum):
ORDER_CREATED = "order.created"
ITEM_ADDED = "order.item.added"
PAYMENT_RECEIVED = "order.payment.received"
ORDER_SHIPPED = "order.shipped"
@dataclass
class Event:
event_id: str
event_type: OrderEventType
aggregate_id: str
timestamp: datetime
data: Dict
version: int
@dataclass
class Order:
"""Order aggregate reconstructed from events"""
order_id: str
customer_id: str
items: List[Dict] = field(default_factory=list)
total_amount: float = 0.0
status: str = "CREATED"
version: int = 0
def apply_event(self, event: Event):
"""Apply event to update order state"""
if event.event_type == OrderEventType.ORDER_CREATED:
self.customer_id = event.data['customer_id']
self.status = "CREATED"
elif event.event_type == OrderEventType.ITEM_ADDED:
self.items.append(event.data['item'])
self.total_amount += (event.data['item']['price'] *
event.data['item']['quantity'])
elif event.event_type == OrderEventType.PAYMENT_RECEIVED:
self.status = "PAID"
elif event.event_type == OrderEventType.ORDER_SHIPPED:
self.status = "SHIPPED"
self.version = event.version
class EventStore:
"""In-memory event store for demonstration"""
def __init__(self):
self.events: Dict[str, List[Event]] = {}
def append_event(self, event: Event):
"""Append event to event stream for aggregate"""
if event.aggregate_id not in self.events:
self.events[event.aggregate_id] = []
self.events[event.aggregate_id].append(event)
def reconstruct_aggregate(self, aggregate_id: str) -> Order:
"""Reconstruct order aggregate from event stream"""
events = self.events.get(aggregate_id, [])
if not events:
raise ValueError(f"No events for order {aggregate_id}")
order = Order(
order_id=aggregate_id,
customer_id=events[0].data['customer_id']
)
for event in events:
order.apply_event(event)
return order
# Create event store and events
event_store = EventStore()
create_event = Event(
event_id="evt-001",
event_type=OrderEventType.ORDER_CREATED,
aggregate_id="ORD-2025-001234",
timestamp=datetime.utcnow(),
data={'customer_id': 'CUST-789456'},
version=1
)
event_store.append_event(create_event)
# Reconstruct order from events
order = event_store.reconstruct_aggregate("ORD-2025-001234")
CQRS separates read and write operations into different models. Commands modify state through the write model, generating events. Queries read from optimized read models updated by event handlers.
This enables independent scaling of reads and writes with different data stores optimized for each workload. Social media platforms use CQRS to handle billions of read operations while maintaining consistency for updates.
Saga Pattern for Distributed Transactions
Sagas manage distributed transactions across multiple services using event-driven coordination. Each service performs local transactions and publishes events, with compensating transactions handling failures.
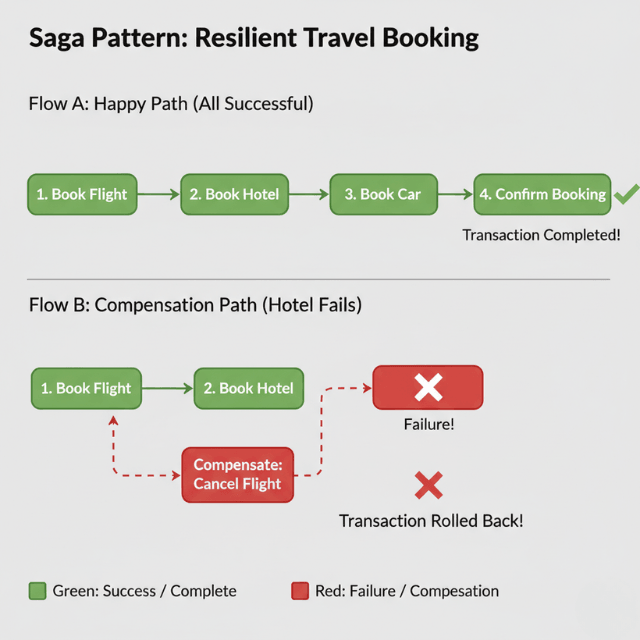
Travel booking systems use sagas to coordinate flight, hotel, and car rental reservations. If hotel booking fails after flight confirmation, compensating transactions cancel the flight, maintaining consistency without distributed locks.
"""
Saga pattern implementation for order processing
"""
class OrderSaga:
def __init__(self, event_publisher: EventProducer):
self.publisher = event_publisher
self.saga_state = {}
def start_order_saga(self, order_id: str, order_data: Dict):
"""Start order processing saga"""
self.saga_state[order_id] = {
'step': 'reserve_inventory',
'compensations': []
}
# Step 1: Reserve inventory
self.publisher.publish_event(
topic='inventory-commands',
event_type='inventory.reserve',
event_data={'order_id': order_id, 'items': order_data['items']},
key=order_id
)
def handle_inventory_reserved(self, event: Dict):
"""Handle inventory reservation success"""
order_id = event['data']['order_id']
# Record compensation
self.saga_state[order_id]['compensations'].append(
{'action': 'release_inventory', 'data': event['data']}
)
# Step 2: Process payment
self.publisher.publish_event(
topic='payment-commands',
event_type='payment.process',
event_data={'order_id': order_id},
key=order_id
)
def handle_payment_failed(self, event: Dict):
"""Handle payment failure - run compensations"""
order_id = event['data']['order_id']
# Execute compensating transactions in reverse order
for compensation in reversed(self.saga_state[order_id]['compensations']):
if compensation['action'] == 'release_inventory':
self.publisher.publish_event(
topic='inventory-commands',
event_type='inventory.release',
event_data=compensation['data'],
key=order_id
)
Monitoring and Troubleshooting
Monitor event processing latency by tracking time between publication and consumption. Kafka consumers expose lag metrics showing how far behind consumers are from the latest offset. Set alerts when lag exceeds thresholds, indicating bottlenecks or failures.
Track event processing success rates and error patterns. Dead letter queues capture failed events for investigation and replay. Distributed tracing correlates events across service boundaries using correlation IDs for end-to-end visibility.
Monitor broker health including CPU usage, disk I/O, and network throughput. Kafka cluster under-replication indicates broker failures. RabbitMQ queue depth shows message backlog requiring additional consumers.
Common issues include consumer lag, message ordering problems, and duplicate processing. Scale consumer groups to reduce lag. Use partition keys to maintain ordering. Implement idempotent consumers to handle duplicates safely.
Optimization and Best Practices
Start with simple pub-sub patterns before adopting event sourcing and CQRS. Use message compression to reduce network bandwidth and storage costs. Configure retention policies based on replay requirements and compliance needs.
Implement circuit breakers to prevent cascading failures. Use exponential backoff for retry logic. Monitor consumer group rebalances and optimize partition counts for parallelism.
Design events as immutable facts about what happened, not commands. Include sufficient context in events for independent processing. Version event schemas to handle evolution without breaking consumers. Test failure scenarios including broker outages and network partitions.
Implement dashboards showing event throughput, consumer lag, error rates, and processing latency. Set alerts for high lag, low throughput, and increased error rates. Document event schemas and maintain a catalog of events.
Conclusion
Event-driven architecture enables scalable, loosely coupled systems that respond to state changes in real time. Apache Kafka provides robust event streaming with durability and horizontal scaling for high-throughput workloads.
Event sourcing captures complete state history as events, enabling audit trails and temporal queries. CQRS separates read and write models for independent optimization and scaling. Saga patterns coordinate distributed transactions across services without distributed locks.
Organizations implementing event-driven architectures report 60% faster feature delivery and 45% reduction in downtime. Start with simple event processing using message brokers, then adopt event sourcing and CQRS patterns as requirements evolve.
FAQs
When should I use Kafka vs. RabbitMQ?
Use Kafka for high-throughput event streaming, long-term storage, replayability, and event sourcing—ideal for audit logs, metrics, and systems processing millions of events.
Use RabbitMQ for complex routing, task distribution, and traditional message queues—better for request-reply patterns and when you need flexible routing (topic, fanout, direct). Many teams use both: RabbitMQ for command/response, Kafka for event streams.
How do I handle event schema evolution without breaking consumers?
Follow the consumer-driven contract testing approach. Use schema registries (like Confluent Schema Registry) with Avro, Protobuf, or JSON Schema.
Evolve schemas backward-compatibly: only add optional fields, never remove required ones. Version your event types (e.g., order.created.v1, order.created.v2). Test consumers against new schemas before deploying producers.
What's the downside of event sourcing?
Event sourcing adds complexity and learning curve. Querying current state requires replaying events—implement snapshots to avoid replaying entire history.
Event stores grow indefinitely; set retention policies and archive old events. It's overkill for simple CRUD apps but invaluable when you need complete audit trails, temporal queries, or complex event-driven workflows. Start with simple pub-sub; adopt event sourcing only when justified.
Summarize this post with:
Ready to put this into production?
Our engineers have deployed these architectures across 100+ client engagements — from AWS migrations to Kubernetes clusters to AI infrastructure. We turn complex cloud challenges into measurable outcomes.